
Постановка задачи компьютерного зрения
13 мин

Последние лет восемь я активно занимаюсь задачами, связанными с распознаванием образов, компьютерным зрением, машинным обучением. Получилось накопить достаточно большой багаж опыта и проектов (что-то своё, что-то в ранге штатного программиста, что-то под заказ). К тому же, с тех пор, как я написал пару статей на Хабре, со мной часто связываются читатели, просят помочь с их задачей, посоветовать что-то. Так что достаточно часто натыкаюсь на совершенно непредсказуемые применения CV алгоритмов.
Но, чёрт подери, в 90% случаев я вижу одну и ту же системную ошибку. Раз за разом. За последние лет 5 я её объяснял уже десяткам людей. Да что там, периодически и сам её совершаю…
В 99% задач компьютерного зрения то представление о задаче, которое вы сформулировали у себя в голове, а тем более тот путь решения, который вы наметили, не имеет с реальностью ничего общего. Всегда будут возникать ситуации, про которые вы даже не могли подумать. Единственный способ сформулировать задачу — набрать базу примеров и работать с ней, учитывая как идеальные, так и самые плохие ситуации. Чем шире база-тем точнее поставлена задача. Без базы говорить о задаче нельзя.
Тривиальная мысль. Но все ошибаются. Абсолютно все. В статье я приведу несколько примеров таких ситуаций. Когда задача поставлена плохо, когда хорошо. И какие подводные камни вас ждут в формировании ТЗ для систем компьютерного зрения.


 Вновь приветствую читателей «Хабра»!
Вновь приветствую читателей «Хабра»!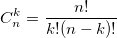
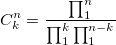
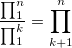 и тогда
и тогда 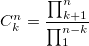
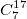 :
:


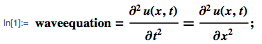

 В кратце опишу содержание
В кратце опишу содержание 
 В конце прошлого года Google Translate к выходу нового эпизода «Звёздных войн» добавил поддержку «Галактического языка» Ауребеш. Правда оказалось, что при выборе этого языка просто происходит перевод на английский. Если использовать Chrome или Firefox, то появляется шрифт, в котором вместо латиницы подставлены символы ауребеш, ну а в IE без особых хитростей выводится английский текст.
В конце прошлого года Google Translate к выходу нового эпизода «Звёздных войн» добавил поддержку «Галактического языка» Ауребеш. Правда оказалось, что при выборе этого языка просто происходит перевод на английский. Если использовать Chrome или Firefox, то появляется шрифт, в котором вместо латиницы подставлены символы ауребеш, ну а в IE без особых хитростей выводится английский текст.