Недавно, на хакатоне от Petamelon нам в руки попал датасет с ~6 000 000 резюме с НН. Там, естественно, не было никаких персональных данных и контактов, но было много других интересных вещей: ожидаемая зарплата, возраст, пол, примерный адрес, образование и индустрии, в которых человек ищет работу. Было решено попробовать использовать эти данные в нашем проекте про выбор школ. Идея заключалась в том, чтобы определить в каких индустриях работают выпускники школ и сколько примерно зарабатывают. Но я, конечно, не удержался и построил кучу других бесполезных, но прикольных таблиц и графиков.
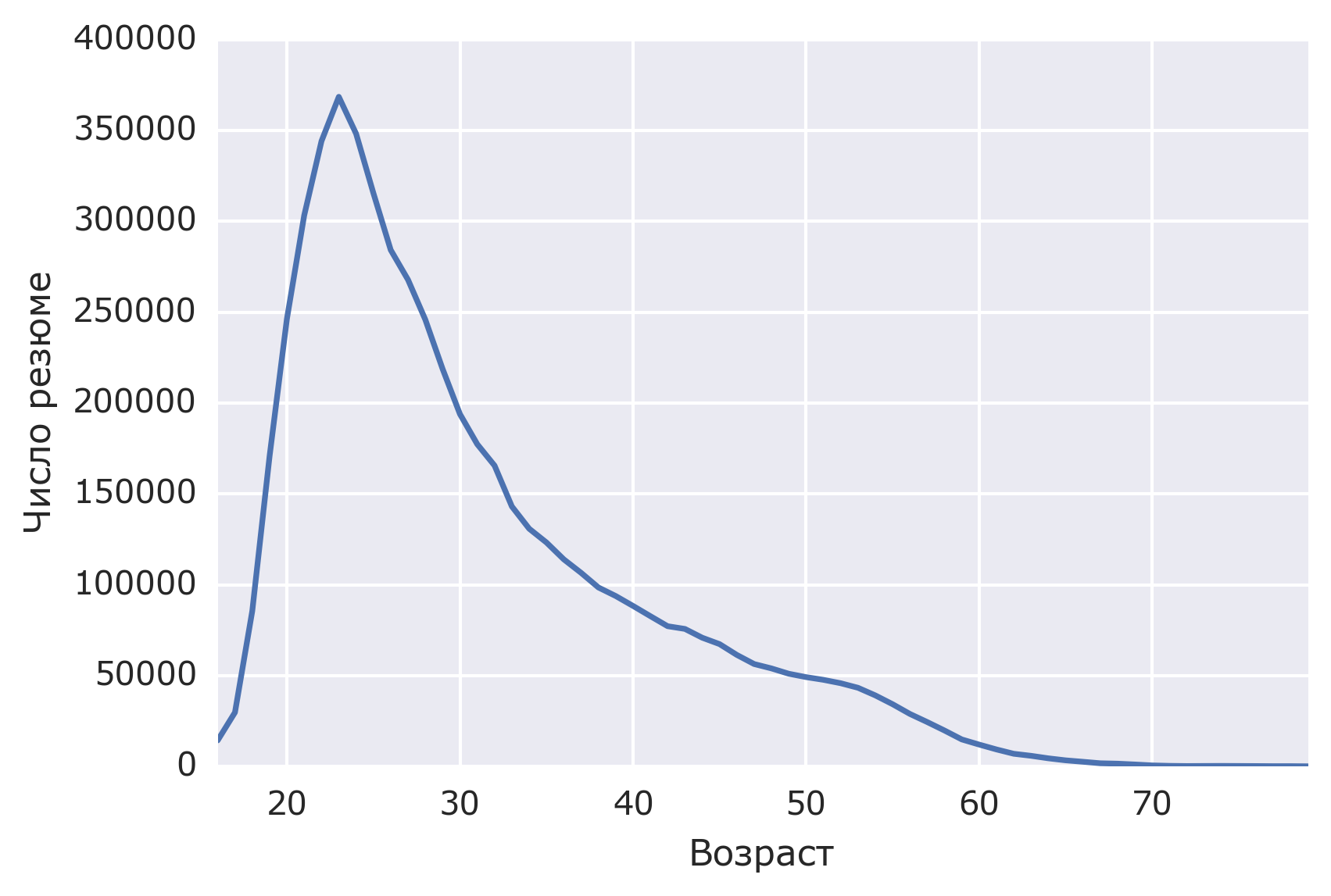
Распределение резюме по возрасту имеет интересную форму и как будто разделено на две части: до окончания института и после:
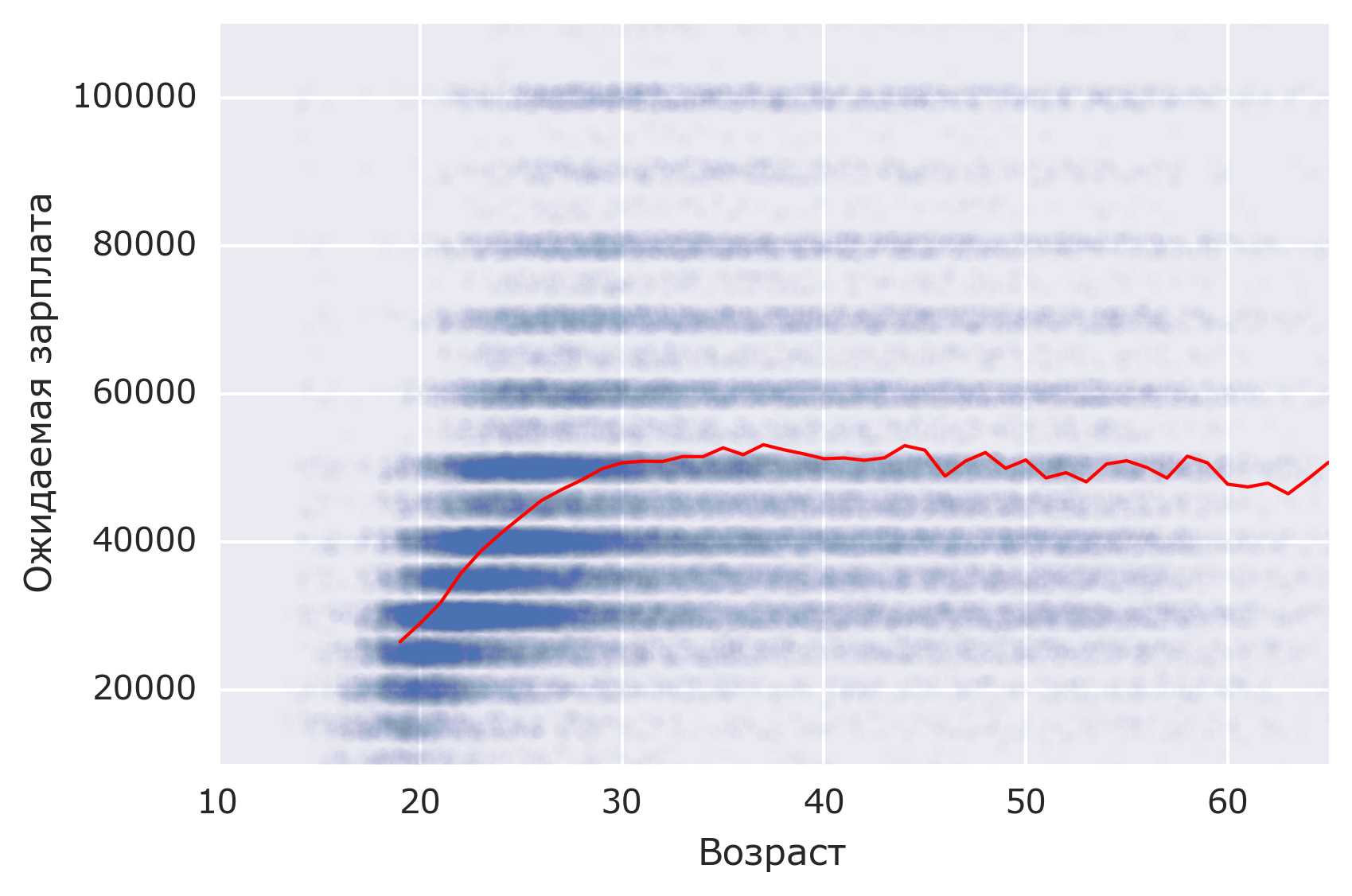
В Москве с возрастом ожидаемая зарплата выходит на плато в ~50 000 рублей:
Распределение резюме по возрасту имеет интересную форму и как будто разделено на две части: до окончания института и после:
В Москве с возрастом ожидаемая зарплата выходит на плато в ~50 000 рублей:


 На данный момент существует много компаний нуждающихся в системах аналитики, но дороговизна и чрезмерная сложность данного ПО в большинстве случаев вынуждает отказаться от идеи построения собственной аналитической системы в пользу простого всем известного экселя. Также дополнительные расходы на обучение сотрудников, поддерживание дорогих систем хранения данных и т.д. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner.
На данный момент существует много компаний нуждающихся в системах аналитики, но дороговизна и чрезмерная сложность данного ПО в большинстве случаев вынуждает отказаться от идеи построения собственной аналитической системы в пользу простого всем известного экселя. Также дополнительные расходы на обучение сотрудников, поддерживание дорогих систем хранения данных и т.д. И тут на помощь могут прийти Open Source решения — их не так много, но есть очень достойное ПО, одним из которых которых является RapidMiner.