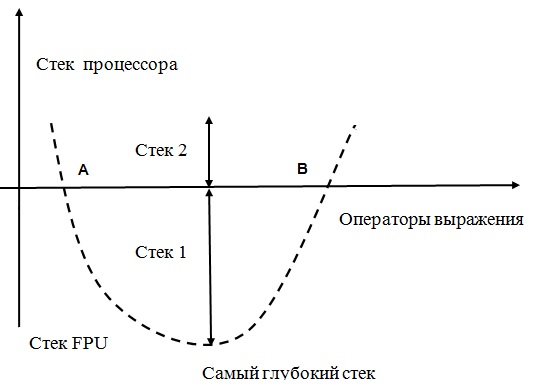
Ошибки, связанные с доступом к областям памяти, которые находятся за пределами допустимого адресного пространства (out-of-bounds memory access), в 2021 году всё ещё пребывают в списке
самых опасных уязвимостей ПО CWE Top 25. Известно, что ошибочные операции записи данных (out-of-bounds write,
CWE-787) с двенадцатого места, которое они занимали в 2019 году, перешли в 2020 году на второе. А неправильные операции чтения данных (out-of-bounds read,
CWE-125) в тех же временных пределах сменили пятое место на четвёртое.

Понимание важности раннего выявления ошибок, приводящих к вышеозначенным проблемам, привело к тому, что в свежих релизах компиляторов GNU Compiler Collection (GCC) была значительно улучшена возможность детектирования подобных ошибок. Речь идёт об использовании ключей для проведения проверок и вывода предупреждений наподобие
-Warray-bounds,
-Wformat-overflow,
-Wstringop-overflow и (самая свежая возможность, появившаяся в GCC 11)
-Wstringop-overread. Но всем этим проверкам свойственно одно и то же ограничение, связанное с тем, что система может обнаруживать проблемные ситуации лишь в пределах отдельных функций. Получается, что, за исключением анализа небольшого набора встроенных в компилятор функций, вроде
memcpy(), проверка прекращается на границе вызова функции. То есть, например, если буфер, объявленный в функции A, переполняется в функции B, вызванной из функции A, компилятор, если функция B не встроена в функцию A, на эту проблему не реагирует.
В этом материале речь пойдёт о трёх видах простых подсказок, применяемых на уровне исходного кода, которые программист может использовать для того чтобы помочь GCC выявлять операции, связанные с доступом к областям памяти, находящимся за пределами допустимого адресного пространства. Причём, эти подсказки помогают компилятору находить проблемы и при пересечении границ вызова функций, и даже тогда, когда функции определены в разных файлах с исходным кодом.







 формул, что тоже немало), зато обойдёмся без 32 процессорных ядер и без GPU, а решение получим меньше чем за минуту против десятков минут или даже пары дней, как в статье. Для всего этого нам понадобится лишь
формул, что тоже немало), зато обойдёмся без 32 процессорных ядер и без GPU, а решение получим меньше чем за минуту против десятков минут или даже пары дней, как в статье. Для всего этого нам понадобится лишь