
Могут ли все финансовые модели быть ошибочными: 7 источников риска возникновения убытков
9 мин
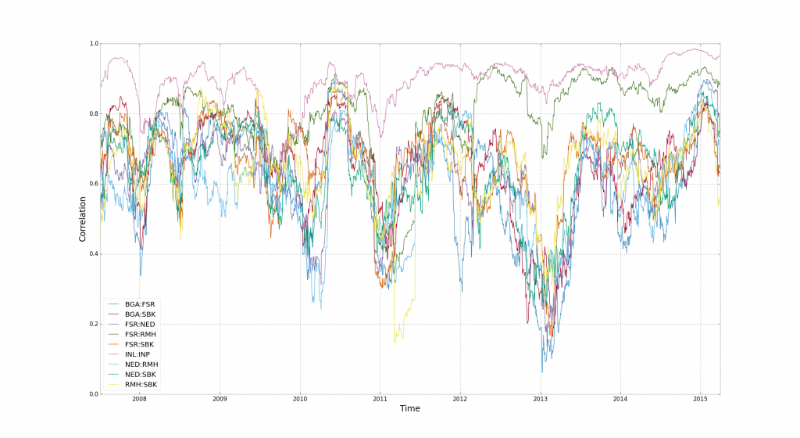
На Хабре и в аналитическом разделе нашего сайта мы много пишем о тенденциях финансового рынка и стратегиях поведения на нем. Очень часто финансовые модели, так или иначе, построены на умозрительных заключениях. И то, насколько сильно модель полагается на такие данные, зависит ее пригодность для использования. Этот показатель можно рассчитать при помощи риска модели.
Создатель сайта Turing Finance и аналитик хедж-фонда NMRQL Стюарт Рид опубликовал интересный материал на тему анализа возможных рисков использования финансовых моделей. В материале рассматриваются несколько факторов, влияющих на возникновения рисков — то есть вероятности финансовых потерь при использовании модели. Мы представляем вашему вниманию главные моменты этой работы.




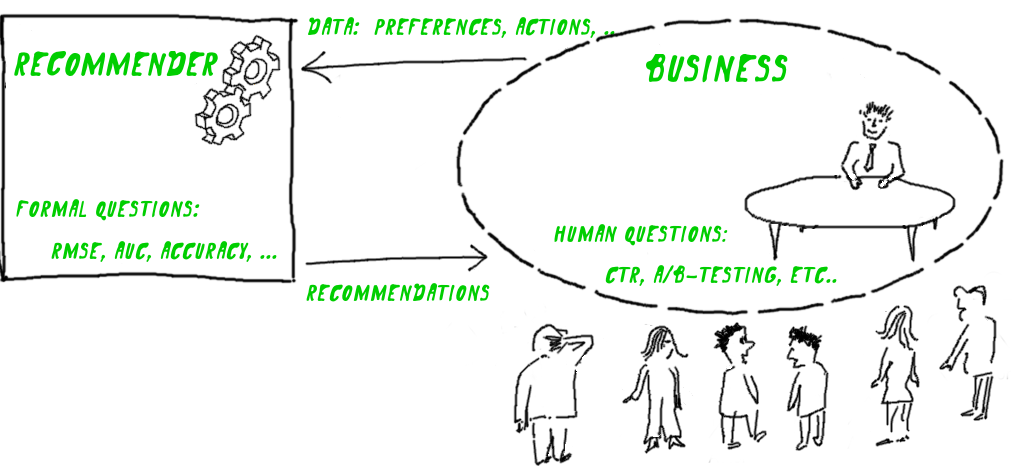
 Wi!Mi – это инструмент для создания моделей знаний с неограниченным количеством связей, параметров и отношений, обладающий логическим выводом. Скачать данный конструктор можно с
Wi!Mi – это инструмент для создания моделей знаний с неограниченным количеством связей, параметров и отношений, обладающий логическим выводом. Скачать данный конструктор можно с 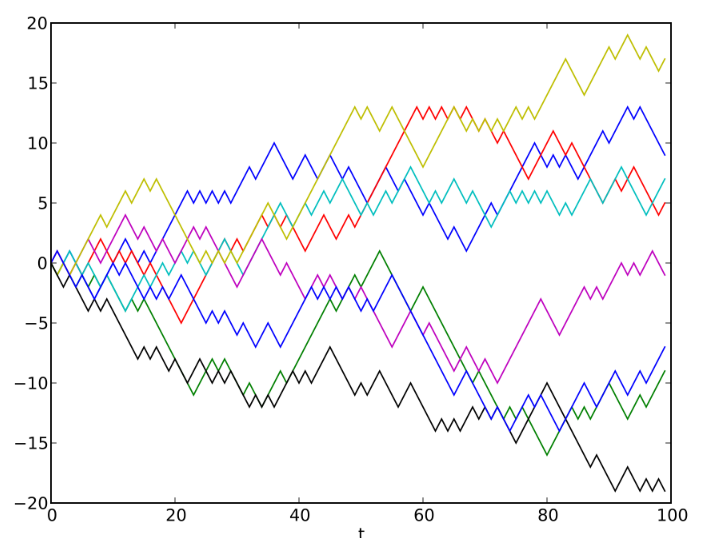

 Привет! Я воплощаю интересные идеи на python и рассказываю о том, что из этого вышло. В прошлый
Привет! Я воплощаю интересные идеи на python и рассказываю о том, что из этого вышло. В прошлый 