В процессе разработки новой версии Oracle Database компании Oracle было важно учесть две основные тенденции современной ИТ-индустрии. Во-первых, характерную для последних лет тенденцию изменения цены и доступных объемов оперативной памяти. Ведь стоимость оперативной памяти каждый год падает на 30 %, а типовой корпоративный сервер сегодня уже поставляется с объемом памяти 128 ГБ, причем многие серверы имеют 1 ТБ памяти. Это значит, что если научиться размещать базы данных непосредственно в оперативной памяти, то запросы к ним будут выполняться в десятки и сотни раз быстрее, что открывает возможность реализации бизнес-аналитики реального масштаба времени.

Во-вторых, важно помнить о том, что в условиях снижения затрат на ИТ разработчикам нужны новые инструменты, которые позволяют быстрее внедрять инновации и упрощать поддержку приложений. Так, например, для интеграции новых разработок с существующими корпоративными инфраструктурами разработчики уходят от монолитных приложений, сложных и тяжелых в разработке, в сторону архитектуры микросервисов, т. е. приложений, представляющих собой наборы независимо развертываемых сервисов. И для работы с новой архитектурой необходимо, чтобы база данных поддерживала новые инструменты и новые методы программирования.
Все это компания Oracle учла при разработке базы данных Oracle Database 12.1.0.2. Эта статья — обзор основных нововведений этой версии.
Начнем с того, что в 2013 г. компания Oracle выпустила версию Oracle Database 12c (версия 12.1.0.1), основными достоинствами которой стали снижение стоимости хранения, высокая доступность данных, простота консолидации баз данных и защита доступа к данным.
Говоря чуть подробнее, в этой версии появилась архитектура Oracle Multitenant, которая существенно облегчает консолидацию баз данных, ускоряет развертывание баз данных и позволяет управлять многими базами данных как одним целым — вместо администрирования сотен баз данных по отдельности администратор работает с одной базой данных, управляя многими базами данных, как одной. Все это сделало версию Oracle Database 12c на момент ее выпуска самой подходящей системой управления базами данных для облачных вычислений, особенно для SaaS-приложений, где особенно актуально скоростное создание новых баз данных по требованию пользователей, которое при поддержке технологии Snapshot Cloning (тонкое клонирование) занимает несколько минут.
Кроме того, в Oracle Database 12.1.0.1 появилась автоматическая оптимизация данных, сочетающая технологию «умного сжатия», которая автоматически выявляет блоки данных, к которым редко обращались («холодные» данные), и сжимает их, и технологию автоматизации многоуровневого хранения данных, которая автоматически переносит «холодные» данные на более дешевый уровень хранения.
Еще одна новая технология Oracle Database 12c, которая называется Data Guard Far Sync, обеспечивает нулевую потерю данных на больших расстояниях и позволяет держать резервные копии баз данных на большом удалении от основной базы данных. Дополнительный специальный экземпляр базы данных, не имеющий файлов данных, принимает изменения от основной базы данных в синхронном режиме и асинхронно передает эти изменения удаленным экземплярам базы данных, что обеспечивает и надежность синхронного режима, и производительность асинхронного режима.
Технология Application Continuity позволяет повторять аварийно прерванные транзакции — решая тем самым одну из главных проблем работы веб-приложений с базами данных. Технология делает отказ экземпляра базы данных прозрачным для веб-приложения и позволяет определить состояние последней транзакции. Если транзакция не прошла, она будет выполнена, а если она уже выполнена, то технология Application Continuity не позволяет выполнить ее повторно
Технология динамического маскирования данных Data Redaction прозрачная для приложений и позволяет задавать политики доступа к данным внутри базы данных. Данные остаются неизменными, но, в зависимости от прав конечного пользователя, его роли, он будет видеть только те данные, на доступ к которым он авторизован. Это позволяет приложениям прозрачно работать с базой данных, политика будет выполняться для всех приложений.
Наконец, в Oracle Database 12.1.0.1 была реализована мощная система анализа взаимосвязи строк Pattern Matching, которая позволяет анализировать тренды и находить в них статистические закономерности с помощью конструкций языка SQL. И это — не считая еще более пятисот других модификаций.
Уже в 2014 году компания Oracle выпустила Oracle Database 12.1.0.2, где эти возможности были улучшены и была добавлена новая опция Oracle In-Memory, самая важная.
При разработке In-Memory компания Oracle стремилась создать технологию, которая сделает возможной аналитику в реальном масштабе времени для оперативного принятия бизнес-решений. Крайне важно то, что если у конкурентов Oracle для использования их вариантов опции In-Memory нужна другая база данных, другие технологии, то опция Oracle Database In-Memory встроена в базу данных, включается буквально одним параметром, полностью прозрачна для приложений и совместима со всеми возможностями базы данных. Опыт использования этой опции заказчиками показывает, что обработка транзакций ускоряется в два раза, вставка строк происходит в три-четыре раза быстрее, чем обычно, запросы для аналитики действительно выполняются в реальном масштабе времени, практически мгновенно.
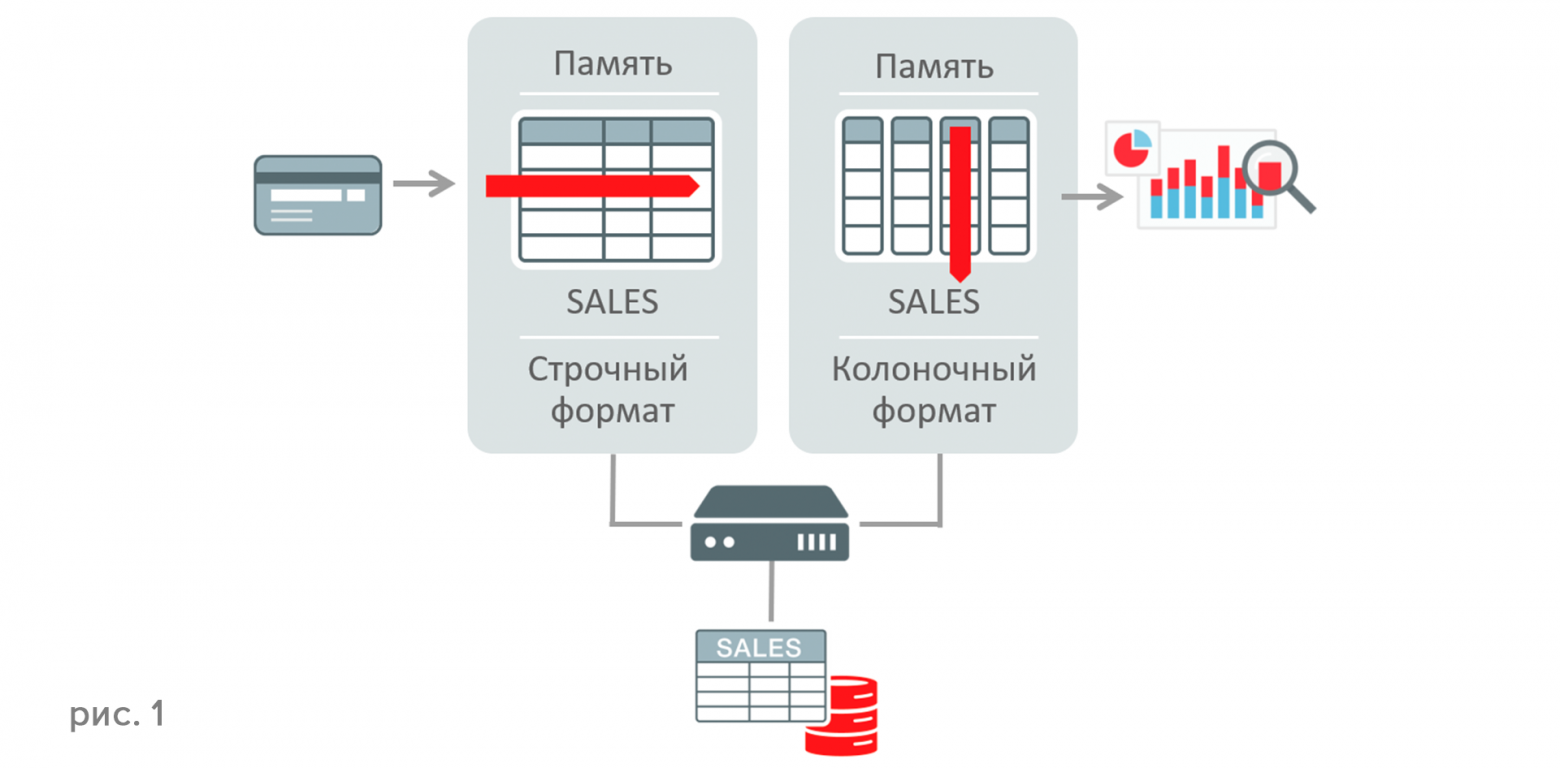
Смысл технологии в том, что рядом с привычным буферным кэшем, который хранит строки таблиц и блоки индексов, создаётся новая разделяемая область для данных в оперативной памяти, в которой они хранятся в колоночном формате (Рис. 1). Таким образом, технология использует и строчный, и колоночный форматы хранения в памяти для одних и тех же данных таблиц, причем данные одновременно активны и транзакционно согласованны. Все изменения сначала производятся в традиционном буферном кэше, после чего отражаются в колоночном кэше.
При этом в колоночном кэше отражаются только таблицы, индексы не кэшируется. Кроме того, если данные читаются, но не изменяются, то в буферном кэше хранить их незачем, но если данные изменяются, то они хранятся в обоих кэшах, буферном и колоночном. Поэтому In-Memory ускоряет работу аналитики, ведь для аналитики более эффективно именно колоночное хранение данных.
Кроме того, опция In-Memory позволяет избавиться от аналитических индексов без ущерба для производительности, при этом появится гибкость: экономится дисковое пространство, можно строить запрос по любому столбцу, который размещен в In-Memory, и для быстрой работы запросов не нужно строить дополнительные индексы.
Важным элементом Oracle Database In-Memory является аппаратная поддержка. В частности, технология поддерживает набор инструкций SIMD (Single Instruction Multiple Data Values), предназначенный для обработки графики, — In-Memory использует эти инструкции, если они встроены в процессор, для сравнения сразу нескольких значений столбца с предикатом, значительно ускоряя скорость сканирования столбца — до 1 млрд строк в секунду.
Но это далеко не все. Серверы Oracle SPARC M7 и T7, выпущенные в конце 2015 г., содержат аппаратную поддержку In-Memory. Для этого в процессоры М7 и Т7 добавлены модуль векторного сканирования базы данных, модуль декомпрессии данных In-Memory и модуль аппаратной защиты памяти, который реализует проверку доступа к данным в оперативной памяти в режиме реального времени, обеспечивающую защиту данных от вредоносных вторжений и ошибок программного кода.
Для того чтобы использовать Oracle In-Memory, достаточно задать размер буфера памяти In-Memory Column Store, указать, какие таблицы, секции, столбцы будут размещаться в этой памяти, перестартовать базу данных и удалить аналитические индексы, если они больше не требуются для обеспечения производительности приложения. In-Memory легко управлять из Oracle Enterprise Manager, где есть отдельная страница In-Memory Central, которая отображает распределение памяти между объектами и позволяет конфигурировать In-Memory Column Store. В последней версии Enterprise Manager 13с имеется инструмент In-Memory Advisor, поддерживаемый для версий баз данных 11.2.0.3 и выше, который анализирует существующую нагрузку базы данных и предоставляет список объектов, загрузка которых в In-Memory Column Store даст максимальный выигрыш.
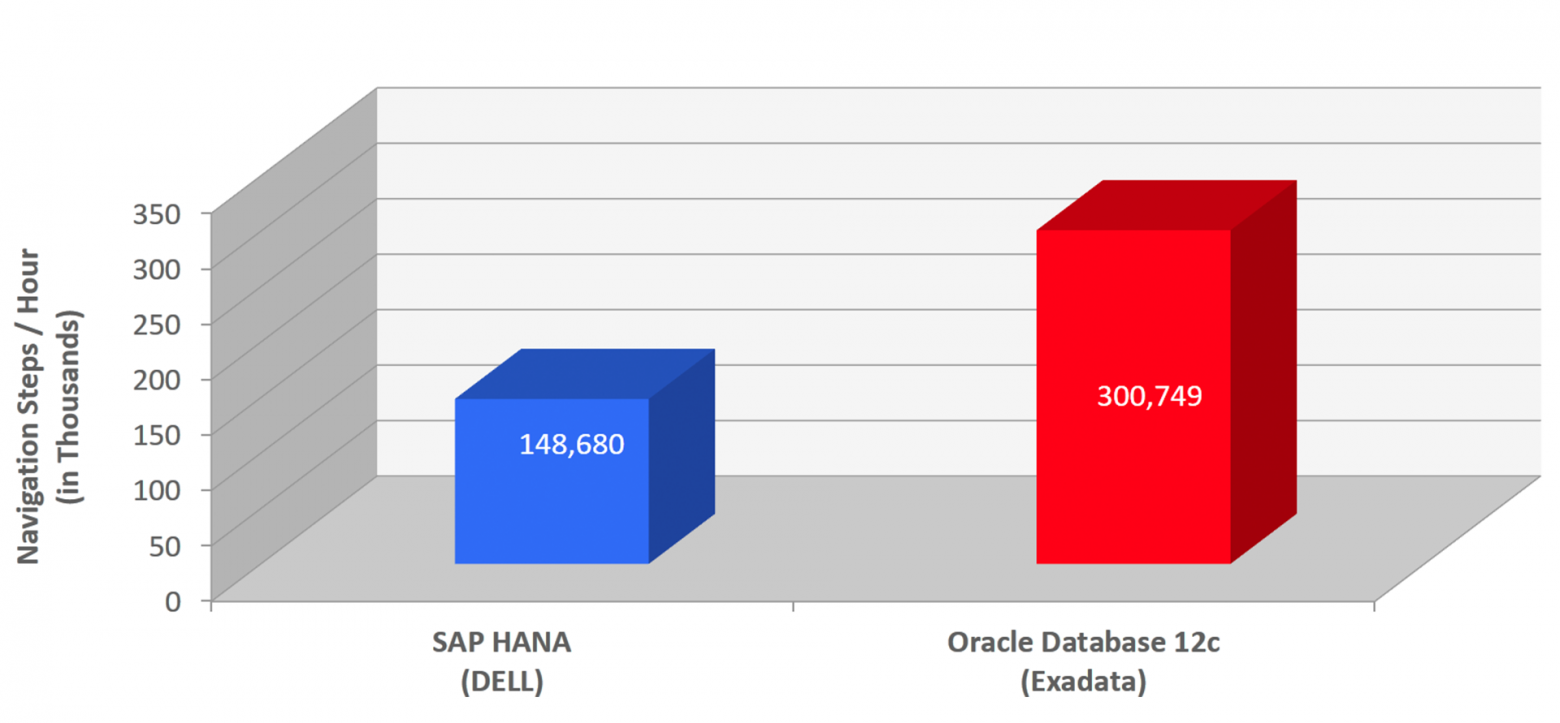
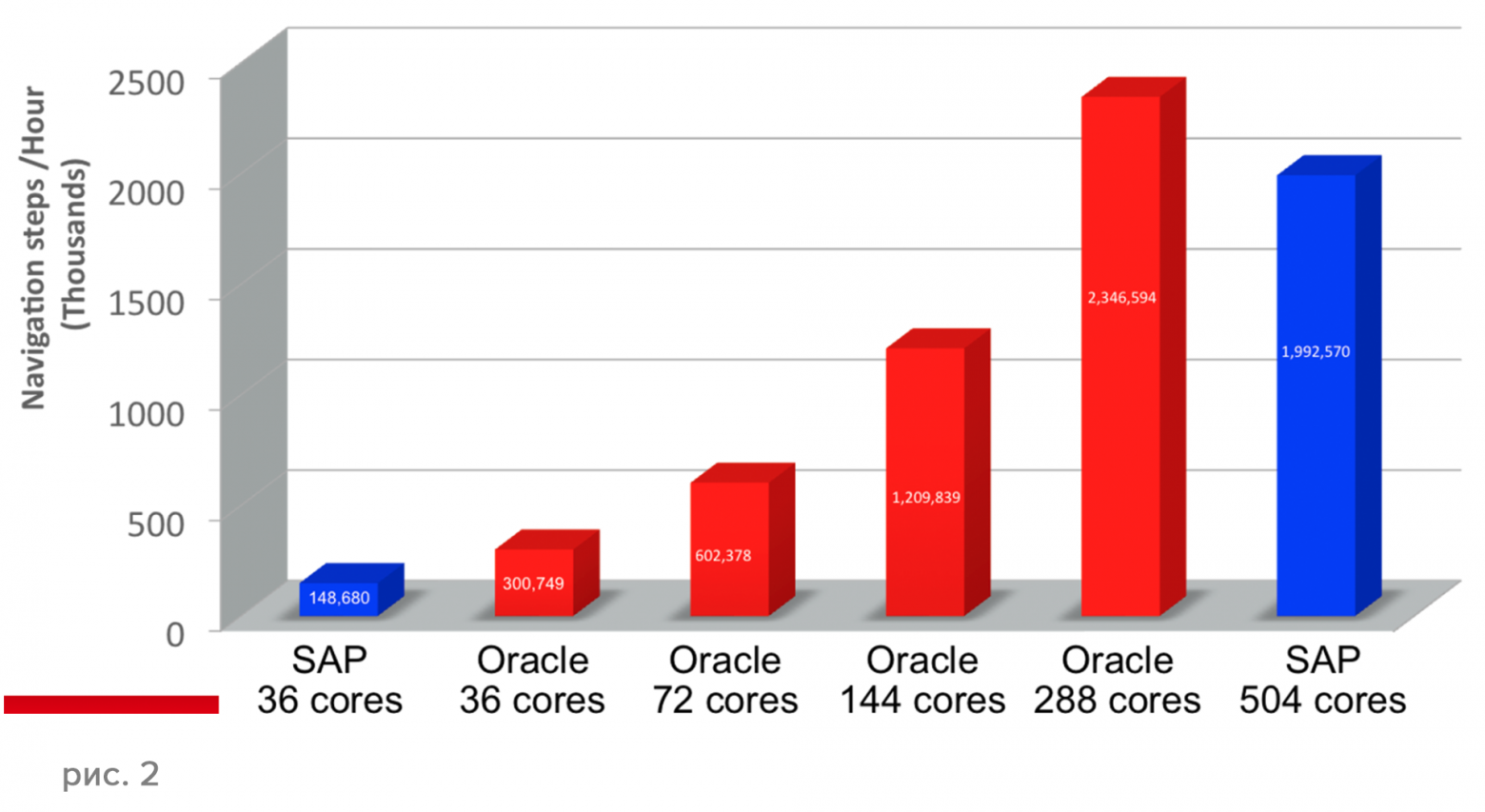
Сравнительное тестирование Oracle Database 12c In-Memory и SAP HANA на одном и том же количестве ядер Intel продемонстрировало вдвое более высокую производительность Oracle Database 12, чем SAP HANA (Рис. 2, сверху). Сравнительное тестирование масштабируемости Oracle Database 12c In-Memory и SAP HANA показало, что Oracle Database 12c In-Memory гораздо лучше масштабируется, чем SAP HANA — практически линейно (Рис. 2, снизу).
Мы уже говорили о том, что от тяжелых монолитных приложений ИТ-отрасль переходит к веб-сервисам. Поскольку веб-сервисы все чаще обращаются друг к другу через REST интерфейс, компания Oracle предоставляет Java-приложение Oracle REST Data Services (ORDS), предоставляющее единый REST интерфейс для работы с СУБД Oracle (реляционные данные и JSON Document Store) и Oracle NoSQL Database. ORDS может использоваться как в автономном режиме, так и развёрнуто на серверах приложений WebLogic Server, Oracle Glassfish Server, Apache Tomcat. SQL Developer предоставляет удобную платформу для установки и настройки ORDS, в частности, он содержит мастер настройки, который автоматически создаёт REST-сервисы для доступа к таблицам базы данных. На Oracle Technology Network бесплатно доступна виртуальная машина VirtualBox с настроенными Big Data Lite Virtual Machine и сконфигурированными REST-сервисами. Поскольку один и тот же REST-вызов может применяться к различным базам данных, это повышает гибкость и скорость программирования, т.к. от разработчика не требуется знания SQL и специфики базы данных. В Oracle Database 12.1.0.2 встроена поддержка JSON-баз данных. REST-сервисы могут работать либо с JSON Document Store в базе данных версии 12с, либо с реляционными таблицами базы данных, которые представлены как REST Data Services, либо с NoSQL-базами данных.
Oracle Big Data Appliance — это кластеры, предназначенные для работы Hadoop и NoSQL баз данных. В отличие от остальных программно-аппаратных комплексов Oracle, эти системы разработаны совместно с компанией Cloudera, одним из ведущих поставщиков дистрибутива Hadoop. Вопреки распространенному заблуждению, такие системы нужны не только компаниям из Интернет-бизнеса, потому что сегодня с потребностью обработки гигантских объемов данных сталкиваются любые компании, которые должны заниматься глубоким анализом поведения клиентов, планировать высокоточную рекламу, объединять и анализировать данные из многих источников, в том числе неструктурированных, бороться с мошенничеством и т. д.
Oracle Big Data SQL в составе Oracle Big Data Appliance позволяет делать из Oracle Database 12с один быстрый SQL-запрос ко всем данным, хранящимся в Hadoop, реляционных и NoSQL базах данных. Oracle Big Data SQL — это новая архитектура, предлагающая мощный, высокопроизводительный SQL на Hadoop, с полным набором возможностей Oracle SQL на Hadoop и локальной обработкой SQL-запросов на узлах Hadoop. Архитектура предлагает простую интеграцию данных Hadoop ,Oracle Database и Oracle NoSQL, единую точку входа SQL для доступа ко всем данным, масштабируемые соединения между данными Hadoop и RDBMS.
Oracle NoSQL Database — это масштабируемая, высокопроизводительная, высокодоступная СУБД с прозрачной балансировкой нагрузки, весь объем данных в которой хранится в виде пар «ключ–значение».
Новые возможности Multitenant-баз данных версии 12.1.0.2 касаются в первую очередь клонирования PDB (pluggable db, подключаемых) баз данных. Часть табличных пространств теперь можно исключить из клонирования. Возможно клонирование только метаданных, что иногда требуется для разработки. Удаленное клонирование позволяет клонировать PDB базу данных между двумя контейнерными базами данных через database link. Наконец, появилось тонкое клонирование, основанное на встроенной в базу данных технологии Direct NFS и не зависящее от файловой системы.
Другие улучшения включают новое выражение SQL, которое позволяет делать агрегированные запросы по таблицам, которые расположены в нескольких подключаемых базах данных. Новая фраза «standbys» позволяет при создании подключаемой базы данных в явном виде задать или отменить создание резервной базы.
Во-вторых, важно помнить о том, что в условиях снижения затрат на ИТ разработчикам нужны новые инструменты, которые позволяют быстрее внедрять инновации и упрощать поддержку приложений. Так, например, для интеграции новых разработок с существующими корпоративными инфраструктурами разработчики уходят от монолитных приложений, сложных и тяжелых в разработке, в сторону архитектуры микросервисов, т. е. приложений, представляющих собой наборы независимо развертываемых сервисов. И для работы с новой архитектурой необходимо, чтобы база данных поддерживала новые инструменты и новые методы программирования.
Все это компания Oracle учла при разработке базы данных Oracle Database 12.1.0.2. Эта статья — обзор основных нововведений этой версии.
Oracle Database 12c
Начнем с того, что в 2013 г. компания Oracle выпустила версию Oracle Database 12c (версия 12.1.0.1), основными достоинствами которой стали снижение стоимости хранения, высокая доступность данных, простота консолидации баз данных и защита доступа к данным.
Говоря чуть подробнее, в этой версии появилась архитектура Oracle Multitenant, которая существенно облегчает консолидацию баз данных, ускоряет развертывание баз данных и позволяет управлять многими базами данных как одним целым — вместо администрирования сотен баз данных по отдельности администратор работает с одной базой данных, управляя многими базами данных, как одной. Все это сделало версию Oracle Database 12c на момент ее выпуска самой подходящей системой управления базами данных для облачных вычислений, особенно для SaaS-приложений, где особенно актуально скоростное создание новых баз данных по требованию пользователей, которое при поддержке технологии Snapshot Cloning (тонкое клонирование) занимает несколько минут.
Кроме того, в Oracle Database 12.1.0.1 появилась автоматическая оптимизация данных, сочетающая технологию «умного сжатия», которая автоматически выявляет блоки данных, к которым редко обращались («холодные» данные), и сжимает их, и технологию автоматизации многоуровневого хранения данных, которая автоматически переносит «холодные» данные на более дешевый уровень хранения.
Еще одна новая технология Oracle Database 12c, которая называется Data Guard Far Sync, обеспечивает нулевую потерю данных на больших расстояниях и позволяет держать резервные копии баз данных на большом удалении от основной базы данных. Дополнительный специальный экземпляр базы данных, не имеющий файлов данных, принимает изменения от основной базы данных в синхронном режиме и асинхронно передает эти изменения удаленным экземплярам базы данных, что обеспечивает и надежность синхронного режима, и производительность асинхронного режима.
Технология Application Continuity позволяет повторять аварийно прерванные транзакции — решая тем самым одну из главных проблем работы веб-приложений с базами данных. Технология делает отказ экземпляра базы данных прозрачным для веб-приложения и позволяет определить состояние последней транзакции. Если транзакция не прошла, она будет выполнена, а если она уже выполнена, то технология Application Continuity не позволяет выполнить ее повторно
Технология динамического маскирования данных Data Redaction прозрачная для приложений и позволяет задавать политики доступа к данным внутри базы данных. Данные остаются неизменными, но, в зависимости от прав конечного пользователя, его роли, он будет видеть только те данные, на доступ к которым он авторизован. Это позволяет приложениям прозрачно работать с базой данных, политика будет выполняться для всех приложений.
Наконец, в Oracle Database 12.1.0.1 была реализована мощная система анализа взаимосвязи строк Pattern Matching, которая позволяет анализировать тренды и находить в них статистические закономерности с помощью конструкций языка SQL. И это — не считая еще более пятисот других модификаций.
Уже в 2014 году компания Oracle выпустила Oracle Database 12.1.0.2, где эти возможности были улучшены и была добавлена новая опция Oracle In-Memory, самая важная.
Oracle Database 12.1.0.2: In-Memory
При разработке In-Memory компания Oracle стремилась создать технологию, которая сделает возможной аналитику в реальном масштабе времени для оперативного принятия бизнес-решений. Крайне важно то, что если у конкурентов Oracle для использования их вариантов опции In-Memory нужна другая база данных, другие технологии, то опция Oracle Database In-Memory встроена в базу данных, включается буквально одним параметром, полностью прозрачна для приложений и совместима со всеми возможностями базы данных. Опыт использования этой опции заказчиками показывает, что обработка транзакций ускоряется в два раза, вставка строк происходит в три-четыре раза быстрее, чем обычно, запросы для аналитики действительно выполняются в реальном масштабе времени, практически мгновенно.
Смысл технологии в том, что рядом с привычным буферным кэшем, который хранит строки таблиц и блоки индексов, создаётся новая разделяемая область для данных в оперативной памяти, в которой они хранятся в колоночном формате (Рис. 1). Таким образом, технология использует и строчный, и колоночный форматы хранения в памяти для одних и тех же данных таблиц, причем данные одновременно активны и транзакционно согласованны. Все изменения сначала производятся в традиционном буферном кэше, после чего отражаются в колоночном кэше.
При этом в колоночном кэше отражаются только таблицы, индексы не кэшируется. Кроме того, если данные читаются, но не изменяются, то в буферном кэше хранить их незачем, но если данные изменяются, то они хранятся в обоих кэшах, буферном и колоночном. Поэтому In-Memory ускоряет работу аналитики, ведь для аналитики более эффективно именно колоночное хранение данных.
Кроме того, опция In-Memory позволяет избавиться от аналитических индексов без ущерба для производительности, при этом появится гибкость: экономится дисковое пространство, можно строить запрос по любому столбцу, который размещен в In-Memory, и для быстрой работы запросов не нужно строить дополнительные индексы.
Важным элементом Oracle Database In-Memory является аппаратная поддержка. В частности, технология поддерживает набор инструкций SIMD (Single Instruction Multiple Data Values), предназначенный для обработки графики, — In-Memory использует эти инструкции, если они встроены в процессор, для сравнения сразу нескольких значений столбца с предикатом, значительно ускоряя скорость сканирования столбца — до 1 млрд строк в секунду.
Но это далеко не все. Серверы Oracle SPARC M7 и T7, выпущенные в конце 2015 г., содержат аппаратную поддержку In-Memory. Для этого в процессоры М7 и Т7 добавлены модуль векторного сканирования базы данных, модуль декомпрессии данных In-Memory и модуль аппаратной защиты памяти, который реализует проверку доступа к данным в оперативной памяти в режиме реального времени, обеспечивающую защиту данных от вредоносных вторжений и ошибок программного кода.
Для того чтобы использовать Oracle In-Memory, достаточно задать размер буфера памяти In-Memory Column Store, указать, какие таблицы, секции, столбцы будут размещаться в этой памяти, перестартовать базу данных и удалить аналитические индексы, если они больше не требуются для обеспечения производительности приложения. In-Memory легко управлять из Oracle Enterprise Manager, где есть отдельная страница In-Memory Central, которая отображает распределение памяти между объектами и позволяет конфигурировать In-Memory Column Store. В последней версии Enterprise Manager 13с имеется инструмент In-Memory Advisor, поддерживаемый для версий баз данных 11.2.0.3 и выше, который анализирует существующую нагрузку базы данных и предоставляет список объектов, загрузка которых в In-Memory Column Store даст максимальный выигрыш.
Сравнительное тестирование Oracle Database 12c In-Memory и SAP HANA на одном и том же количестве ядер Intel продемонстрировало вдвое более высокую производительность Oracle Database 12, чем SAP HANA (Рис. 2, сверху). Сравнительное тестирование масштабируемости Oracle Database 12c In-Memory и SAP HANA показало, что Oracle Database 12c In-Memory гораздо лучше масштабируется, чем SAP HANA — практически линейно (Рис. 2, снизу).
Новые возможности для разработчиков
Мы уже говорили о том, что от тяжелых монолитных приложений ИТ-отрасль переходит к веб-сервисам. Поскольку веб-сервисы все чаще обращаются друг к другу через REST интерфейс, компания Oracle предоставляет Java-приложение Oracle REST Data Services (ORDS), предоставляющее единый REST интерфейс для работы с СУБД Oracle (реляционные данные и JSON Document Store) и Oracle NoSQL Database. ORDS может использоваться как в автономном режиме, так и развёрнуто на серверах приложений WebLogic Server, Oracle Glassfish Server, Apache Tomcat. SQL Developer предоставляет удобную платформу для установки и настройки ORDS, в частности, он содержит мастер настройки, который автоматически создаёт REST-сервисы для доступа к таблицам базы данных. На Oracle Technology Network бесплатно доступна виртуальная машина VirtualBox с настроенными Big Data Lite Virtual Machine и сконфигурированными REST-сервисами. Поскольку один и тот же REST-вызов может применяться к различным базам данных, это повышает гибкость и скорость программирования, т.к. от разработчика не требуется знания SQL и специфики базы данных. В Oracle Database 12.1.0.2 встроена поддержка JSON-баз данных. REST-сервисы могут работать либо с JSON Document Store в базе данных версии 12с, либо с реляционными таблицами базы данных, которые представлены как REST Data Services, либо с NoSQL-базами данных.
Oracle Database 12с и Big Data
Oracle Big Data Appliance — это кластеры, предназначенные для работы Hadoop и NoSQL баз данных. В отличие от остальных программно-аппаратных комплексов Oracle, эти системы разработаны совместно с компанией Cloudera, одним из ведущих поставщиков дистрибутива Hadoop. Вопреки распространенному заблуждению, такие системы нужны не только компаниям из Интернет-бизнеса, потому что сегодня с потребностью обработки гигантских объемов данных сталкиваются любые компании, которые должны заниматься глубоким анализом поведения клиентов, планировать высокоточную рекламу, объединять и анализировать данные из многих источников, в том числе неструктурированных, бороться с мошенничеством и т. д.
Oracle Big Data SQL в составе Oracle Big Data Appliance позволяет делать из Oracle Database 12с один быстрый SQL-запрос ко всем данным, хранящимся в Hadoop, реляционных и NoSQL базах данных. Oracle Big Data SQL — это новая архитектура, предлагающая мощный, высокопроизводительный SQL на Hadoop, с полным набором возможностей Oracle SQL на Hadoop и локальной обработкой SQL-запросов на узлах Hadoop. Архитектура предлагает простую интеграцию данных Hadoop ,Oracle Database и Oracle NoSQL, единую точку входа SQL для доступа ко всем данным, масштабируемые соединения между данными Hadoop и RDBMS.
Oracle NoSQL Database — это масштабируемая, высокопроизводительная, высокодоступная СУБД с прозрачной балансировкой нагрузки, весь объем данных в которой хранится в виде пар «ключ–значение».
Улучшения в Oracle Multitenant
Новые возможности Multitenant-баз данных версии 12.1.0.2 касаются в первую очередь клонирования PDB (pluggable db, подключаемых) баз данных. Часть табличных пространств теперь можно исключить из клонирования. Возможно клонирование только метаданных, что иногда требуется для разработки. Удаленное клонирование позволяет клонировать PDB базу данных между двумя контейнерными базами данных через database link. Наконец, появилось тонкое клонирование, основанное на встроенной в базу данных технологии Direct NFS и не зависящее от файловой системы.
Другие улучшения включают новое выражение SQL, которое позволяет делать агрегированные запросы по таблицам, которые расположены в нескольких подключаемых базах данных. Новая фраза «standbys» позволяет при создании подключаемой базы данных в явном виде задать или отменить создание резервной базы.
Другие улучшения
- Технология Advanced Index Compression сжимает индексы для уменьшения занимаемого дискового пространства (в некоторых базах данных индекс занимает половину дискового пространства) и более эффективного использования кэша.
- Полное кэширование базы данных. Включается автоматически, чтобы получить отдачу от всей доступной памяти и потенциально повысить производительность, если база данных помещается в память. Возможно принудительное включение полного кэширования, включая таблицы с NOCACHE LOB объектами, командой ALTER DATABASE FORCE FULL DATABASE CACHING.
- Автоматическое кэширование больших таблиц. Можно использовать, если база данных не помещается в память целиком, но некоторые большие объекты помещаются. Параметр DB_BIG_TABLE_CACHE_PERCENT_TARGET позволяет выделить в буферном кэше отдельную область для больших таблиц. Если в обычном буферном кэше данные кэшируются на уровне блоков, то большие таблицы кэшируются и удаляются из этой области кэша целиком на основе частоты доступа к ним.
- Директива Attribute Clustering, задаваемая для таблицы, упорядочивает данные по значениям столбцов, при этом строки с одинаковыми значениями столбцов лежат вместе на диске. Эта директива работает во время операций прямой загрузки данных, таких как массовая вставка записей или перемещение таблицы. Attribute Clustering может быть полезна для сжатия данных, т.к. упорядоченные данные лучше сжимаются при использовании опции Advanced Compression. Но наибольшую выгоду Attribute Clustering даёт при совместном использовании с другой новой возможностью Oracle Database 12.1.0.2, Zone Maps. Карты Zone maps, доступные на Oracle Exadata или Supercluster, содержат минимальные и максимальные значения заданных столбцов для диапазонов строк и позволяют при выполнении запроса быстро отфильтровывать ненужные данные. Эти технологии полностью прозрачны для приложений, они улучшают производительность запросов, сокращают количество физических чтений, существенно сокращают число операций ввода-вывода для запросов с высокой селективностью и оптимизируют использование дискового пространства.
- Approximate Count Distinct — это функция приблизительного подсчета различных значений столбца (ведь не каждый запрос требует точного результата — например, на вопрос «Сколько различных посетителей было на нашем сайте на прошлой неделе?» вполне можно дать приблизительный ответ), которая работает значительно (до 50 раз) быстрее, чем точный подсчет, и дает точность более 97 % с 95%-м коэффициентом доверия.
