Многие сомневаются, что облака обходятся дешевле собственного железа — такую точку зрения мы в ActiveCloud встречаем довольно часто. Одни пользуются облаками из-за гибкости, вторые хотят уйти от рутины, третьим нужна централизация, четвёртым — безопасность. Однако облака не только удобны, но и выгодны, и мы попробуем объяснить почему.
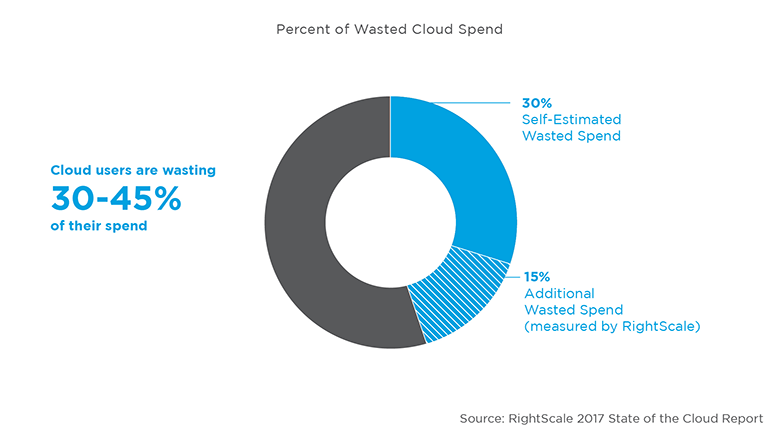
При оценке эффективности перехода в облака Заказчики зачастую склонны сравнивать стоимость владения облаками и железом в лоб. Например, если покупаем 5 серверов с 40 процессорными ядрами и 256 ГБ RAM, то и у облачного провайдера запрашиваем аналогичные ресурсы (40*5=200 vCPU + 256*5=1280 ГБ vRAM), а потом сравниваем затраты за 3 года или даже 5 лет.
К сожалению, в большинстве случаев такой подход не будет объективным, поскольку не учитывает ряд важных нюансов, напрямую влияющих на стоимость владения.
1. Не учитываются ресурсы, требуемые для обеспечения отказоустойчивости
В облаке вопросы отказоустойчивости
уже продуманы — хосты виртуализации кластеризованы, а в кластере зарезервированы ресурсы как минимум в размере одного хоста виртуализации, чтобы серверы клиентов в случае отказа хоста или его выключения на время регламентных работ могли быть перемещены на резервный хост. При этом дополнительной платы (сверх обозначенной стоимости ресурсов) за такой резерв сервис-провайдер не требует.
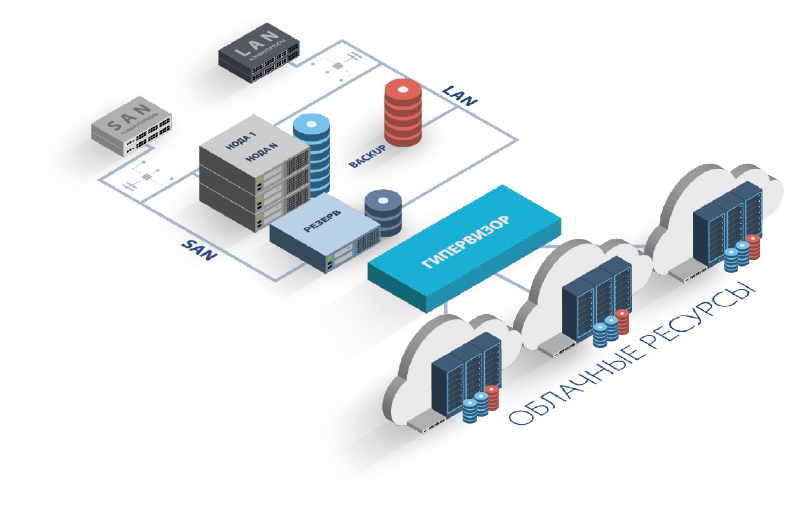
В случае своего железа потери на резервирование придётся вычесть из потенциально доступного на оборудовании пула ресурсов. В нашем примере с 5 серверами Заказчик при сохранении отказоустойчивости не сможет загрузить серверы по процессору и памяти более чем на 80%, иначе в случае отказа одного из хостов часть серверов физически не смогут быть перезапущены из-за нехватки ресурсов.
Конечно, можно рассчитывать, что в случае аварии вы сможете временно остановить ряд некритичных сервисов, но такой подход в реальных условиях как правило не работает.