Привет, Хабр!
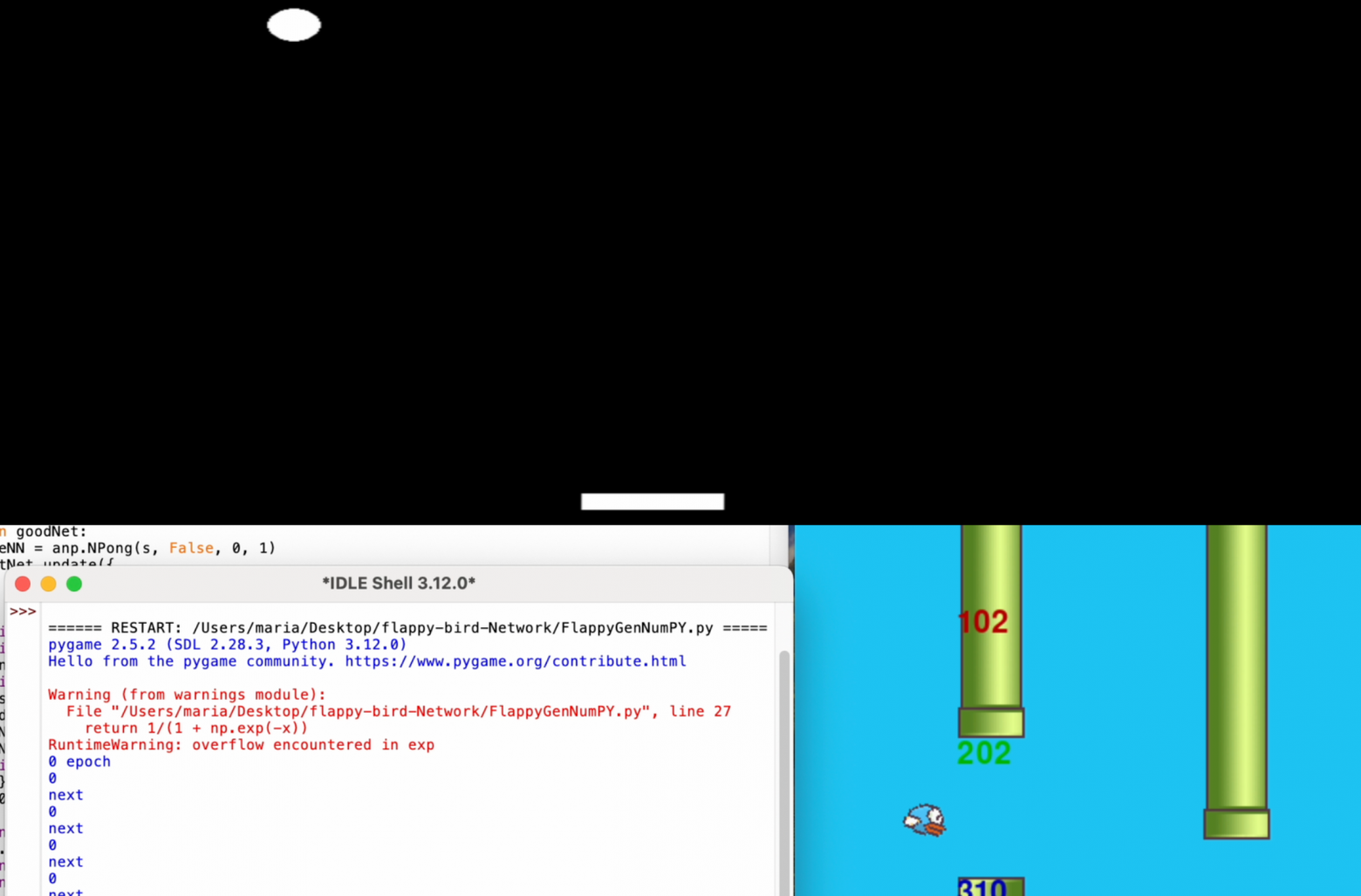
Сегодня я расскажу и покажу, как сделать Genetic Algorithm(GA) для нейросети, чтобы с помощью него она смогла проходить разные игры. Я его испробовал на игре Pong и Flappy bird. Он себя показал очень хорошо. Советую прочитать, если вы не читали первую статью: "Создание простого и работоспособного генетического алгоритма для нейросети с Python и NumPy" , так как я доработал свой код который, был показан в той статье.
Я разделил код на две скрипта, в одной нейросеть играет в какую-то игру, в другой обучается и принимает решения(сам генетический алгоритм). Код с игрой представляет из себя функцию которая возвращает фитнес функцию (она нужна для сортировки нейросетей, например, сколько времени она продержалась, сколько очков заработала и т.п.). Поэтому код с играми(их две) будет в конце статьи. Генетический алгоритм для нейросети для игры Pong и игры Flappy Bird различаются лишь параметрами.
Используя скрипт, который я написал и описал в предыдущей статье, я создал сильно изменённый код генетического алгоритма для игры Pong, который я и буду описывать больше всего, так как именно на него я опирался, когда я уже создавал GA для Flappy Bird.
Вначале нам потребуется импортировать модули, списки и переменные: