
Идёт? Бежит? Поднимается по лестнице? Intel Edison знает ответ
5 мин
Перевод
Сегодня мы расскажем о проекте, нацеленном на распознавание некоторых видов физической активности человека. Делается это с помощью платы Intel Edison, к которой подключён акселерометр ADXL345.

Данные о том, чем именно занят пользователь, способны найти множество применений. Особенно это касается сферы носимой электроники. Например, в среде здравоохранения такие сведения можно использовать для наблюдения за пациентами, в спорте – для анализа особенностей выполнения упражнений и фитнес-трекинга.
В нашем проекте для анализа данных акселерометра используется метод опорных векторов (Support Vector Machine, SVM). Программная часть реализована с применением популярной библиотеки LIBSVM. Код написан в двух вариантах: на Python и Node.js.
Данные о том, чем именно занят пользователь, способны найти множество применений. Особенно это касается сферы носимой электроники. Например, в среде здравоохранения такие сведения можно использовать для наблюдения за пациентами, в спорте – для анализа особенностей выполнения упражнений и фитнес-трекинга.
В нашем проекте для анализа данных акселерометра используется метод опорных векторов (Support Vector Machine, SVM). Программная часть реализована с применением популярной библиотеки LIBSVM. Код написан в двух вариантах: на Python и Node.js.
 Ранее мы описали клеточный автомат, в котором могут возникать волны, имеющие хитрый внутренний узор. Мы показали, что такие волны способны распространять информацию по поверхности автомата. Оказалось, что любое место автомата может быть, как приемником, так и источником волн. Чтобы принять волну в каком-либо месте, достаточно посмотреть, какой узор получается в нем в момент прохождения волны. Если этот узор запомнить и впоследствии воспроизвести в том же месте, то от этого узора распространится волна, повторяющая на своем пути узор исходной волны.
Ранее мы описали клеточный автомат, в котором могут возникать волны, имеющие хитрый внутренний узор. Мы показали, что такие волны способны распространять информацию по поверхности автомата. Оказалось, что любое место автомата может быть, как приемником, так и источником волн. Чтобы принять волну в каком-либо месте, достаточно посмотреть, какой узор получается в нем в момент прохождения волны. Если этот узор запомнить и впоследствии воспроизвести в том же месте, то от этого узора распространится волна, повторяющая на своем пути узор исходной волны.

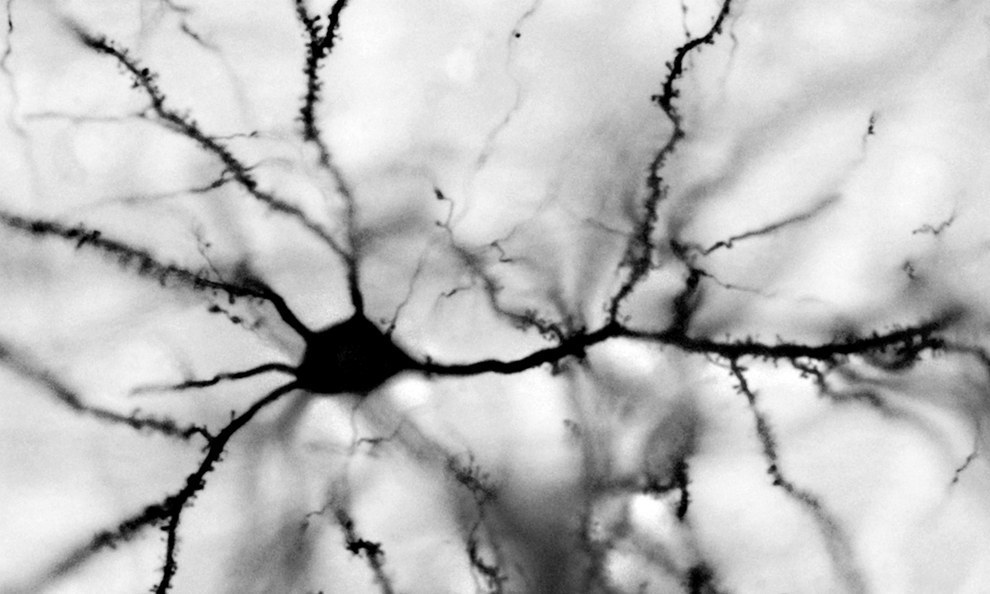 В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.
В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.



 Начнем разговор о мозге с несколько отвлеченной темы. Поговорим о клеточных автоматах. Клеточный автомат – это дискретная модель, которая описывает регулярную решетку ячеек, возможные состояния ячеек и правила изменений этих состояний. Каждая из ячеек может принимать конечное множество состояний, например, 0 и 1. Для каждой из ячеек определяется окрестность, задающая ее соседей. Состояние соседей и собственное состояние ячейки определяют ее следующее состояние.
Начнем разговор о мозге с несколько отвлеченной темы. Поговорим о клеточных автоматах. Клеточный автомат – это дискретная модель, которая описывает регулярную решетку ячеек, возможные состояния ячеек и правила изменений этих состояний. Каждая из ячеек может принимать конечное множество состояний, например, 0 и 1. Для каждой из ячеек определяется окрестность, задающая ее соседей. Состояние соседей и собственное состояние ячейки определяют ее следующее состояние.