Бывают случаи, когда нужно ограничить пользователям доступ к некоторым данным в кубе. Казалось бы, тут нет ничего сложного: устанавливай построчные фильтры в ролях и готово, но есть одна проблема — фильтр урезает данные в таблице и получается, что можно посмотреть обороты только по доступным строкам, а нам нужны все обороты, но детализация должна быть доступна только для части из них.
Например, пользователь должен видеть обороты по всем товарам, с возможностью полной детализации по ним, но клиенты при этом должны отображаться не все, а лишь некоторые, либо все клиенты, но с частично скрытыми данными в некоторых атрибутах (полях).
Чтобы не дать пользователю возможность просматривать обороты в разрезе клиентов, можно обыграть это через формулы в мерах и выводить пустое значение, если пользователь попытается посмотреть оборот конкретного клиента, один из подобных вариантов описан
здесь. Однако это всё не то. Когда мер несколько десятков, то писать в каждой из них формулу… а если забудешь? Но ведь точно забудешь же когда-нибудь… А если пользователю нужны данные из конкретной карточки клиента, то ему ни что не помешает это увидеть без выбора фильтрующей меры. Что же делать?
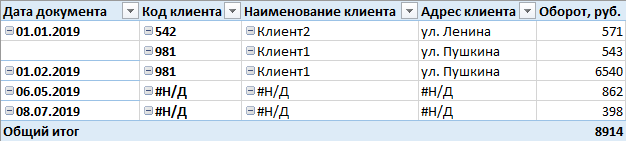
Нам нужно было добиться вот такого отображения: