
Знакомство с Fugue — уменьшаем шероховатости при работе с PySpark
15 мин
Туториал
Перевод

Автор оригинальной статьи: Kevin Kho
Повышение производительности разработчиков и снижение затрат на проекты Big Data
Автор оригинальной статьи: Kevin Kho
Повышение производительности разработчиков и снижение затрат на проекты Big Data

Pandas - одна из наиболее используемых библиотек Python с открытым исходным кодом для работы со структурированными табличными данными для анализа. Однако он не поддерживает распределенную обработку, поэтому вам всегда придется увеличивать ресурсы, когда вам понадобится дополнительная мощность для поддержки растущих данных. И всегда наступит момент, когда ресурсов станет недостаточно. В данной статье мы рассмотрим, как PySpark выручает в условиях нехватки мощностей для обработки данных.
Ну что же, приступим...

И снова здравствуй, Хабр! Сегодня поговорим об актуальной для многих из нас проблеме при работе с базами данных. В ходе работы над разными проектами часто приходится создавать базу данных (командное пространство, песочница и т.п.), которую использует как сам автор, так и/или коллеги для временного хранения данных. Как у любого «помещения», в нашей «песочнице» есть своё ограничение по объёму выделенного места для хранения данных. Периодически бывает так, что вы или ваши коллеги забываете об этом маленьком ограничении, из-за чего, к сожалению, заканчивается объём выделенной памяти.
В этом случае можно применить маленький лайфхак, который позволит оперативно просмотреть, какая таблица больше всего занимает место, кто её владелец, как долго она находится в общей песочнице и т.д. Используя его, вы оперативно сможете почистить место в песочнице, предварительно согласовав действия с владельцем данных без нанесения вреда данным остальных коллег. Кроме того, этот инструмент позволит периодически проводить мониторинг наполняемости вашей общей песочницы.

Привет, Хабр! Меня зовут Борис Мурашин, я системный архитектор развития платформы больших данных в Х5 Tech. В статье делюсь своим опытом работы с кластером Hadoop: рассказываю, как с помощью сторонней библиотеки мне удалось организовать оперативную выгрузку образа файловой системы HDFS в Hive. И не только про это. Надеюсь, что мои инструкции помогут другим сэкономить массу времени в работе с кластером.
Сколько места на диске используют таблицы Hive в HDFS? В каких из них много мелких файлов? Какая динамика у этих цифр? Что происходит в домашних каталогах пользователей? Кто прямо сейчас создаёт таблицу с партиционированием по timestamp и скоро «уложит» нэймноду по GC pause? Давайте разбираться.

Привет, username! Меня зовут Иван Васенков и я джуниор дата-инженер в дирекции данных и аналитики Lamoda. Но к этой профессии я пришел не сразу: окончив университет, я начал работать аналитиком данных, затем стал BI-разработчиком, а уже после этого — дата-инженером.
На моем пути были простые и сложные участки: где-то помогал опыт предыдущей работы, а где-то приходилось доучиваться практически на ходу. Именно поэтому я хочу поделиться советами из своего опыта, которые помогут начинающим специалистам быть максимально готовыми к вступлению в мир дата-инжиниринга.
Очень часто приходится слышать, что Sqoop — это серебряная пуля для загрузки данных большого объёма с реляционных БД в Hadoop, особенно с Oracle, и Spark-ом невозможно достигнуть такой производительности. При этом приводят аргументы, что sqoop — это инструмент, заточенный под загрузку, а Spark предназначен для обработки данных.
Меня зовут Максим Петров, я руководитель департамента "Чаптер инженеров данных и разработчиков", и я решил написать инструкцию о том, как правильно и быстро загружать данные Spark, основываясь на принципах загрузки Sqoop.
Первичное сравнение технологий
В нашем примере будем рассматривать загрузку данных из таблиц OracleDB.
Рассмотрим случай, когда нам необходимо полностью перегрузить таблицу/партицию на кластер Hadoop c созданием метаданных hive.

Привет, Хабр! Меня зовут Денис, в компании oneFactor я занимаю позицию архитектора, и одна из моих обязанностей — это развитие технического стека компании. В этой статье я расскажу про нашу data platform’у (далее просто DP или платформа) и про мотивацию внедрения в неё Kubernetes. Также подсвечу трудности, с которыми мы столкнулись в рамках пилота. И расскажу про набор активностей, которые не вошли в пилот, но будут выполнены во время миграции. Дополнительно представлю короткий обзор текущей интеграции между Spark и Kubernetes. Стоит отметить, что вопросы, связанные с хранилищем, здесь обсуждаться не будут.

В задачах построения и развития Data Platform с течением времени мы всегда приходим к вопросу эффективного управления данными.
Chief Data Officer, задавшись целью развить, вывести на новый уровень функцию управления данными, склоняются к “тяжеловесным” шагам, внедряя дорогостоящее вендорское ПО или начиная собственную разработку инструментов.
В то же время в открытом доступе есть законченные, испытанные временем продукты, с которых можно начать испытывать и развивать процессы и компетенции в области Data Governance, применив минимум затрат на внедрение и двигаясь поступательно методом “маленьких побед”.
Apache Atlas является одним из таких доступных open source-инструментов класса Data Catalog, который нам удалось полноценно опробовать и успешно замкнуть на него ряд процессов управления данными.

В предыдущей статье я поделился нашим опытом создания аналитического хранилища полного цикла на базе экосистемы Hadoop. Одним из тезисов той статьи стало утверждение о том, что аналитическую систему можно спроектировать, не прибегая к федерализации разных технологических платформ, предназначенных для решения локальных задач.
В этом материале я попробую подробнее раскрыть, как в нашей системе реализован подход обработки и загрузки данных в реальном времени с использованием технологии Kudu, при котором эти данные сразу доступны для анализа.


Часто перед дата-инженерами ставится задача по миграции данных из какого-либо источника или системы в целевое хранилище. Для этого существует множество различных инструментов. Если говорить про платформу Big Data, то чаще всего у разработчиков на слуху Apache NiFi или ETL-задачи, написанные на Spark, ввиду универсальности этих инструментов. Но давайте предположим, что нам необходимо провести миграцию данных из РСУБД в Hadoop. Для подобного рода задач существует очень недооцененный пакетный ETL-инструмент – Apache Sqoop. Его особенность в следующем:

Cloudera Streaming Analytics: унификация пакетной и потоковой обработки в SQL
В октябре 2020 года Cloudera приобрела компанию Eventador, а в начале 2021 года был выпущен продукт Cloudera Streaming Analytics (CSA) 1.3.0. Это был первый релиз, который включал в себя SQL Stream Builder (SSB), полученный в результате интеграции наработок Eventador в продукт для аналитики потоквых данных на базе Apache Flink.
SQL Stream Builder (SSB) - это новый компонент со своим дружелюбным веб-интерфейсом, позволяющий анализировать потоковые и исторические данные в режиме реального времени в SQL, под капотом которого работает Apache Flink.

Всем привет! Я Игорь Гончаров — руководитель Службы управления данными Уралсиба. В этой статье я поделился нашим видением ответа на вопрос, который периодически слышу от коллег: зачем мы развиваем хранилище данных банка, когда есть технологии Data Lake?

Kafka нельзя назвать новым продуктом на рынке ПО. Прошло примерно 10 лет с того времени, как компания разработчик LinkedIn выпустила его в свет. И хотя к тому времени на рынке уже были продукты со схожей функциональностью, но открытый код и широкая поддержка экспертного сообщества прежде всего в лице Apache Incubator позволила ему быстро встать на ноги, а впоследствии составить серьезную конкуренцию альтернативным решениям.
Традиционно Kafka рассматривался как набор сервисов для приема и передачи данных, позволяющий накапливать, хранить и отдавать данные с крайне низкой задержкой и высокой пропускной способностью. Этакий надежный и быстрый (да и в общем-то наиболее популярный на данный момент) брокер сообщений по этой причине весьма востребован во множестве ETL процессов. Преимущества и возможности Kafka многократно обсуждались, в том числе и на Хабре. К тому же, статей на данную тематику весьма много на просторах интернета. Не будем повторять здесь достоинства Kafk-и, достаточно посмотреть на список организаций, выбравших этот продукт базовым инструментом для технических решений. Обратимся к официальному сайту, согласно которому на данный момент Kafka используется тысячами компаний, в том числе более 60% компаний из списка Fortune 100. Среди них Box, Goldman Sachs, Target, Cisco, Intuit и другие [1].
На сегодняшний день Apache Kafkaне без оснований часто признается лучшим продуктом на рынке систем по передаче данных. Но Kafka не только интересен в качестве брокера сообщений. Огромный интерес он представляет и в силу того, что на его основе возникли и развиваются многие специфические программные продукты, которые позволяют Kafka существенным образом расширить возможности. А это свою очередь позволяет ему уверено продвигаться в новые области ИT рынка.

В статье будет рассмотрен процесс экспорта данных в Hadoop из различных РСУБД посредством фреймворка Spark. Для взаимодействия с фреймворком Spark будет использован язык программирования Python с применением api pySpark.
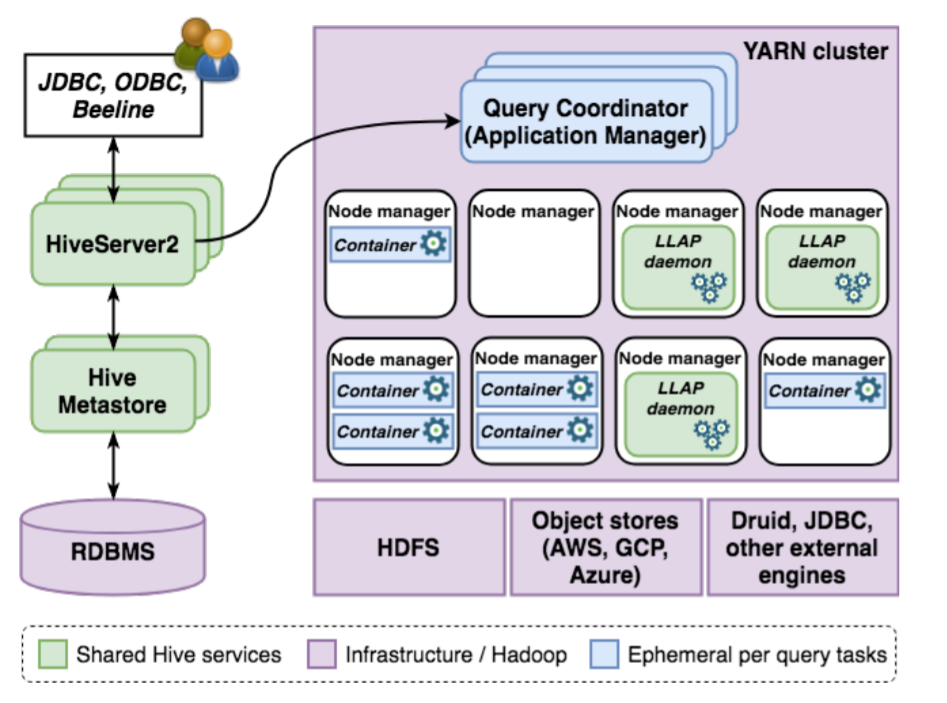
Обзор
Apache Hive – система управления (СУБД) реляционными базами данных (РБД) с открытым исходным кодом для запросов, агрегирования и анализа параметров и режимов рабочих нагрузок с большими данными. В этой статье описываются ключевые инновационные инструменты для полноценной пакетной обработки в корпоративной системе хранения данных. Мы представляем гибридную архитектуру, которая сочетает в себе традиционные методы массивно-параллельных архитектур (MPP) с физически разделенной памятью с более современными концепциями больших данных, облаков для достижения масштабируемости и производительности, требуемых современными аналитическими приложениями. Мы исследуем систему, подробно описывая улучшения по четырем основным направлениям: транзакция, оптимизатор, среда выполнения и федерация (интеграционный процесс). Затем мы приводим экспериментальные результаты, чтобы продемонстрировать производительность системы для типовых рабочих нагрузок, и в заключение рассмотрим дорожную карту сообщества.

Выпуск версии Cloudera Data Platform (CDP) Private Cloud Base означает появление гибридной облачной архитектуры следующего поколения. Ниже представлен обзор методов проектирования и развертывания кластеров («лучшие практики»), включая конфигурацию оборудования и операционной системы, а также руководство по организации сети и построению системы безопасности, интеграции с существующей корпоративной инфраструктурой.

Недавно в своей работе начал практиковаться с Hadoop, Spark и Hive от Apache на примере организации распределенного хранилища данных в крупном и сложном проекте. Так как я хорошо дружу с Linux и вселенной Docker, только одна команда позволит не мучиться с лишней установкой Big Data-решении от Apache, не нагружая при этом свою Linux-машину(при наличии Docker и Docker-Compose).

Единая биометрическая система (ЕБС) с 2018 года используется для идентификации человека по его биометрическим характеристикам: голосу и лицу.
Чтобы получать услуги по биометрии, пользователю необходимо зарегистрироваться в системе в одном из 13,1 тысяч отделений банков. Там операционист сделает его фотографию, запишет голос и отправит эти данные в систему. А для того чтобы компании могли оказывать по биометрии различные услуги, им необходимо провести интеграцию с ЕБС.
Оператором системы является «Ростелеком», а разработкой занимаемся мы – дочерняя компания РТЛабс .
Меня зовут Сергей Браун, я заместитель директора департамента цифровой идентичности в РТЛабс. Вместе с Артуром Душелюбовым, начальником отдела развития и разработки департамента цифровой идентичности, мы расскажем, как мы создавали платформу для любой биометрии, с какими проблемами встретились и как их решали.
Регулируемые отрасли и правительственные организации по всему миру доверяют Cloudera хранение и анализ петабайтов данных - очень важной или конфиденциальной информации о людях, персональных и медицинских данных, финансовых данных или просто служебной информации, конфиденциальной для самого клиента.
Любой, кто хранит информацию о клиентах, медицинскую, финансовую или конфиденциальную информацию, должен убедиться, что приняты необходимые меры для защиты этих данных, включая обнаружение и предотвращение непреднамеренного или злонамеренного доступа. Согласно исследованию Ponemon Institute, за два года в мире средний ущерб от инсайдерских угроз вырос на 31% и достиг 11,45 миллиона долларов, а частота инцидентов за тот же период увеличилась на 47%. В отчете за 2019 год указано, что компании больше всего беспокоятся о непреднамеренных нарушениях со стороны инсайдеров (71%), утечках данных из-за небрежности (65%) и злонамеренных действиях злоумышленников (60%), чем о взломанных учетных записях или машинах (9%).
В этой статье мы разберем как правильно интегрировать платформу CDP с внешними SIEM системами.