Оптимизация размещения виртуальных машин по серверам
5 мин
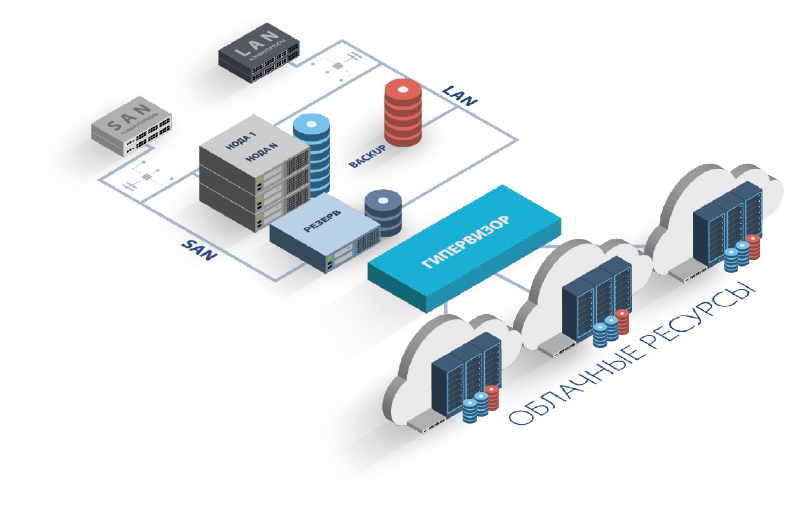
Какое-то время назад один мой коллега рассказал, что место в ДЦ кончается, сервера ставить больше некуда, а нагрузка растет и непонятно, что делать, и наверно придется все имеющиеся сервера поменять на более мощные.
Я в это время занимался задачей составления оптимальных расписаний, и подумал — а что, если применить оптимизационные алгоритмы для повышения утилизации серверов в ДЦ? Отсюда и родился проект, про который я хочу написать.
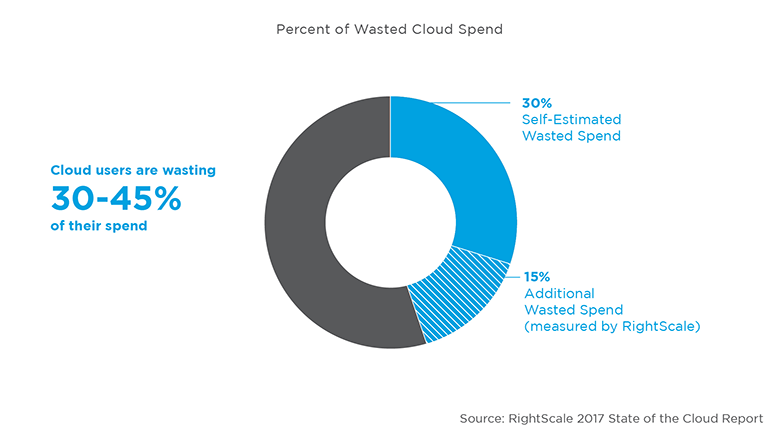
Для продвинутых сразу скажу, что в этой статье речь пойдет про bin packing, а остальным, кто хочет узнать, как с помощью относительно несложных расчетов сэкономить до 30% серверных ресурсов, добро пожаловать под кат.
Я в это время занимался задачей составления оптимальных расписаний, и подумал — а что, если применить оптимизационные алгоритмы для повышения утилизации серверов в ДЦ? Отсюда и родился проект, про который я хочу написать.
Для продвинутых сразу скажу, что в этой статье речь пойдет про bin packing, а остальным, кто хочет узнать, как с помощью относительно несложных расчетов сэкономить до 30% серверных ресурсов, добро пожаловать под кат.