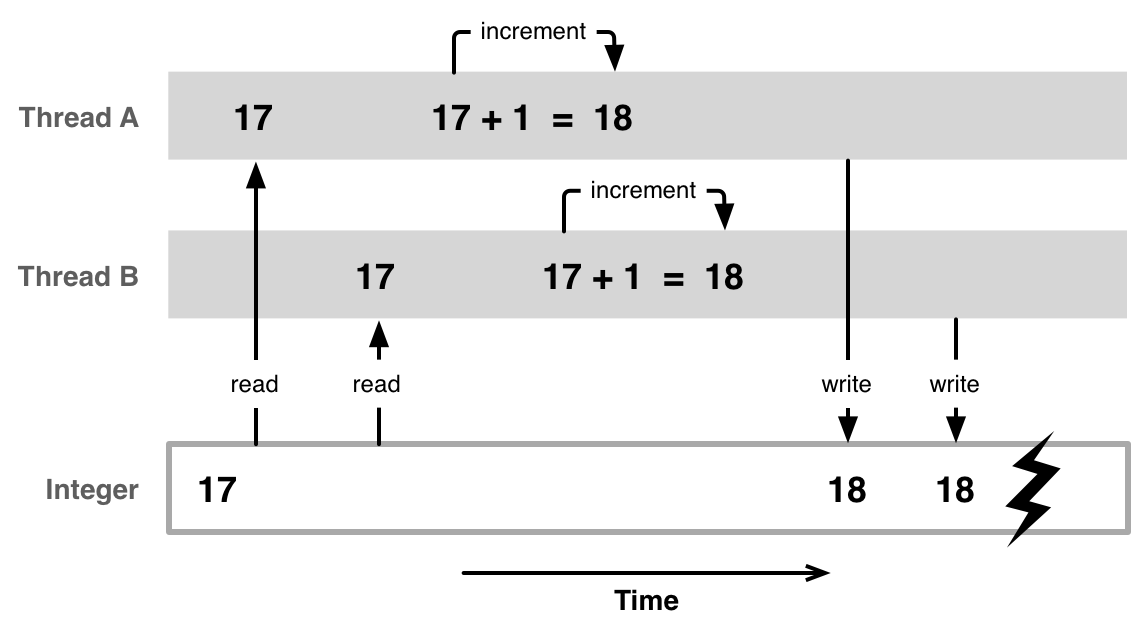
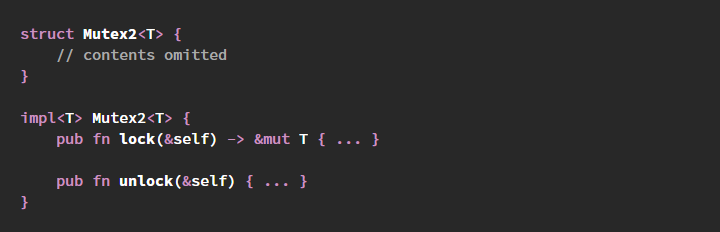
Я часто слышу от пробующих работать с Rust системных программистов жалобы на
мьютексы и особенно на Rust Mutex API. Жалобы обычно выглядят так:
- Они не хотят, чтобы мьютекс содержал данные, только блокировку.
- Они не хотят управлять «защитным» значением, разблокирующим мьютекс при сбросе, в частности, они просто хотят вызывать операцию
unlock, потому что им кажется, что это более явное действие.
Такие изменения превратили бы Rust mutex API в эквивалент C/Posix mutex API. Однажды я даже видел, как один разработчик пытался использовать
Mutex<()> и разные хитрости, чтобы его имитировать.
Однако у такого стремления есть проблема: эти два аспекта
Mutex неразрывно связаны друг с другом, а также с гарантиями безопасности Rust в целом — изменение одного из них или обоих откроет возможности для возникновения незаметных багов и повреждений из-за гонок данных.
Использование API мьютексов в стиле C, состоящего из набора косвенно защищаемых данных и из функций
lock и
unlock было бы опрометчивым в Rust, потому что это позволяет безопасному коду легко вносить ошибки, нарушающие безопасность памяти и вызывающие гонки данных.
Прозвучит спорно, но я утверждаю, что
это справедливо и для C. Просто в Rust это более очевидно, поскольку Rust тщательно разделяет понятия «безопасного» кода, в который невозможно внести подобные ошибки, и «небезопасного» кода, в который
можно вносить такие ошибки. В C такого разделения нет, и в результате этого использующий мьютексы код на C может тривиальным образом создавать серьёзные баги, которые потенциально можно подвергать эксплойтам.
В этом посте я разберу типичный C mutex API, сравню его с типичным Rust mutex API, и расскажу о том, что произойдёт, если мы изменим Rust API так, чтобы он напоминал C.