После того как Иван познакомился с когортным анализом, он терпеть не мог любые виды слащавых метрик.
Но ирония была в том, что руководство не знало ничего другого, и знать категорически не хотело. Приходилось переступать через себя и тупо идти на встречу «просьбам» начальника, чтобы не заработать репутацию нехорошего человека, неподчиняющегося указаниям мудрецов.
Иногда из этого даже получались весьма интересные результаты. Об одном таком случае сейчас и пойдет речь.
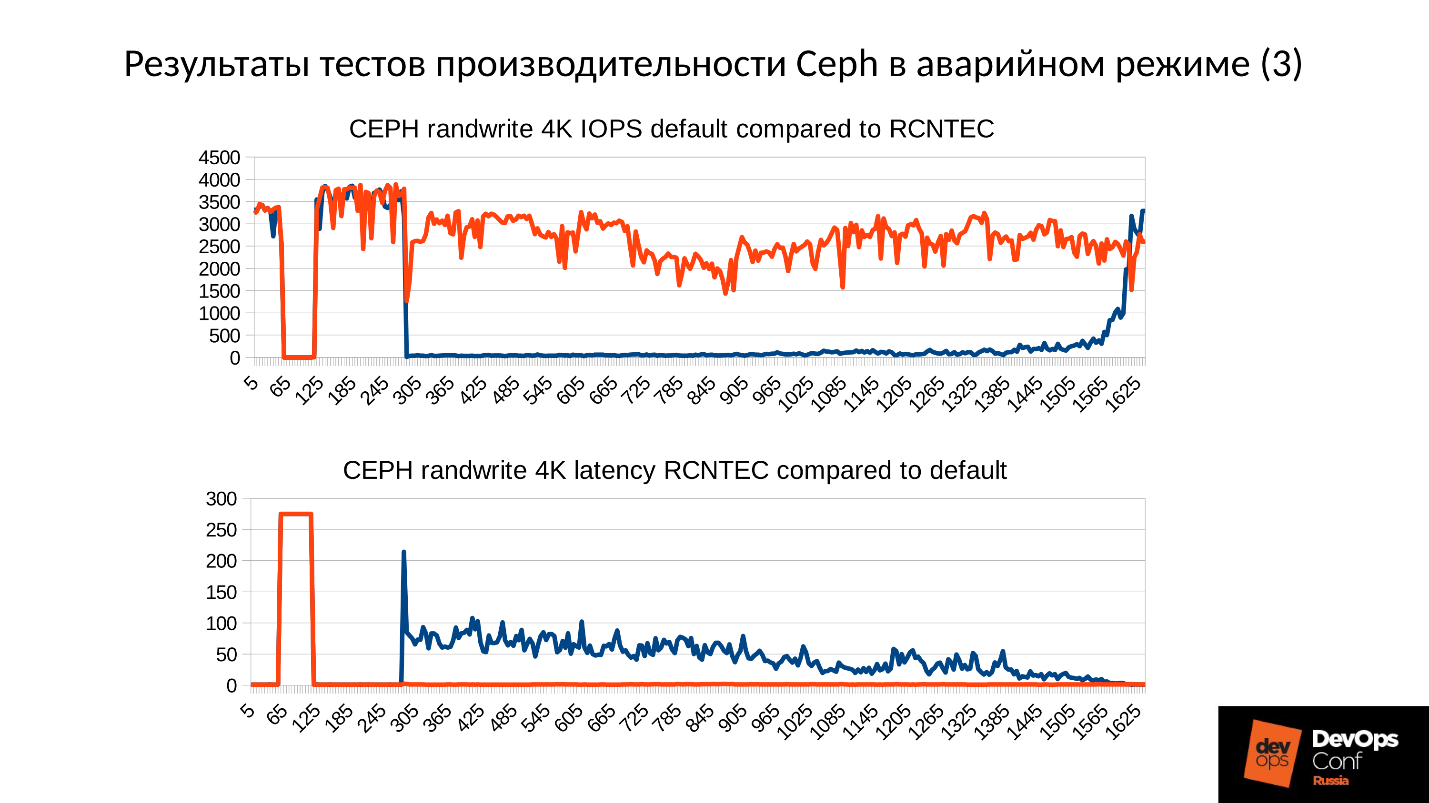
Как-то руководитель попросил Ивана разобраться, почему в течение 3- недель непрерывно падает конверсия прохождения стенда командами:
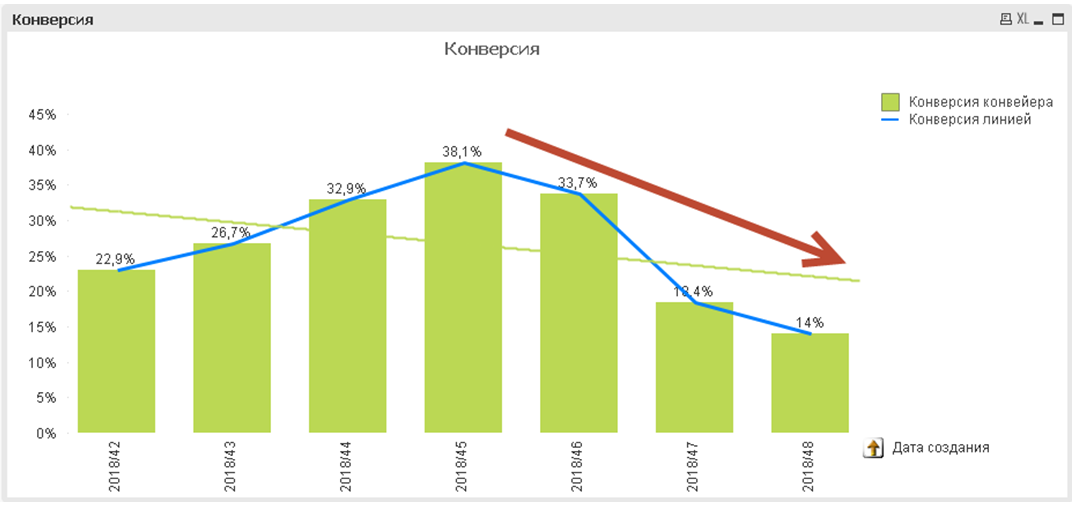
Но ирония была в том, что руководство не знало ничего другого, и знать категорически не хотело. Приходилось переступать через себя и тупо идти на встречу «просьбам» начальника, чтобы не заработать репутацию нехорошего человека, неподчиняющегося указаниям мудрецов.
Иногда из этого даже получались весьма интересные результаты. Об одном таком случае сейчас и пойдет речь.
Как-то руководитель попросил Ивана разобраться, почему в течение 3- недель непрерывно падает конверсия прохождения стенда командами: