

Привет, чемпион!
Возможно, ты сейчас готовишься к собеседованию в какую-нибудь IT-компанию. Скорее всего, тебе будут задавать технические вопросы, поэтому тебе приходится готовиться. Но, возможно, ты всё равно не сможешь ответить на все вопросы правильно. Как быть?!
А слышал ли ты про новую умную chatGPT? А что, если Я тебе скажу, что больше готовиться к собеседованиям так усердно не нужно! Что?! Задаваемые тебе вопросы можно делегировать chatGPT.
В общем, нет времени объяснять, давай устроим собес для chatGPT по Data Science и узнаем, сможет ли сетка его пройти?! Всё по классике — спрашиваем вопросы по 4 секциям:
- Программирование — Python и алгоритмы,
- Написание SQL-запросов,
- Data Science и статистика,
- ML System Design.
▍ ??Секция программирования (medium и hard)
? Задача Medium-уровня: для заданной строки
s найди длину самой длинной подстроки без повторяющихся символов. Используй язык Python.Ответ GPT:
def find_longest_substring(s):
# Create a dictionary to store the last seen index for each character
char_indices = {}
# Initialize the longest substring length to 0
longest = 0
# Initialize the start and end indices for the current substring
start = 0
end = 0
# Iterate through the string
while end < len(s):
# If the current character is not in the dictionary, add it and move the end index
if s[end] not in char_indices:
char_indices[s[end]] = end
end += 1
# Otherwise, update the start index to be one past the last seen index for this character
else:
start = char_indices[s[end]] + 1
char_indices[s[end]] = end
end += 1
# Update the longest substring length if necessary
longest = max(longest, end - start)
# Return the longest substring length
return longest
# Test the function
s = "abcabcbb"
print(find_longest_substring(s)) # Should print 3
Доп. пояснение от ChatGPT
Эта функция для хранения символов в текущей подстроке использует словарь для хранения последнего увиденного индекса для каждого символа. Это позволяет ему легче обновлять начальный индекс всякий раз, когда он встречает повторяющийся символ. В остальном она перебирает строку и обновляет самую длинную длину подстроки всякий раз, когда перемещается конечный индекс. Когда цикл заканчивается, он возвращает самую длинную длину подстроки.
Эта функция имеет временную сложность
O(n), где n — длина входной строки. Это связано с тем, что он перебирает каждый символ в строке ровно один раз.
Оригинальный ответ от ChatGPT (можно не смотреть)
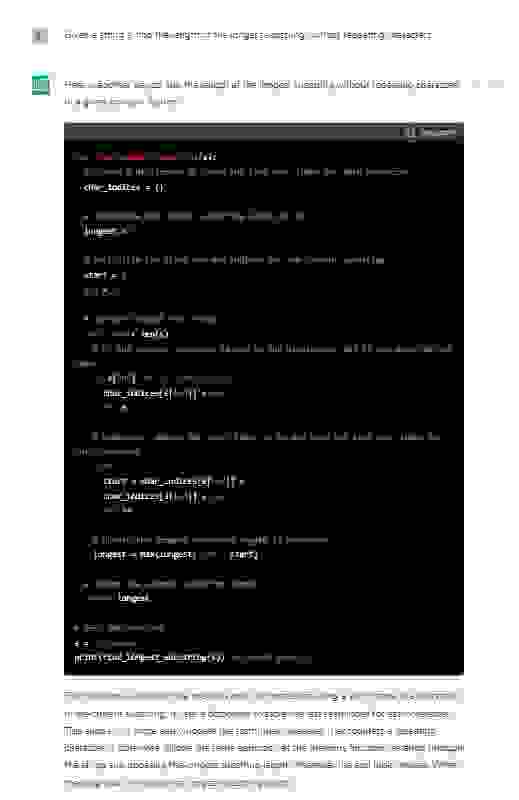

? Комментарий: Даже это же просто вау! Сетка сгенерировала этот ответ за пару секунд. Даже мне бы пришлось подумать, как реализовать, а тут подробное решение за мгновение. Может быть, это тупо заготовленный ответ? Попробуем дать задачу посложнее!
? Задача Hard-уровня: Имея две строки str1 и str2, вернуть самую короткую строку, в которой есть как str1, так и str2 в качестве подпоследовательностей. Если есть несколько допустимых строк, верните любую из них. Строка s является подпоследовательностью строки t, если удаление некоторого количества символов из t (возможно, 0) приводит к строке s.
Решение от ChatGPT: Чтобы решить эту проблему, вы можете использовать двоичное дерево поиска (BST) для хранения элементов массива
nums. Каждый узел в BST будет хранить значение элемента, а также количество элементов в поддереве, корнем которого является этот узел. Затем для каждого элемента в массиве nums вы можете пройти BST, начиная с корня и переходя к левому дочернему элементу, если элемент меньше текущего узла, или к правому дочернему элементу, если элемент больше или равен текущему узлу. Всякий раз, когда вы идёте влево, вы добавляете количество элементов в правом поддереве текущего узла к результату для этого элемента (поскольку все эти элементы меньше, чем текущий элемент). Когда вы достигаете конечного узла, вы вставляете элемент в дерево и обновляете количество всех узлов на обратном пути к корню. Вот некоторый псевдокод, демонстрирующий этот подход:
Псевдокод от ChatGPT
# define a Node class to represent a node in the binary search tree
class Node:
# initialize the node with a given value
def __init__(self, val):
self.val = val
self.left = None
self.right = None
self.count = 1
# insert a new element into the subtree rooted at this node
def insert(self, val):
# if the value is smaller than the current node, go left
if val < self.val:
# if there is no left child, insert the element as the left child
if not self.left:
self.left = Node(val)
# otherwise, insert the element into the left subtree
else:
self.left.insert(val)
# if the value is greater than or equal to the current node, go right
else:
# if there is no right child, insert the element as the right child
if not self.right:
self.right = Node(val)
# otherwise, insert the element into the right subtree
else:
self.right.insert(val)
# increment the count of the node
self.count += 1
# search for an element in the subtree rooted at this node
# return the number of elements smaller than the given element
def search(self, val):
# initialize the result to 0
result = 0
# if the value is smaller than the current node, go left
if val < self.val:
# if there is no left child, return 0
if not self.left:
return 0
# otherwise, search the left subtree and return the result
else:
return self.left.search(val)
# if the value is greater than or equal to the current node, go right
else:
# if there is no right child, insert the element into the tree
if not self.right:
self.right = Node(val)
# otherwise, search the right subtree and return the result
else:
result = self.right.search(val)
# add the number of elements in the right subtree of the current node to the result
# (since all of these elements are smaller than the given element)
result += self.count - (self.right.count if self.right else 0)
# return the result
return result
# initialize the binary search tree with
? Комментарий: Ого, идейно решение верное. И действительно, задачу можно решить через BST (Binary search tree). Если сравнить с рабочим решением, то код неплох. Да, конечно, можно придраться, что это псевдокод, но смог бы живой человек накропать верно работающий код в рамках собеседования за пару секунд?! Завит от случая! Думаю, что задачу, скорее всего, засчитали бы (но это не точно).
▍ ? Секция SQL (общие вопросы и hard-задача)
?? Задача: Приведи примеры работы оконной функции.
Ответ: Конечно, вот несколько примеров использования функции ROW в SQL:
SELECT ROW(1, 2, 3)— возвращает одну строку с тремя столбцами, содержащими значения 1, 2 и 3.SELECT ROW(col1, col2) FROM table— возвращает строки в таблице со значениями из столбцов col1 и col2 в виде одной строки.SELECT ROW(col1 + col2, col3 - col4) FROM table— возвращает одну строку с двумя столбцами, содержащую результат указанных выражений, применённых к столбцам вtable.
Это всего лишь несколько примеров того, как функция ROW может использоваться в SQL. Это полезная функция для создания строк с определёнными значениями или выражениями на основе столбцов в таблице.
Оригинал ответа


?? Вопрос: Окей, а какие вообще оконные функции бывают?
Ответ: В SQL есть несколько функций строк, которые можно использовать для управления строками данных в таблице. Вот несколько примеров некоторых общих функций строк:
ROW_NUMBER— эта функция присваивает уникальный номер каждой строке в результирующем наборе, начиная с 1 для первой строки. Например,SELECT ROW_NUMBER() OVER (ORDER BY col1) FROM tableприсваивает уникальный номер каждой строке в таблице, упорядоченной по столбцу col1.RANK— эта функция присваивает ранг каждой строке в результирующем наборе на основе значений в указанном столбце. Например,SELECT RANK() OVER (ORDER BY col1) FROM tableприсваивает ранг каждой строке таблицы на основе значений в столбце col1.DENSE_RANK— эта функция похожа на функциюRANK, но она не пропускает ни одного ранга для ничьих. Например,SELECT DENSE_RANK() OVER (ORDER BY col1) FROM tableприсваивает ранг каждой строке в таблице на основе значений в столбце col1, не пропуская ни одного числа для связи.
Это всего лишь несколько примеров функций строк в SQL. Существует множество других функций, которые можно использовать для управления строками данных в таблице, например
FIRST_VALUE, LAST_VALUE, LEAD и LAG.
Оригинал ответа


? Комментарий: Отличный ответ! Такой компактный и чёткий ответ даже загуглить не получится так просто. Кажется, chatGPT умеет преобразовывать своё латентное пространство знаний в настоящий шипучий коктейль информации/знаний.
??? Не будем мелочиться и попросим GPT придумать себе задачу и решить её!
Задача: Можешь сама придумать и решить сложную задачу на SQL c использованием оконной функции?
Ответ: Конечно, вот более сложная табличная задача SQL, включающая функцию
ROW: Выдуманная задача: Напишите запрос SQL для создания новой таблицы с именем
sales, которая содержит следующие столбцы: date, product, quantity и total_price. Столбец date должен содержать дату продажи, столбец product должен содержать название проданного продукта, столбец quantity должен содержать количество проданных единиц, а столбец total_price должен содержать общую цену продажи. Таблица также должна включать столбец с именем row_data, который содержит значения date, product, quantity и total_price для каждой строки в виде одной строки. Чтобы решить эту задачу, вы можете использовать функцию ROW для создания столбца row_data, как показано в следующем запросе:Решение: Чтобы решить эту задачу, можем использовать функцию ROW для создания столбца row_data, как показано в следующем запросе:
CREATE TABLE sales (
date DATE NOT NULL,
product TEXT NOT NULL,
quantity INTEGER NOT NULL,
total_price REAL NOT NULL,
row_data ROW(date, product, quantity, total_price)
);Этот запрос создаёт таблицу с именем
sales с указанными столбцами. Столбцы date, product, quantity и total_price используются для хранения сведений о продажах, а столбец row_data использует функцию ROW для создания одной строки со значениями date, product, quantity и total_price для каждой строки в таблице.
Оригинальный ответ chatGPT
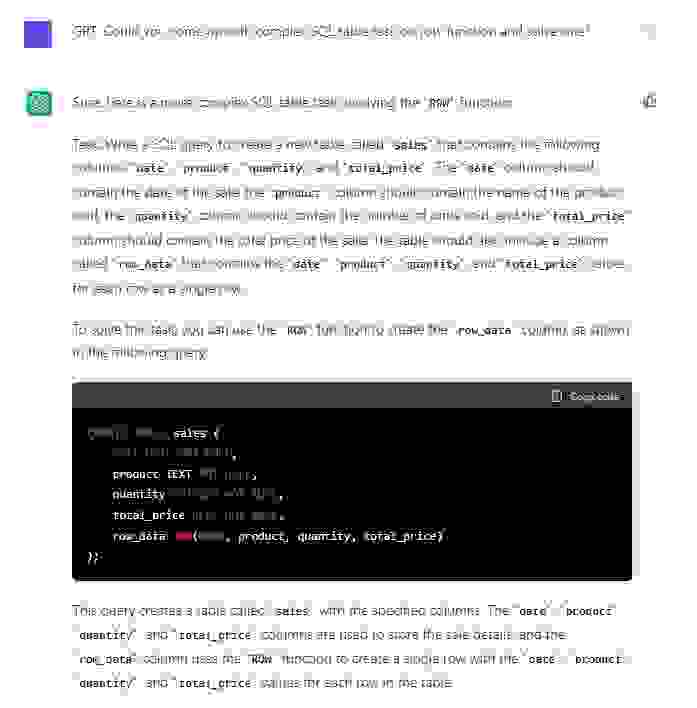

?Комментарий: Очень недурно. Сходу выдумать структуру базы данных с реальными значениями и далее придумать задачку на то, чтобы написать запрос под неё — это впечатлят.
▍ ? Секция Data Science (сразу сложные вопросы!)
? Задача: Расскажи, что такое tf-idf, и потом реализуй этот метод с примерами.
Ответ chatGPT:
from collections import defaultdict
def tf(docs):
# Create a dictionary where the keys are the words in the document
# and the values are their frequencies
tf_values = defaultdict(lambda: 0)
for doc in docs:
for word in doc.split():
tf_values[word] += 1
return tf_values
def idf(docs):
# Create a set of words that appear in at least one document
idf_values = set()
for doc in docs:
for word in doc.split():
idf_values.add(word)
# Calculate the inverse document frequency for each word
idf_values = {word: 1 / len(docs) for word in idf_values}
return idf_values
def tf_idf(docs):
# Calculate the term frequency values for each document
tf_values = tf(docs)
# Calculate the inverse document frequency values for each word
idf_values = idf(docs)
# Calculate the tf-idf values for each word in each document
tf_idf_values = []
for doc in docs:
tf_idf_values.append({word: tf_values[word] * idf_values[word] for word in doc.split()})
return tf_idf_values
# Example usage
docs = [
"this is a sentence",
"this is another sentence",
"yet another sentence"
]
print(tf_idf(docs))Эта реализация вычисляет значения частоты термина (
tf) для каждого слова в каждом документе, значения обратной частоты документа (idf) для каждого слова, а затем объединяет эти значения для вычисления значений tf-idf для каждого слова в каждом документе.? Комментарий: Вау! И это верно! Да я бы сам, если бы не подсмотрел формулу, не ответил. А тут ещё и полная почти корректная реализация, которая работает. Не хватает логарифма, но все равно зачёт!
▍ ? Секция статистики
?Вопрос #1: Когда использовать t-test, а когда z-test?
Ответ: Z-критерий и t-критерий — это два типа тестов статистической гипотезы, которые используются для оценки различий между двумя группами. Z-критерий используется, когда известно стандартное отклонение совокупности, а t-критерий используется, когда стандартное отклонение совокупности неизвестно и должно быть оценено на основе данных выборки. В целом z-критерий используется реже, чем t-критерий, потому что обычно трудно узнать стандартное отклонение генеральной совокупности.
? Комментарий: Верно!
? Вопрос #2: У вас есть 40 карт четырёх цветов: 10 красных, 10 зелёных, 10 синих и 10 жёлтых. Каждый цвет имеет номер от 1 до 10. Когда вы выбираете две карты без замены, какова вероятность того, что две карты не одного цвета и не одного номера?
Давайте тут сразу оригинальный ответ посмотрим!

? Комментарий: Верно? Давайте тут каждый читатель сам подумает и оставит ответ в комментариях, верно решена задача или нет?)
▍ ? Секция ML System Design
?? Вопрос: А задезайни какую-нибудь ML-систему для YouTube, сможешь?
Ответ chatGPT: Чтобы разработать систему машинного обучения для YouTube, нам сначала нужно определить конкретную проблему, для решения которой будет использоваться система. Например, систему можно использовать для рекомендации видео пользователям на основе их предыдущей истории просмотров, для классификации видео по разным категориям для улучшения организации платформы или для обнаружения и удаления неприемлемого или оскорбительного контента.
Как только конкретная проблема будет определена, мы можем приступить к разработке системы машинного обучения. Это будет включать сбор и подготовку набора данных, соответствующих данных YouTube, таких как история просмотров пользователей, метаданные видео и любая другая соответствующая информация. Затем набор данных будет использоваться для обучения модели машинного обучения, такой как алгоритм рекомендации или классификатор, с использованием подходящего метода машинного обучения.
После обучения модели её можно интегрировать в платформу YouTube и использовать для прогнозирования или выполнения действий на основе полученных данных. Систему также необходимо будет регулярно контролировать и обновлять, чтобы гарантировать, что она продолжает работать хорошо, и включать любые новые данные или изменения в платформу.
В целом разработка системы машинного обучения для YouTube будет включать сбор и подготовку данных, обучение модели и интеграцию в платформу, а также постоянный мониторинг и обслуживание.
Оригинальный ответ


? Комментарий: В целом красивый и краткий ответ, можно было бы более развёрнуто ответить, но зато всё по фреймворку: сперва проблема, а потом решение. GPT ответила чётко по вот такому фреймворку:

▍ ? А что по зарплате-то?! Сколько платить?
??? Вопрос: А какие твои зарплатные ожидания?
Ответ: Как крупная языковая модель, обученная OpenAI, у меня нет возможности получать зарплату или иметь зарплатные ожидания. Я цифровой помощник, призванный предоставлять информацию и отвечать на вопросы в меру своих возможностей на основе моего обучения. Моя основная цель — помогать и приносить пользу пользователям, которые взаимодействуют со мной.
▍ ? Выводы и мысли
Можно с уверенностью сказать, что на chatGPT в некоторых вопросах можно опираться при ответе. GPT не поможет вам решать сложные математические задачки на логику, но вот покодить или написать за вас запрос, или просто подсказать вам теорию chatGPT может идеально.
Становится реально страшно, когда ты видишь, что у людей появляется такой мощный инструмент, способный дать им возможность для халявы. Теперь рекрутёрам придётся задавать более сложные вопросы, иначе люди могут просто вбивать их в chatGPT и бездумно отвечать. Кажется, что такой инструмент может сильно увеличить ваши шансы на позиции по типу junior. А возможно, даже поможет и Middle-уровню, если на собеседовании надо много кодить. Можно брать за основу код сетки, а потом уже доредачивать его самому. Круто же!
Спасибо, что дочитал статью до конца. Можешь прислать свой запрос для chatGPT в комментарии, пришлю ответ. А если тебе понравилось, то предлагаю следить за моим Telegram-каналом. Там я рассказываю о практичных вещах из мира Data Science, собеседованиях и соревнованиях на Kaggle.

