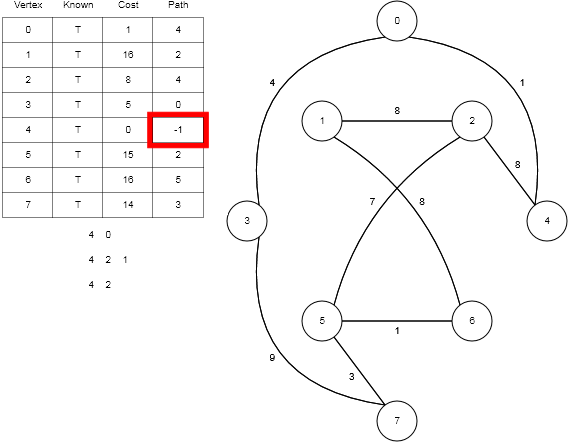
Эксперимент с голографическим кодированием/декодированием цветных изображений
4 мин
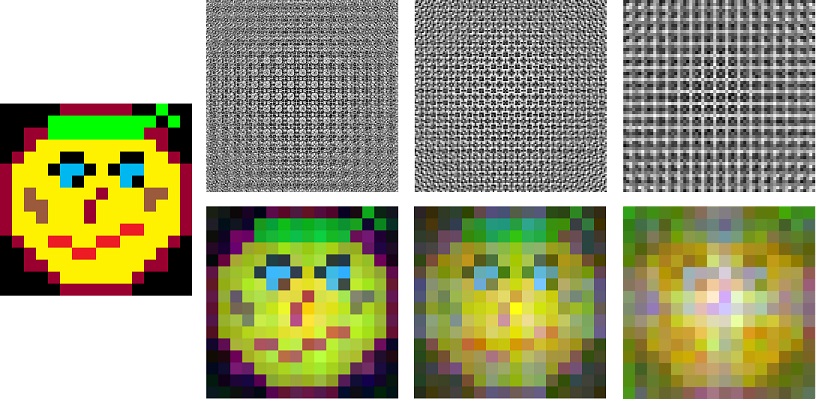
Однажды я был поражён одним из удивительных свойств голограммы, которое заключается в том, что разбив голографический снимок объекта на осколки, по каждому из осколков можно восстановить изображение всего объекта, правда с несколько ухудшенным качеством. Прочитав топик «Эксперимент с голографическим кодированием и декодированием информации» товарища eresik я непременно сам захотел реализовать подобную цифровую голограмму. Взяв за основу его алгоритм, я запустил Delphi и принялся за дело. Наконец, немного повозившись с коэффициентами, я стал получать адекватные чёрно-белые картины похожие на те, которые получал eresik. При затирании части голограммы, как ни удивительно, исходное изображение восстанавливалось! Так каким же образом это может происходить? Я попытаюсь рассказать, как можно наглядно объяснить это свойство голограммы, не вдаваясь в физику и математику.
 Доброго времени суток, хабр! Сегодня я бы хотел рассказать про жадные алгоритмы.
Доброго времени суток, хабр! Сегодня я бы хотел рассказать про жадные алгоритмы. В статье расскажу как можно очень быстро перечислить связные объекты на бинарном растре, значительно быстрее, чем я рассказывал в
В статье расскажу как можно очень быстро перечислить связные объекты на бинарном растре, значительно быстрее, чем я рассказывал в 
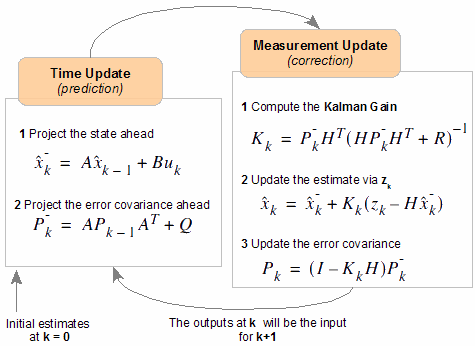 Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.
Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.