
Привет и с возвращением! Это вторая часть статьи о настройке кластера Kubernetes на «голом железе». Ранее мы настраивали НА-кластер Kubernetes с помощью внешнего etcd, схемы «ведущий-ведущий» и балансировки нагрузки. Ну а теперь пришло время настроить дополнительную среду и утилиты, чтобы сделать кластер полезнее и максимально приближенным к рабочему состоянию.
В этой части статьи мы сосредоточимся на настройке внутреннего балансировщика нагрузки сервисов кластера — это будет MetalLB. Также мы установим и настроим распределенное хранилище файлов между нашими рабочими нодами. Будем использовать GlusterFS для постоянных томов, которые доступны в Kubernetes.
После выполнения всех действий схема нашего кластера будет выглядеть следующим образом:
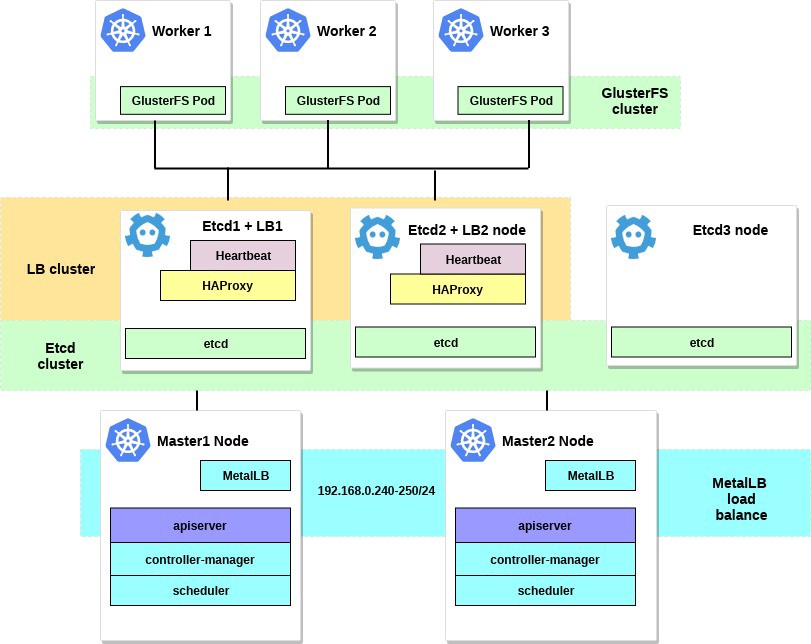
1. Настройка MetalLB в качестве внутреннего балансировщика нагрузки.
Несколько слов о MetalLB, непосредственно со страницы документа:
MetalLB — это реализация балансировщика нагрузки для кластеров Kubernetes на «голом железе» со стандартными протоколами маршрутизации.
Kubernetes не предлагает реализацию сетевых балансировщиков нагрузки (сервис типа LoadBalancer) для «голого железа». Все варианты реализации Network LB, с которыми поставляется Kubernetes, — это связующий код, он обращается к различным платформам IaaS (GCP, AWS, Azure и др.). Если вы не работаете на платформе, поддерживаемой IaaS (GCP, AWS, Azure и др.), LoadBalancer при создании останется в состоянии «ожидания» на неопределенный срок.
Операторы BM-серверов располагают двумя менее эффективными инструментами для ввода трафика пользователя в свои кластеры, сервисы «NodePort» и «externalIPs». Оба этих варианта имеют существенные недостатки в продакшене, что превращает BM-кластеры в граждан второго сорта в экосистеме Kubernetes.
MetalLB стремится исправить этот дисбаланс, предлагая реализацию Network LB, которая интегрируется со стандартным сетевым оборудованием, так что внешние сервисы на BM-кластерах также «просто работают» на максималках.
Таким образом, с помощью этого инструмента мы запускаем сервисы в кластере Kubernetes, используя балансировщик нагрузки, — за что огромное спасибо команде MetalLB. Процесс настройки действительно прост и понятен.
Ранее в примере мы выбрали для нужд нашего кластера подсеть 192.168.0.0/24. Теперь возьмем некоторую часть этой подсети для будущего балансировщика нагрузки.
Входим в систему машины с настроенной утилитой kubectl и запускаем:
control# kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.7.3/manifests/metallb.yamlЭто развернет MetalLB в кластере, в неймспейсе metallb-system. Убедитесь, что все компоненты MetalLB функционируют нормально:
control# kubectl get pod --namespace=metallb-system
NAME READY STATUS RESTARTS AGE
controller-7cc9c87cfb-ctg7p 1/1 Running 0 5d3h
speaker-82qb5 1/1 Running 0 5d3h
speaker-h5jw7 1/1 Running 0 5d3h
speaker-r2fcg 1/1 Running 0 5d3hТеперь настроим MetalLB с помощью configmap. В этом примере мы используем настройку Layer 2. За информацией о других вариантах настройки обращайтесь к документации MetalLB.
Создайте файл metallb-config.yaml в любой директории внутри выбранного IP-диапазона подсети нашего кластера:
control# vi metallb-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: metallb-system
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.0.240-192.168.0.250И примените эту настройку:
control# kubectl apply -f metallb-config.yamlПри необходимости проверьте и измените configmap позднее:
control# kubectl describe configmaps -n metallb-system
control# kubectl edit configmap config -n metallb-systemТеперь у нас есть собственный настроенный локальный балансировщик нагрузки. Проверим, как он работает, на примере сервиса Nginx.
control# vi nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
control# vi nginx-service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
type: LoadBalancer
selector:
app: nginx
ports:
- port: 80
name: httpЗатем создайте тестовый деплой и сервис Nginx:
control# kubectl apply -f nginx-deployment.yaml
control# kubectl apply -f nginx-service.yamlА теперь — проверим результат:
control# kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-deployment-6574bd76c-fxgxr 1/1 Running 0 19s
nginx-deployment-6574bd76c-rp857 1/1 Running 0 19s
nginx-deployment-6574bd76c-wgt9n 1/1 Running 0 19s
control# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx LoadBalancer 10.100.226.110 192.168.0.240 80:31604/TCP 107sСоздано 3 пода Nginx, как мы и указали в деплое ранее. Сервис Nginx будет направлять трафик на все эти поды по схеме циклической балансировки. И вы также можете увидеть внешний IP, полученный от нашего балансировщика нагрузки MetalLB.
Теперь попробуйте свернуться на IP-адрес 192.168.0.240, и вы увидите страницу Nginx index.html. Не забудьте удалить тестовое развертывание и сервис Nginx.
control# kubectl delete svc nginx
service "nginx" deleted
control# kubectl delete deployment nginx-deployment
deployment.extensions "nginx-deployment" deletedХорошо, на этом с MetalLB всё, идем дальше — настроим GlusterFS для томов Kubernetes.
2. Настройка GlusterFS с Heketi на рабочих нодах.
По факту, кластер Kubernetes невозможно юзать без томов внутри него. Как вы знаете, поды — эфемерны, т.е. их можно создать и удалить в любой момент. Все данные внутри них будут потеряны. Таким образом, в реальном кластере потребуется распределенное хранилище, чтобы обеспечить обмен настройками и данными между нодами и приложениями внутри него.
В Kubernetes тома доступны в различных вариантах, выбирайте подходящие. В этом примере я продемонстрирую, как создается хранилище GlusterFS для любых внутренних приложений, оно — как постоянные тома. Ранее я использовал для этого «системную» установку GlusterFS на всех рабочих нодах Kubernetes, а затем просто создавал тома типа hostPath в каталогах GlusterFS.
Теперь у нас есть новый удобный инструмент Heketi.
Несколько слов из документации Heketi:
Инфраструктура управления томами на основе RESTful для GlusterFS.
Heketi предлагает интерфейс управления RESTful, который можно использовать для управления жизненным циклом томов GlusterFS. Благодаря Heketi облачные сервисы, например OpenStack Manila, Kubernetes и OpenShift, могут динамически предоставлять тома GlusterFS с любым поддерживаемым типом надежности. Heketi автоматически определяет местоположение блоков в кластере, обеспечивая расположение блоков и их реплик в разных областях отказов. Heketi также поддерживает любое количество кластеров GlusterFS, позволяя облачным сервисам предлагать сетевое хранилище файлов, не ограничиваясь единственным кластером GlusterFS.
Звучит неплохо, и, кроме того, этот инструмент приблизит наш ВМ-кластер к большим облачным кластерам Kubernetes. В конце концов вы сможете создавать PersistentVolumeClaims, которые будут формироваться автоматически, и многое другое.
Можно взять дополнительные системные жесткие диски для настройки GlusterFS или просто создать несколько фиктивных блочных устройств. В этом примере я воспользуюсь вторым методом.
Создайте фиктивные блочные устройства на всех трех рабочих нодах:
worker1-3# dd if=/dev/zero of=/home/gluster/image bs=1M count=10000Вы получите файл размером около 10 ГБ. Затем используйте losetup — чтобы добавить его в эти ноды, в качестве петлевого устройства:
worker1-3# losetup /dev/loop0 /home/gluster/imageОбратите внимание: если у вас уже есть некое петлевое устройство 0, то вам потребуется выбрать любой другой номер.
Я не пожалел времени и выяснил, почему Heketi не хочет работать должным образом. Поэтому, чтобы предотвратить любые проблемы в будущих конфигурациях, сначала убедимся, что мы загрузили модуль ядра dm_thin_pool и установили пакет glusterfs-client на всех рабочих нодах.
worker1-3# modprobe dm_thin_pool
worker1-3# apt-get update && apt-get -y install glusterfs-clientХорошо, теперь нужно, чтобы на всех рабочих нодах присутствовали файл /home/gluster/image и устройство /dev/loop0. Не забудьте создать сервис systemd, которая будет автоматически запускать losetup и modprobe при каждой загрузке этих серверов.
worker1-3# vi /etc/systemd/system/loop_gluster.service
[Unit]
Description=Create the loopback device for GlusterFS
DefaultDependencies=false
Before=local-fs.target
After=systemd-udev-settle.service
Requires=systemd-udev-settle.service
[Service]
Type=oneshot
ExecStart=/bin/bash -c "modprobe dm_thin_pool && [ -b /dev/loop0 ] || losetup /dev/loop0 /home/gluster/image"
[Install]
WantedBy=local-fs.targetИ включите ее:
worker1-3# systemctl enable /etc/systemd/system/loop_gluster.service
Created symlink /etc/systemd/system/local-fs.target.wants/loop_gluster.service → /etc/systemd/system/loop_gluster.service.Подготовительные работы закончены, и мы готовы деплоить GlusterFS и Heketi в наш кластер. Для этого я буду использовать вот это прикольное руководство. Большинство команд запускаем с внешнего управляющего компьютера, а очень маленькие команды запускаются с любой мастер-ноды внутри кластера.
Сначала скопируем репозиторий и создадим DaemonSet GlusterFS:
control# git clone https://github.com/heketi/heketi
control# cd heketi/extras/kubernetes
control# kubectl create -f glusterfs-daemonset.jsonТеперь пометим наши три рабочие ноды для GlusterFS; после нанесения меток на них будут созданы поды GlusterFS:
control# kubectl label node worker1 storagenode=glusterfs
control# kubectl label node worker2 storagenode=glusterfs
control# kubectl label node worker3 storagenode=glusterfs
control# kubectl get pod
NAME READY STATUS RESTARTS AGE
glusterfs-5dtdj 1/1 Running 0 1m6s
glusterfs-hzdll 1/1 Running 0 1m9s
glusterfs-p8r59 1/1 Running 0 2m1sТеперь создадим учетную запись сервиса Heketi:
control# kubectl create -f heketi-service-account.jsonОбеспечим для этой учетной записи сервиса возможность управлять подами gluster. Для этого создадим кластерную функцию, обязательную для нашей только что созданной учетной записи сервиса:
control# kubectl create clusterrolebinding heketi-gluster-admin --clusterrole=edit --serviceaccount=default:heketi-service-accountТеперь давайте создадим секретный ключ Kubernetes, который блокирует конфигурацию нашего экземпляра Heketi:
control# kubectl create secret generic heketi-config-secret --from-file=./heketi.jsonСоздайте первый исходный под Heketi, который мы используем для первых операций по настройке и впоследствии удалим:
control# kubectl create -f heketi-bootstrap.json
service "deploy-heketi" created
deployment "deploy-heketi" created
control# kubectl get pod
NAME READY STATUS RESTARTS AGE
deploy-heketi-1211581626-2jotm 1/1 Running 0 2m
glusterfs-5dtdj 1/1 Running 0 6m6s
glusterfs-hzdll 1/1 Running 0 6m9s
glusterfs-p8r59 1/1 Running 0 7m1sПосле создания и запуска сервиса Bootstrap Heketi нам потребуется перейти на один из наших мастер-нодов, там мы запустим несколько команд, поскольку наш внешний управляющий нод не находится внутри нашего кластера, поэтому мы не можем получить доступ к работающим подам и внутренней сети кластера.
Сначала давайте загрузим утилиту heketi-client и скопируем ее в системную папку bin:
master1# wget https://github.com/heketi/heketi/releases/download/v8.0.0/heketi-client-v8.0.0.linux.amd64.tar.gz
master1# tar -xzvf ./heketi-client-v8.0.0.linux.amd64.tar.gz
master1# cp ./heketi-client/bin/heketi-cli /usr/local/bin/
master1# heketi-cli
heketi-cli v8.0.0Теперь найдем IP-адрес пода heketi и экспортируем его как системную переменную:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf describe pod deploy-heketi-1211581626-2jotm
For me this pod have a 10.42.0.1 ip
master1# curl http://10.42.0.1:57598/hello
Handling connection for 57598
Hello from Heketi
master1# export HEKETI_CLI_SERVER=http://10.42.0.1:57598Теперь давайте предоставим Heketi информацию о кластере GlusterFS, которым он должен управлять. Мы предоставляем ее через файл топологии. Топология — это манифест JSON со списком всех нод, дисков и кластеров, используемых GlusterFS.
ПРИМЕЧАНИЕ. Убедитесь, чтоhostnames/manageуказывает на точное название, как в разделеkubectl get node, и чтоhostnames/storage— это IP-адрес нодов хранилища.
master1:~/heketi-client# vi topology.json
{
"clusters": [
{
"nodes": [
{
"node": {
"hostnames": {
"manage": [
"worker1"
],
"storage": [
"192.168.0.7"
]
},
"zone": 1
},
"devices": [
"/dev/loop0"
]
},
{
"node": {
"hostnames": {
"manage": [
"worker2"
],
"storage": [
"192.168.0.8"
]
},
"zone": 1
},
"devices": [
"/dev/loop0"
]
},
{
"node": {
"hostnames": {
"manage": [
"worker3"
],
"storage": [
"192.168.0.9"
]
},
"zone": 1
},
"devices": [
"/dev/loop0"
]
}
]
}
]
}Затем загрузите этот файл:
master1:~/heketi-client# heketi-cli topology load --json=topology.json
Creating cluster ... ID: e83467d0074414e3f59d3350a93901ef
Allowing file volumes on cluster.
Allowing block volumes on cluster.
Creating node worker1 ... ID: eea131d392b579a688a1c7e5a85e139c
Adding device /dev/loop0 ... OK
Creating node worker2 ... ID: 300ad5ff2e9476c3ba4ff69260afb234
Adding device /dev/loop0 ... OK
Creating node worker3 ... ID: 94ca798385c1099c531c8ba3fcc9f061
Adding device /dev/loop0 ... OKДалее мы используем Heketi, чтобы предоставить тома для хранения базы данных. Название команды немного странное, но все в порядке. Также создайте хранилище heketi:
master1:~/heketi-client# heketi-cli setup-openshift-heketi-storage
master1:~/heketi-client# kubectl --kubeconfig /etc/kubernetes/admin.conf create -f heketi-storage.json
secret/heketi-storage-secret created
endpoints/heketi-storage-endpoints created
service/heketi-storage-endpoints created
job.batch/heketi-storage-copy-job createdЭто все команды, которые нужно запустить с мастер-ноды. Вернемся к управляющей ноде и продолжим оттуда; в первую очередь убедитесь, что последняя запущенная команда успешно выполнена:
control# kubectl get pod
NAME READY STATUS RESTARTS AGE
glusterfs-5dtdj 1/1 Running 0 39h
glusterfs-hzdll 1/1 Running 0 39h
glusterfs-p8r59 1/1 Running 0 39h
heketi-storage-copy-job-txkql 0/1 Completed 0 69sИ задание heketi-storage-copy-job выполнено.
Если на данный момент на ваших рабочих нодах отсутствует установленный пакет glusterfs-client, то имеет место ошибка.
Пришло время удалить установочный файл Bootstrap Heketi и произвести небольшую очистку:
control# kubectl delete all,service,jobs,deployment,secret --selector="deploy-heketi"На последнем этапе нам нужно создать долгосрочный экземпляр Heketi:
control# cd ./heketi/extras/kubernetes
control:~/heketi/extras/kubernetes# kubectl create -f heketi-deployment.json
secret/heketi-db-backup created
service/heketi created
deployment.extensions/heketi created
control# kubectl get pod
NAME READY STATUS RESTARTS AGE
glusterfs-5dtdj 1/1 Running 0 39h
glusterfs-hzdll 1/1 Running 0 39h
glusterfs-p8r59 1/1 Running 0 39h
heketi-b8c5f6554-knp7t 1/1 Running 0 22mЕсли на данный момент на ваших рабочих нодах отсутствует установленный пакет glusterfs-client, то имеет место ошибка. А мы почти закончили, теперь база данных Heketi сохраняется в томе GlusterFS и не сбрасывается при каждом перезапуске пода Heketi.
Чтобы начать использовать кластер GlusterFS с динамическим выделением ресурсов, нам нужно создать StorageClass.
Сначала давайте найдем конечную точку хранилища Gluster, которая будет передана в StorageClass в качестве параметра (heketi-storage-endpoints):
control# kubectl get endpoints
NAME ENDPOINTS AGE
heketi 10.42.0.2:8080 2d16h
....... ... .. Теперь создайте несколько файлов:
control# vi storage-class.yml
apiVersion: storage.k8s.io/v1beta1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/glusterfs
parameters:
resturl: "http://10.42.0.2:8080"
control# vi test-pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: gluster1
annotations:
volume.beta.kubernetes.io/storage-class: "slow"
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1GiИспользуйте эти файлы для создания class и pvc:
control# kubectl create -f storage-class.yaml
storageclass "slow" created
control# kubectl get storageclass
NAME PROVISIONER AGE
slow kubernetes.io/glusterfs 2d8h
control# kubectl create -f test-pvc.yaml
persistentvolumeclaim "gluster1" created
control# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE gluster1 Bound pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO slow 2d8hМы также можем просмотреть том PV:
control# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO Delete Bound default/gluster1 slow 2d8hТеперь у нас есть динамически созданный том GlusterFS, связанный с PersistentVolumeClaim, и мы можем использовать это утверждение в любом поде.
Создайте простой под Nginx и протестируйте его:
control# vi nginx-test.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod1
labels:
name: nginx-pod1
spec:
containers:
- name: nginx-pod1
image: gcr.io/google_containers/nginx-slim:0.8
ports:
- name: web
containerPort: 80
volumeMounts:
- name: gluster-vol1
mountPath: /usr/share/nginx/html
volumes:
- name: gluster-vol1
persistentVolumeClaim:
claimName: gluster1
control# kubectl create -f nginx-test.yaml
pod "nginx-pod1" createdПросмотрите под (подождите несколько минут, возможно, потребуется загрузить образ, если он еще не существует):
control# kubectl get pods
NAME READY STATUS RESTARTS AGE
glusterfs-5dtdj 1/1 Running 0 4d10h
glusterfs-hzdll 1/1 Running 0 4d10h
glusterfs-p8r59 1/1 Running 0 4d10h
heketi-b8c5f6554-knp7t 1/1 Running 0 2d18h
nginx-pod1 1/1 Running 0 47hТеперь войдите в контейнер и создайте файл index.html:
control# kubectl exec -ti nginx-pod1 /bin/sh
# cd /usr/share/nginx/html
# echo 'Hello there from GlusterFS pod !!!' > index.html
# ls
index.html
# exitПотребуется найти внутренний IP-адрес пода и свернуться в него из любой мастер-ноды:
master1# curl 10.40.0.1
Hello there from GlusterFS pod !!!При этом мы просто тестируем наш новый постоянный том.
Несколько полезных команд для проверки нового кластера GlusterFS:heketi-cli cluster listиheketi-cli volume list. Их можно запустить на своем компьютере при наличии установленного heketi-cli. В данном примере это нода master1.
master1# heketi-cli cluster list
Clusters:
Id:e83467d0074414e3f59d3350a93901ef [file][block]
master1# heketi-cli volume list
Id:6fdb7fef361c82154a94736c8f9aa53e Cluster:e83467d0074414e3f59d3350a93901ef Name:vol_6fdb7fef361c82154a94736c8f9aa53e
Id:c6b69bd991b960f314f679afa4ad9644 Cluster:e83467d0074414e3f59d3350a93901ef Name:heketidbstorageНа этом этапе мы успешно настроили внутренний балансировщик нагрузки с файловым хранилищем, и наш кластер теперь ближе к рабочему состоянию.
В следующей части статьи мы сосредоточимся на создании системы мониторинга кластера, а также запустим в нем тестовый проект для использования всех настроенных нами ресурсов.
Оставайтесь на связи, и всего хорошего!
