Перевод поста Стивена Вольфрама (Stephen Wolfram) "Data Science of the Facebook World".
Выражаю огромную благодарность Кириллу Гузенко за помощь в переводе.
alizar написал краткую заметку об этой статье и описанном в ней функционале Wolfram|Alpha и Wolfram Language. В нашем блоге мы приводим её полный перевод.
Миллионы человек в настоящее время пользуются нашим приложением "
Wolfram|Alpha персональная аналитика для Facebook". И, как часть нашего
последнего обновления, в дополнение к сбору некоторых анонимных статистических данных, мы запустили программу «донорства данных», позволяющую людям поделиться с нами подробными данными, которые мы используем для научно-исследовательских целей.
Несколько недель назад мы решили
проанализировать все эти данные. И, должен сказать, что, это было ни чем иным, как потрясающим примером силы
Mathematica и
Wolfram language в науке о данных (это также хороший материал для курса по науке о данных, который я начал готовить).
Мы всегда планировали использовать собираемые нами данные для улучшения нашей системы
персональной аналитики. Но я не мог сопротивляться своим попыткам заодно и рассмотреть всё это с научной точки зрения.
Мне всегда были интересны люди и их жизненные пути. Но у меня никогда не получалось объединить это с моими научными интересами. До этого момента. Последние несколько недель прошли весьма захватывающе в наблюдении тех результатов, которые мы получили. Одни были ожидаемыми, а другие были настолько непредсказуемыми, что я никогда бы и не предположил ничего подобного. И всё это напоминало о феноменах из моего труда
A New Kind of Science (Новый вид науки).
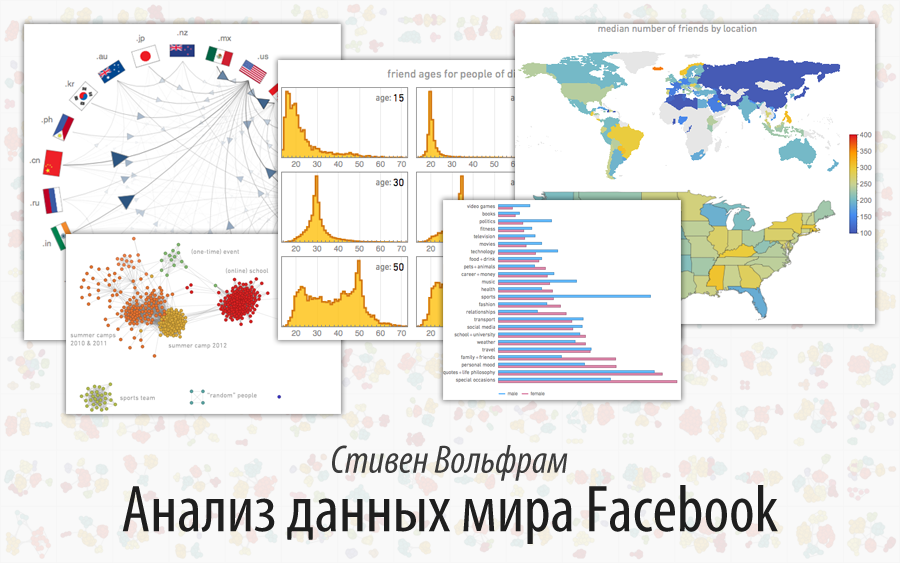
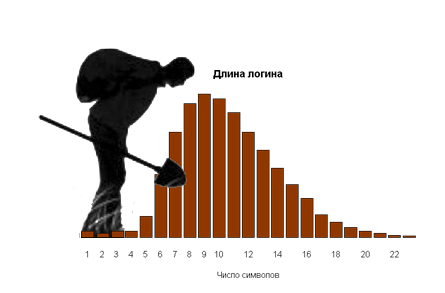
Так как же выглядят данные? Ниже приведены социальные сети несколько доноров данных — группы друзей разбиты по цвету (любой может найти свою собственную сеть, используя
Wolfram|Alpha или функцию
SocialMediaData в
Mathematica (
в последней версии Wolfram Language эта функция поддерживает работу с Facebook, GooglePlus, Instagram, LinkedIn, Twitter — прим. ред.)).