
Недавно в Redash приступили к смене одной системы выполнения задач на другую. А именно — они начали переход с Celery на RQ. На первом этапе на новую платформу перевели лишь те задания, которые не выполняют запросы напрямую. Среди таких заданий — отправка электронных писем, выяснение того, какие запросы должны быть обновлены, запись пользовательских событий и другие вспомогательные задачи.

После развёртывания всего этого было замечено, что RQ-воркеры требуют гораздо больше вычислительных ресурсов для решения того же объёма задач, который раньше решали средствами Celery.
Материал, перевод которого мы сегодня публикуем, посвящён рассказу о том, как в Redash выяснили причину проблемы и справились с ней.
В Celery и в RQ имеется концепция процессов-воркеров. И там и там для организации параллельного выполнения заданий используется создание форков. Когда запускается воркер Celery — создаётся несколько процессов-форков, каждый из которых автономно обрабатывает задачи. В случае с RQ экземпляр воркера содержит лишь один подпроцесс (известный как «рабочая лошадка»), который выполняет одну задачу, а потом уничтожается. Когда воркер загружает очередное задание из очереди — он создаёт новую «рабочую лошадку».
При работе с RQ можно достичь того же уровня параллелизма, что и при работе с Celery, просто запуская больше процессов-воркеров. Однако между Celery и RQ есть одно тонкое различие. В Celery воркер создаёт множество экземпляров подпроцессов при запуске, после чего многократно их использует для выполнения множества заданий. А в случае с RQ для каждого задания нужно создавать новый форк. И тот и другой подходы имеют свои плюсы и минусы, но здесь мы об этом говорить не будем.
Прежде чем я приступил к профилированию, я решил замерить производительность системы, выяснив, сколько времени воркер-контейнеру нужно для обработки 1000 заданий. Я решил сосредоточиться на задании
Теперь можно было приступать к измерениям. Для начала мне хотелось узнать о том, сколько времени занимает запуск и остановка воркера без нагрузки. Это время можно было вычесть из итоговых результатов, полученных позже.
Инициализация воркера на моём компьютере заняла 14.7 секунд. Я это запомнил.
Затем я поместил 1000 тестовых заданий
После этого я запустил систему так же, как делал это раньше, и узнал о том, сколько времени занимает обработка 1000 заданий.
Вычтя из того, что получилось, 14.7 секунд, я узнал о том, что 4 воркера обрабатывают 1000 заданий в течение 102 секунд. Теперь попытаемся узнать о том, почему это так. Для этого мы, в то время, пока воркеры заняты делом, исследуем их с помощью
Добавим в очередь ещё 1000 заданий (сделать это нужно из-за того, что в ходе ранее проведённых измерений все задания были обработаны), запустим воркеры и пошпионим за ними.
Я знаю о том, что предыдущая команда получилась очень длинной. В идеале, чтобы улучшить её читабельность, её стоило бы разбить на отдельные фрагменты, разделив её в тех местах, где встречаются последовательности символов
В результате получен следующий «пламенный график».
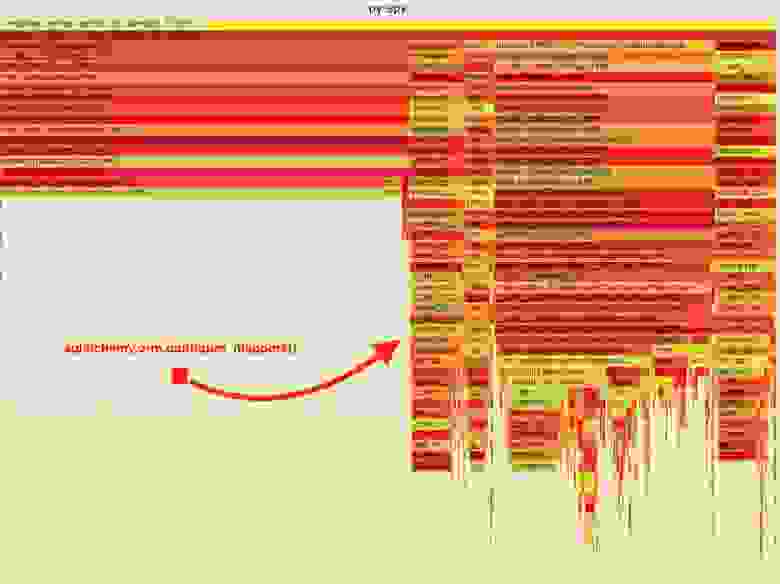
Визуализация данных, собранных py-spy
Проанализировав эти данные, я заметил, что задание
Подобные вещи совершенно не обязаны происходить с каждым форком. Мы можем один раз инициализировать отношения в родительском воркере и избежать повторного выполнения этой задачи в «рабочих лошадках».
В результате я добавил в код вызов
Если вычесть из этих результатов 14.7 секунд, то окажется, что мы улучшили время, необходимое 4 воркерам на обработку 1000 заданий, со 102 секунд до 24.6 секунд. Это — четырёхкратное улучшение производительности! Благодаря этому исправлению мы смогли вчетверо сократить продакшн-ресурсы RQ и сохранить ту же пропускную способность системы.
Из всего этого я сделал следующий вывод: стоит помнить о том, что приложение ведёт себя по-разному в том случае, если оно представляет собой единственный процесс, и в том случае, если речь идёт о форках. Если при выполнении каждого задания приходится решать какие-то тяжёлые служебные задачи, то решить их лучше заблаговременно, сделав это один раз до выполнения форка. Подобные вещи не выявляются в ходе тестирования и разработки, поэтому, почувствовав, что с проектом что-то не так, замерьте его быстродействие и дойдите до конца в ходе поиска причин проблем с его производительностью.
Уважаемые читатели! Сталкивались ли вы с проблемами в производительности Python-проектов, которые можно было решить, тщательно проанализировав работающую систему?



После развёртывания всего этого было замечено, что RQ-воркеры требуют гораздо больше вычислительных ресурсов для решения того же объёма задач, который раньше решали средствами Celery.
Материал, перевод которого мы сегодня публикуем, посвящён рассказу о том, как в Redash выяснили причину проблемы и справились с ней.
Пара слов о различиях Celery и RQ
В Celery и в RQ имеется концепция процессов-воркеров. И там и там для организации параллельного выполнения заданий используется создание форков. Когда запускается воркер Celery — создаётся несколько процессов-форков, каждый из которых автономно обрабатывает задачи. В случае с RQ экземпляр воркера содержит лишь один подпроцесс (известный как «рабочая лошадка»), который выполняет одну задачу, а потом уничтожается. Когда воркер загружает очередное задание из очереди — он создаёт новую «рабочую лошадку».
При работе с RQ можно достичь того же уровня параллелизма, что и при работе с Celery, просто запуская больше процессов-воркеров. Однако между Celery и RQ есть одно тонкое различие. В Celery воркер создаёт множество экземпляров подпроцессов при запуске, после чего многократно их использует для выполнения множества заданий. А в случае с RQ для каждого задания нужно создавать новый форк. И тот и другой подходы имеют свои плюсы и минусы, но здесь мы об этом говорить не будем.
Измерение производительности
Прежде чем я приступил к профилированию, я решил замерить производительность системы, выяснив, сколько времени воркер-контейнеру нужно для обработки 1000 заданий. Я решил сосредоточиться на задании
record_event, так как это — часто встречающаяся легковесная операция. Для измерения производительности я воспользовался командой time. Это потребовало внести в код проекта пару изменений:- Для измерения производительности выполнения 1000 задач я решил использовать пакетный режим RQ, в котором, после обработки заданий, осуществляется выход из процесса.
- Мне хотелось избежать влияния на мои измерения других заданий, которые могли быть запланированы на то время, когда я измерял производительность системы. Поэтому я переместил
record_eventв отдельную очередь, названнуюbenchmark, заменив@job(‘default’)на@job(‘benchmark’). Сделано это было сразу перед объявлениемrecord_eventвtasks/general.py.
Теперь можно было приступать к измерениям. Для начала мне хотелось узнать о том, сколько времени занимает запуск и остановка воркера без нагрузки. Это время можно было вычесть из итоговых результатов, полученных позже.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark"
real
0m14.728s
user
0m6.810s
sys
0m2.750sИнициализация воркера на моём компьютере заняла 14.7 секунд. Я это запомнил.
Затем я поместил 1000 тестовых заданий
record_event в очередь benchmark:$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"После этого я запустил систему так же, как делал это раньше, и узнал о том, сколько времени занимает обработка 1000 заданий.
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark"
real
1m57.332s
user
1m11.320s
sys
0m27.540sВычтя из того, что получилось, 14.7 секунд, я узнал о том, что 4 воркера обрабатывают 1000 заданий в течение 102 секунд. Теперь попытаемся узнать о том, почему это так. Для этого мы, в то время, пока воркеры заняты делом, исследуем их с помощью
py-spy.Профилирование
Добавим в очередь ещё 1000 заданий (сделать это нужно из-за того, что в ходе ранее проведённых измерений все задания были обработаны), запустим воркеры и пошпионим за ними.
$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]"
$ docker-compose exec worker bash -c 'nohup ./manage.py rq workers 4 benchmark & sleep 15 && pip install py-spy && rq info -u "redis://redis:6379/0" | grep busy | awk "{print $3}" | grep -o -P "\s\d+" | head -n 1 | xargs py-spy record -d 10 --subprocesses -o profile.svg -p'
$ open -a "Google Chrome" profile.svgЯ знаю о том, что предыдущая команда получилась очень длинной. В идеале, чтобы улучшить её читабельность, её стоило бы разбить на отдельные фрагменты, разделив её в тех местах, где встречаются последовательности символов
&&. Но команды должны выполняться последовательно внутри одной сессии docker-compose exec worker bash, поэтому всё выглядит именно так. Вот описание того, что делает эта команда:- Запускает 4 пакетных воркера в фоне.
- Ждёт 15 секунд (примерно столько нужно для того, чтобы закончилась их загрузка).
- Устанавливает
py-spy. - Запускает
rq-infoи выясняет PID одного из воркеров. - Записывает сведения о работе воркера с ранее полученным PID в течение 10 секунд и сохраняет данные в файле
profile.svg
В результате получен следующий «пламенный график».
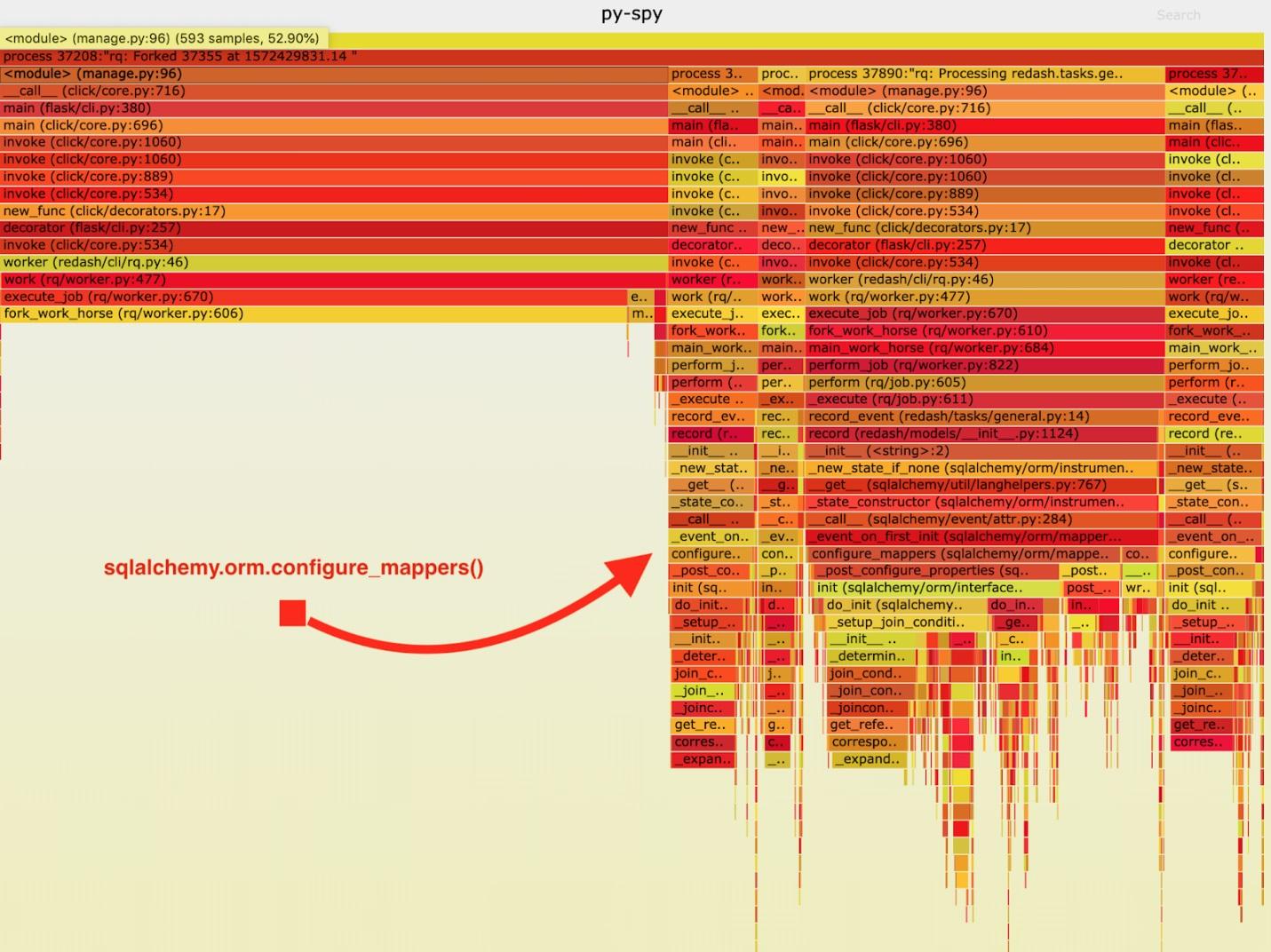
Визуализация данных, собранных py-spy
Проанализировав эти данные, я заметил, что задание
record_event тратит большой отрезок времени его выполнения в sqlalchemy.orm.configure_mappers. Это происходит при выполнении каждого задания. Из документации я узнал о том, что в интересующее меня время происходит инициализация отношений всех ранее созданных мапперов.Подобные вещи совершенно не обязаны происходить с каждым форком. Мы можем один раз инициализировать отношения в родительском воркере и избежать повторного выполнения этой задачи в «рабочих лошадках».
В результате я добавил в код вызов
sqlalchemy.org.configure_mappers() до запуска «рабочей лошадки» и снова провёл измерения.$ docker-compose run --rm server manage shell <<< "from redash.tasks.general import record_event; [record_event.delay({ 'action': 'create', 'timestamp': 0, 'org_id': 1, 'user_id': 1, 'object_id': 0, 'object_type': 'dummy' }) for i in range(1000)]
$ docker-compose exec worker bash -c "time ./manage.py rq workers 4 benchmark"
real
0m39.348s
user
0m15.190s
sys
0m10.330sЕсли вычесть из этих результатов 14.7 секунд, то окажется, что мы улучшили время, необходимое 4 воркерам на обработку 1000 заданий, со 102 секунд до 24.6 секунд. Это — четырёхкратное улучшение производительности! Благодаря этому исправлению мы смогли вчетверо сократить продакшн-ресурсы RQ и сохранить ту же пропускную способность системы.
Итоги
Из всего этого я сделал следующий вывод: стоит помнить о том, что приложение ведёт себя по-разному в том случае, если оно представляет собой единственный процесс, и в том случае, если речь идёт о форках. Если при выполнении каждого задания приходится решать какие-то тяжёлые служебные задачи, то решить их лучше заблаговременно, сделав это один раз до выполнения форка. Подобные вещи не выявляются в ходе тестирования и разработки, поэтому, почувствовав, что с проектом что-то не так, замерьте его быстродействие и дойдите до конца в ходе поиска причин проблем с его производительностью.
Уважаемые читатели! Сталкивались ли вы с проблемами в производительности Python-проектов, которые можно было решить, тщательно проанализировав работающую систему?


