Слова «облако», «облачные вычисления», «облачный» используются для чего попало. Новое модное слово, buzzword. Мы видим «облачные антивирусы», «облачные блейд-сервера». Даже именитые вендоры сетевого оборудования, не стесняются выставлять коммутаторы с ярлыком «for cloud computing». Это вызывает инстинктивную неприязнь, примерно, как «органические» продукты питания.
Любой технарь, который попытается разобраться с технологиями, лежащими в основе «облака», после нескольких часов борьбы с потоком рекламных восторгов, обнаружит, что это облака — это те же VDSы, вид сбоку. Он будет прав. Облака, в том виде, как их делают сейчас — обычные виртуальные машины.
Однако, облака, это не только маркетинг и переименованные VDS. У слова «облако» (или, точнее у фразы «облачные вычисления») есть есть своя техническая правда. Она не такая патетичная и восхитительно-инновационная, как рассказывают маркетологи, но она всё-таки есть. Придумана она была много десятилетий назад, но только сейчас инфраструктура (в первую очередь, Интернет и технологии виртуализации x86) доросла до уровня, который позволяет реализовать её в массовом порядке.
Итак, сначала о причине, которая вообще породила потребность в облаках:
Вот как выглядит предоставляемая услуга для обычного VDS (на месте этого графика может быть любой ресурс: процессор, память, диск):
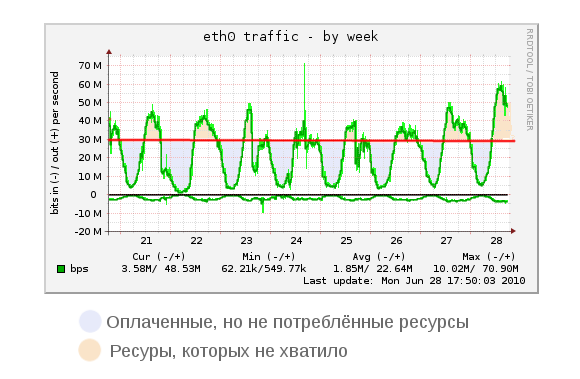
Обратите внимание: это недельный график. Существующие технологии временного увеличения лимита потребления ресурса (burst, grace period) не способны решить эту проблему на таких длинных интервалах. Т.е. машина недополучает ресурсы тогда, когда они ей больше всего нужны.
Вторая проблема — посмотрите на огромные интервалы (голубой цвет), когда ресурсы, фактически, пришлось оплатить, но использовать не удалось. Виртуальной машине ночью просто не нужно столько ресурсов. Она простаивает. И не смотря на это — владелец платит по полной.
Возникает проблема: человек вынужден заказывать ресурсов больше, чем нужно в среднем, для того, чтобы переживать без проблем пики. В остальное время ресурсы простаивают. Провайдер видит, что сервер не нагружен, начинает продавать ресурсов больше, чем есть (это называют «оверселл»). В какой-то момент, например, из-за пика нагрузки на нескольких клиентов, провайдер нарушает свои обязательства. Он обещал 70 человекам по 1Ггц — но у него есть только 40 (2.5*16 ядер). Нехорошо.
Продавать полосу честно (без оверселла) невыгодно (и цены нерыночные получаются). Оверселлить — снижать качество сервиса, нарушать условия договора.
Эта проблема не связана с VDS или виртуализацией, это общий вопрос: как честно продавать простаивающие ресурсы?
Именно ответом на эту проблему и стала идея «облачных вычислений». Слова хоть и модные, но своей основой уходящие во времена больших мейнфреймов, когда продавалось машинное время.
Облачные вычисления делают то же самое — вместо лимитов и квот, которые оплачиваются вне зависимости от реального потрбления, пользователям предоставляется возможность использовать ресурсы без ограничения, с оплатой реального потребления (и только того, что было реально использовано). Это и есть суть «облака».






 Начну с того, что вчера мне прислали приглашение на участие в тестировании Windows Azure.
Начну с того, что вчера мне прислали приглашение на участие в тестировании Windows Azure.