Узнайте, как использовать пейджер pspg с базами данных MariaDB для визуализации и эффективного взаимодействия с данными при выполнении задач DevOps.
Я не являюсь противником GUI. На самом деле, я написал три книги о разработке графического веб-интерфейса с помощью Java. Однако мне также нравится интерфейс командной строки (CLI), особенно текстовые пользовательские интерфейсы.
После года изучения MariaDB и мира DevOps я открыл для себя и поэкспериментировал со многими текстовыми инструментами CLI, о существовании которых я даже не подозревал. Эти инструменты особенно полезны при подключении к удаленным серверам без графического интерфейса.
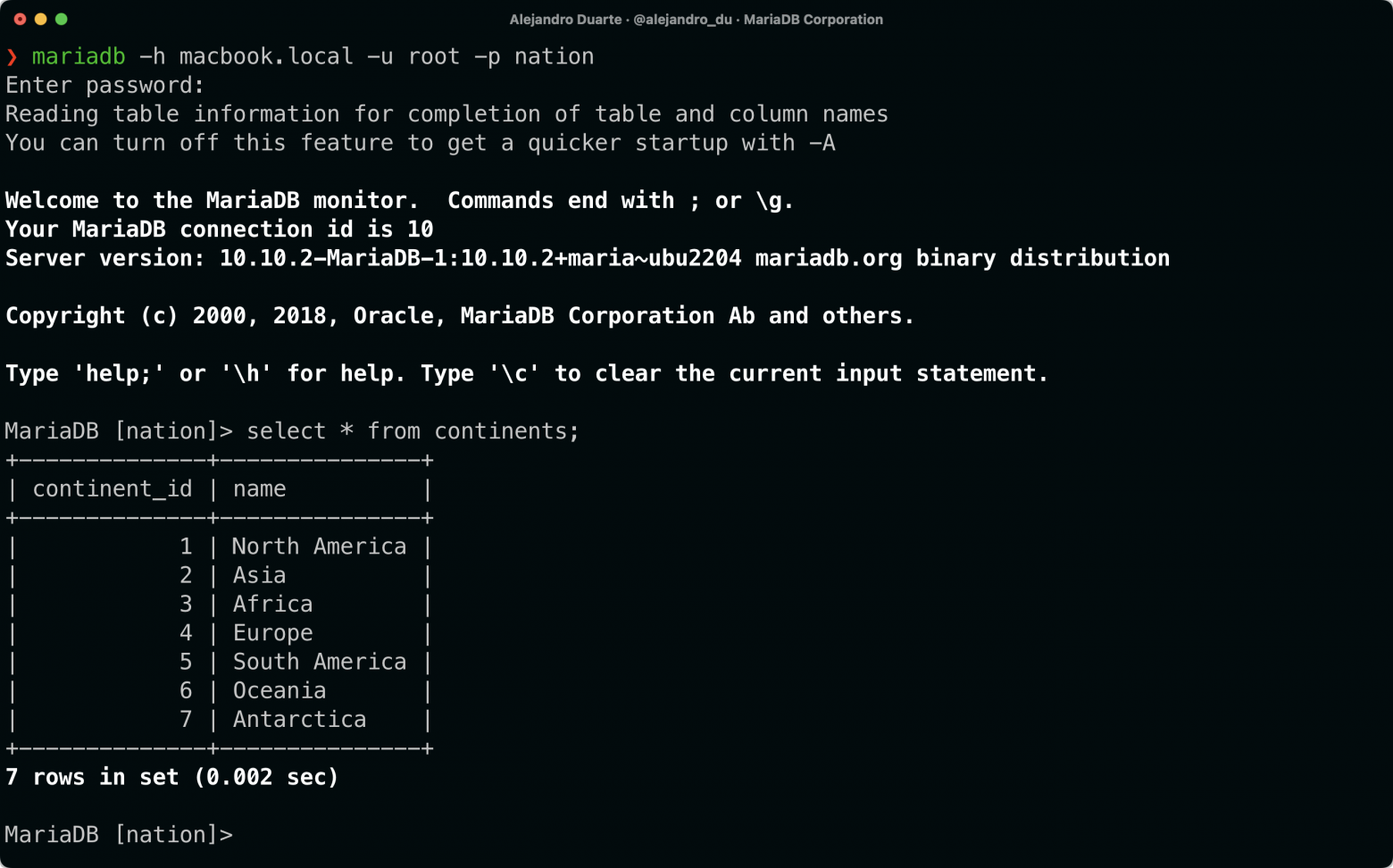
Одним из специальных инструментов CLI, который я часто использую, является SQL-клиентmariadb (или mysq в мире MySQL) — программа CLI, используемая для подключения к базам данных, совместимым с MariaDB. С ее помощью вы можете отправлять SQL-запросы и другие команды на сервер базы данных.