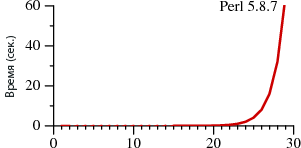
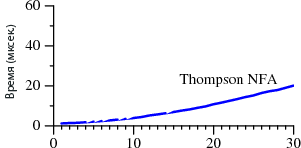
GOTO or not GOTO вот в чём вопрос
8 мин
«Спор возможен там, где истина закрыта. В бесплодных спорах можно бесконечно обсуждать, что в комнате находится закрытой дверью. Но стоит дверь открыть, и ясно станет всем и спорить не о чем, коль каждый истину увидеть сможет»
Владимир Мегре

Статья посвящается Зацепину П.М., выдающемуся инженеру Алтайского государственного университета, под чьим чутким руководством многие студенты, включая автора статьи, постигали магию инженерного творчества.
Введение
Спор о возможности использования в программах оператора GOTO ведётся уже очень давно (официальным его началом признана статья Дейкстры «О вреде оператора GOTO», опубликованная в 1968 году [2]). Через три года мы будем праздновать 50-летний юбилей этого спора. Это хороший повод, чтобы наконец-то «расставить все точки над i» и прекратить спор.
Цитата в эпиграфе выбрана неслучайно. Она в точности отражает текущую ситуацию в споре про GOTO. В нашем случае «комната за закрытой дверью» – это понятная всем постановка задачи. Пока, к сожалению, такой постановки задачи озвучено не было, поэтому споры и не угасают. Противоборствующие стороны спорят хоть и о схожих, но всё-таки о разных вещах, поэтому и не могут найти компромисса.
Давайте займём в этом споре нейтральную сторону, и беспристрастно во всём разберёмся. Рассмотрим доводы «противников» и «защитников» оператора GOTO и решим, «кто из них прав, а кто виноват».