Часть I
Часть II
Часть III
Часть IV
Это полная версия предыдущей статьи, к которой добавлены тестбенчи.
Спроектируем Little Man Computer на языке Verilog.
Статья про LMC была на Хабре.
Online симулятор этого компьютера здесь.
Напишем модуль оперативной памяти (ОЗУ), состоящий из четырех (ADDR_WIDTH=2) четырёхбитных (DATA_WIDTH=4) слов. Данные загружаются в ОЗУ из data_in по адресу adr при поступлении тактового сигнала clk.
module R0 #(parameter ADDR_WIDTH = 2, DATA_WIDTH = 4)
(
input clk, //тактовый сигнал
input [ADDR_WIDTH-1:0] adr, //адрес
input [DATA_WIDTH-1:0] data_in, //порт ввода данных
output [DATA_WIDTH-1:0] RAM_out //порт вывода данных
);
reg [DATA_WIDTH-1:0] mem [2**ADDR_WIDTH-1:0]; //объявляем массив mem
always @(posedge clk) //при поступлении тактового сигнала clk
mem [adr] <= data_in; //загружаем данные в ОЗУ из data_in
assign RAM_out = mem[adr]; //назначаем RAM_out портом вывода данных
endmodule
```<cut/>
В тестбенче загрузим 0001 по адресу 00, 0010 по адресу 01, 0100 по адресу 10, 1000 по адресу 11:
<!--<spoiler title="Создание тестбенча">-->
Создать новый проект, создать файлы R0.v и tR0.v (эти файлы автоматически добавятся к проекту).
Скомпилировать оба файла.
Запустить моделирование скомпилированного файла tR0.v
<!--</spoiler>-->```verilog
module tR0;
reg clk;
reg [1:0] adr;
reg [3:0] data_in;
wire [3:0] RAM_out;
R0 test_R0 (clk, adr, data_in,RAM_out);
initial
begin
clk = 0;
adr[0] = 0;
adr[1] = 0;
data_in[0] = 0;
data_in[1] = 0;
data_in[2] = 0;
data_in[3] = 0;
#5 data_in[0] = 1;
#5 clk = 1;
#5 adr[0] = 1; data_in[0] = 0; data_in[1] = 1; clk = 0;
#5 clk = 1;
#5 adr[0] = 0; adr[1] = 1; data_in[1] = 0; data_in[2] = 1; clk = 0;
#5 clk = 1;
#5 adr[0] = 1; adr[1] = 1; data_in[2] = 0; data_in[3] = 1; clk = 0;
#5 clk = 1;
#5 adr[0] = 0; adr[1] = 0; data_in[3] = 0; clk = 0;
#5 adr[0] = 1; adr[1] = 0;
#5 adr[0] = 0; adr[1] = 1;
#5 adr[0] = 1; adr[1] = 1;
#5 adr[0] = 0; adr[1] = 0;
#5 adr[0] = 1; adr[1] = 0;
#5 adr[0] = 0; adr[1] = 1;
#5 adr[0] = 1; adr[1] = 1;
#5 adr[0] = 0; adr[1] = 0;
#5 adr[0] = 1; adr[1] = 0;
#5 adr[0] = 0; adr[1] = 1;
#5 adr[0] = 1; adr[1] = 1;
end
endmodule

Подключим счётчик к адресному входу ОЗУ. На вход счётчика необходимо подключить тактовый генератор.
Вот пример программы, использующей внутренний генератор ALTUFM_OSC. Частота штатного генератора 5.5 МГц (MAX II EPM240 CPLD Minimal Development Board).
module inner_Clock ( output reg LED);
ALTUFM_OSC osc( .oscena(1'b1), .osc(clk));
reg signal;
reg [24:0] osc_counter;
reg [24:0] const_data = 25'b10110111000110110000000;
initial
begin
signal = 1'b0;
osc_counter = 25'b0;
end
//досчитываем до 6 000 000 и обнуляем счетчик osc_counter
always @(posedge clk)
begin
osc_counter <= osc_counter+ 1'b1;
if(osc_counter == const_data)
begin
signal <= ~signal;
osc_counter <= 25'b0;
end
LED = signal; // LED мигает ~1 раз в сеунду.
end
endmodule
Вообще, в данной схеме можно использовать внешний генератор меандра, например КМОП таймер 555 (работающий от 3.3V) или микросхему К155ЛА3 (К155ЛА3 представляет 4 логических элемента 2И-НЕ).
Подключим таймер 555 к счётчику, подключим счётчик к адресному входу ОЗУ.
Теперь при поступлении тактового сигнала на счётчик будет происходить переход на следующую ячейку в памяти. На тактовый вход ОЗУ подключим кнопку RAM_button — данные в ОЗУ будут загружаться при нажатии на эту кнопку.
module R1 (timer555, RAM_button, data_in, RAM_out, counter);
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 4;
input timer555;
input RAM_button;
//input [ADDR_WIDTH-1:0] adr;
input [DATA_WIDTH-1:0] data_in;
output [DATA_WIDTH-1:0] RAM_out;
output reg [1:0] counter;
// Counter
always @(posedge timer555)
counter <= counter + 1;
// RAM
wire [ADDR_WIDTH-1:0] adr;
assign adr = counter;
reg [DATA_WIDTH-1:0] mem [2**ADDR_WIDTH-1:0];
always @(posedge RAM_button)
mem [adr] <= data_in;
assign RAM_out = mem[adr];
endmodule
Вот так выглядит схема в RTL Viewer

В симуляторе ModelSim эта схема работать не будет, так как симулятору не известно начальное значение регистров counter[1:0].
Работоспособность схемы можно проверить, непосредственно загрузив программу в ПЛИС.
Далее, добавим в счетчик функцию загрузки. Загрузка из data_in [1:0] производится нажатием на кнопку Counter_load
module R2 (counter, timer555, Counter_load, RAM_button, data_in, RAM_out);
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 4;
output [1:0] counter;
input timer555, Counter_load;
// input [N-1:0] adr;
input RAM_button;
input [DATA_WIDTH-1:0] data_in;
output [DATA_WIDTH-1:0] RAM_out;
// Counter
reg [1:0] counter;
always @ (posedge timer555 or posedge Counter_load)
if (Counter_load)
counter <= data_in[1:0];
else
counter <= counter + 2'b01;
// RAM
wire [ADDR_WIDTH-1:0] adr;
assign adr = counter;
reg [DATA_WIDTH-1:0] mem [2**ADDR_WIDTH-1:0];
always @(posedge RAM_button)
mem [adr] <= data_in;
assign RAM_out = mem[adr];
endmodule
Вот так выглядит подключение кнопок и светодиодов в Pin Planner'е:

Загрузим 0001 по адресу 00, 0010 по адресу 01, 0100 по адресу 10, 1000 по адресу 11
module tR2;
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 4;
reg timer555, Counter_load, RAM_button;
wire [1:0] counter;
reg [DATA_WIDTH-1:0] data_in;
wire [DATA_WIDTH-1:0] RAM_out;
R2 test_R2(counter, timer555, Counter_load, RAM_button, data_in, RAM_out);
initial // Clock generator
begin
timer555 = 0;
forever #20 timer555 = ~timer555;
end
initial
begin
data_in[0] = 0;
data_in[1] = 0;
data_in[2] = 0;
data_in[3] = 0;
Counter_load = 0;
RAM_button = 0;
#5 data_in[0]=0; data_in[1]=0; Counter_load=1; RAM_button=0;
#5 data_in[0]=1; data_in[1]=0; Counter_load=0; RAM_button=1;
#5 data_in[0]=0; data_in[1]=0; Counter_load=0; RAM_button=0;
#5 data_in[0]=1; data_in[1]=0; Counter_load=1; RAM_button=0;
#5 data_in[0]=0; data_in[1]=1; Counter_load=0; RAM_button=1;
#5 data_in[0]=0; data_in[1]=0; Counter_load=0; RAM_button=0;
#5 data_in[0]=0; data_in[1]=1; Counter_load=1; RAM_button=0;
#5 data_in[2]=1; data_in[0]=0; data_in[1]=0; Counter_load=0; RAM_button=1;
#5 data_in[2]=0; data_in[0]=0; data_in[1]=0; Counter_load=0; RAM_button=0;
#5 data_in[0]=1; data_in[1]=1; Counter_load=1; RAM_button=0;
#5 data_in[3]=1; data_in[0]=0; data_in[1]=0; Counter_load=0; RAM_button=1;
#5 data_in[3]=0; data_in[0]=0; data_in[1]=0; Counter_load=0; RAM_button=0;
end
endmodule

В отдельном модуле создаем 4bit'ный регистр (аккумулятор).
Данные загружаются в регистр при нажатии на кнопку reg_button:
module register4
(
input [3:0] reg_data,
input reg_button,
output reg [3:0] q
);
always @(posedge reg_button)
q <= reg_data;
endmodule
Добавим в общую схему аккумулятор Acc, мультиплексор MUX2 и сумматор sum.
Сумматор прибавляет к числу в аккумуляторе Acc числа из памяти.
На сигнальные входы мультиплексора подаются числа data_in и sum.
Число из MUX2 загружается в аккумулятор Acc при нажатии кнопки Acc_button.
Число из Асс загружается в ОЗУ при нажатии кнопки RAM_button.

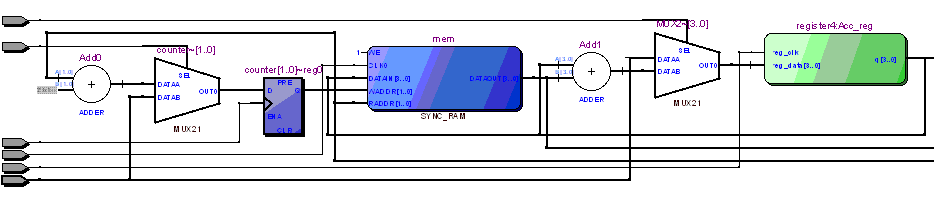
module R3 (MUX_switch, Acc_button, Acc, counter, timer555,
Counter_load, RAM_button, data_in, RAM_out);
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 4;
input MUX_switch;
input Acc_button;
output [3:0] Acc;
input timer555, Counter_load;
output [1:0] counter;
// input [N-1:0] adr;
input RAM_button;
input [DATA_WIDTH-1:0] data_in;
output [DATA_WIDTH-1:0] RAM_out;
// Counter
reg [1:0] counter;
always @ (posedge timer555 or posedge Counter_load)
if (Counter_load)
counter <= data_in[1:0];
else
counter <= counter + 2'b01;
// RAM
wire [ADDR_WIDTH-1:0] adr;
assign adr = counter;
reg [DATA_WIDTH-1:0] mem [2**ADDR_WIDTH-1:0];
always @(posedge RAM_button)
mem [adr] <= Acc;
assign RAM_out = mem[adr];
// sum
wire [3:0] sum;
assign sum = Acc + RAM_out;
// MUX2
reg [3:0] MUX2;
always @*
MUX2 = MUX_switch ? sum : data_in;
//Схема подавления дребезга контактов кнопки Acc_button
/* reg Acc_dff;
always @(posedge Acc_button or negedge timer555)
if (!timer555)
Acc_dff <= 1'b0;
else
Acc_dff <= timer555; */
//Acc
register4 Acc_reg(
.reg_data(MUX2),
//.reg_button(Acc_dff),
.reg_button(Acc_button),
.q(Acc)
);
endmodule
Для программного подавления дребезга можно применить простую схему
/* reg Acc_dff;
always @(posedge Acc_button or negedge timer555)
if (!timer555)
Acc_dff <= 1'b0;
else
Acc_dff <= timer555; */
А можно использовать одновибратор (ждущий мультивибратор), собранный на таймере 555 или микросхеме К155ЛА3
Далее, будем складывать числа, например, 2 и 3.
- Загружаем числа в ОЗУ
- Обнуляем Асс
- Переключаем MUX2
- Загружаем первое число из ОЗУ в Асс
- Прибавляем к числу в Асс второе число из ОЗУ
- Загружаем сумму в ОЗУ
module tR3;
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 4;
reg MUX_switch;
reg Acc_button;
wire [3:0] Acc;
reg timer555, Counter_load, RAM_button;
wire [1:0] counter;
reg [DATA_WIDTH-1:0] data_in;
wire [DATA_WIDTH-1:0] RAM_out;
R3 test_R3(MUX_switch, Acc_button, Acc, counter, timer555,
Counter_load, RAM_button, data_in, RAM_out);
initial
begin
timer555 = 0;
forever #20 timer555 = ~timer555;
end
initial
begin
data_in[0] = 0;
data_in[1] = 0;
data_in[2] = 0;
data_in[3] = 0;
Counter_load = 0;
Acc_button = 0;
RAM_button = 0;
MUX_switch = 0;
#5 Counter_load = 1;
#5 data_in[0]=0; data_in[1]=1; Counter_load = 0;
#5 Acc_button = 1;
#5 RAM_button = 1;
#5 data_in[0]=0; data_in[1] = 0; Acc_button = 0; RAM_button = 0;
#5 data_in[0]=1; data_in[1]=1;
#15 Acc_button = 1;
#5 RAM_button = 1;
#5 Acc_button = 0;
#5 data_in[0]=0; data_in[1] = 0; RAM_button = 0;
#10 Acc_button = 1;
#10 Acc_button = 0;
#60 MUX_switch = 1;
#10 Acc_button = 1;
#10 Acc_button = 0;
#30 Acc_button = 1;
#10 Acc_button = 0;
#30 RAM_button = 1;
#10 RAM_button = 0;
end
endmodule

Добавим в основной модуль элемент, вычитающий из числа в аккумуляторе число, записанное в памяти.
wire [3:0] subtract;
assign subract = Acc - RAM_out ;
Заменим двухвходовой мультиплексор 4х_входовым```verilog
always @*
MUX4 = MUX_switch[1]? (MUX_switch[0]? RAM_out: subtract)
: (MUX_switch[0]? sum: data_in);
Подключим к аккумулятору устройство вывода (4bit'ный регистр), также подключим к аккумулятору 2 флага:
1. Флаг "Ноль" - это лог. элемент 4ИЛИ-НЕ. Флаг поднимается, если содержимое Асс равно нулю.
2. Флаг "Ноль или Положительное число" - это лог. элемент НЕ на старшем разряде четырёхразрядного аккумулятора. Флаг поднимается, если содержимое Асс больше или равно нулю.
```verilog
//флаг "Ноль"
output Z_flag;
assign Z_flag = ~(|Acc); // многовходовой вентиль ИЛИ
//флаг "Ноль или Положительное число"
output PZ_flag;
assign PZ_flag = ~Acc[3];
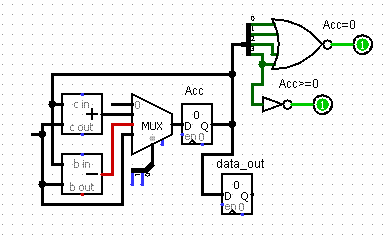
Добавим три команды
загрузка содержимого аккумулятора в устройство вывода data_out
загрузка адреса в счётчик, если поднят флаг "ноль" (JMP if Acc=0)
загрузка адреса в счётчик, если поднят флаг "ноль или положительное число" (JMP if Acc>=0)
module R4 (JMP,Z_JMP,PZ_JMP,Z_flag,PZ_flag,Output_button,data_out,MUX_switch,Acc_button,Acc,counter,timer555,RAM_button,data_in,RAM_out);
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 4;
input JMP, Z_JMP, PZ_JMP;
output Z_flag, PZ_flag;
input Output_button;
output [3:0] data_out;
input [1:0] MUX_switch;
input Acc_button;
output [3:0] Acc;
input timer555;
output [1:0] counter;
input RAM_button;
input [DATA_WIDTH-1:0] data_in;
output [DATA_WIDTH-1:0] RAM_out;
// flags
wire Z,PZ;
assign Z = Z_flag & Z_JMP;
assign PZ = PZ_flag & PZ_JMP;
// Counter
reg [1:0] counter;
always @ (posedge timer555 or posedge JMP or posedge Z or posedge PZ)
if (JMP|Z|PZ)
counter <= data_in[1:0];
else
counter <= counter + 2'b01;
// RAM
wire [ADDR_WIDTH-1:0] adr;
assign adr = counter;
reg [DATA_WIDTH-1:0] mem [2**ADDR_WIDTH-1:0];
always @(posedge RAM_button)
mem [adr] <= Acc;
assign RAM_out = mem[adr];
// sum
wire [3:0] sum;
assign sum = Acc + RAM_out;
//subtract
wire [3:0] subtract;
assign subtract = Acc - RAM_out;
// MUX4
reg [3:0] MUX4;
always @*
MUX4 = MUX_switch[1] ? (MUX_switch[0] ? RAM_out : subtract)
: (MUX_switch[0] ? sum : data_in);
//Acc
register4 Acc_reg(
.reg_data(MUX4),
.reg_button(Acc_button),
.q(Acc)
);
//data_out
register4 Output_reg(
.reg_data(Acc),
.reg_button(Output_button),
.q(data_out)
);
assign Z_flag = ~(|Acc);
assign PZ_flag = ~Acc[3];
endmodule
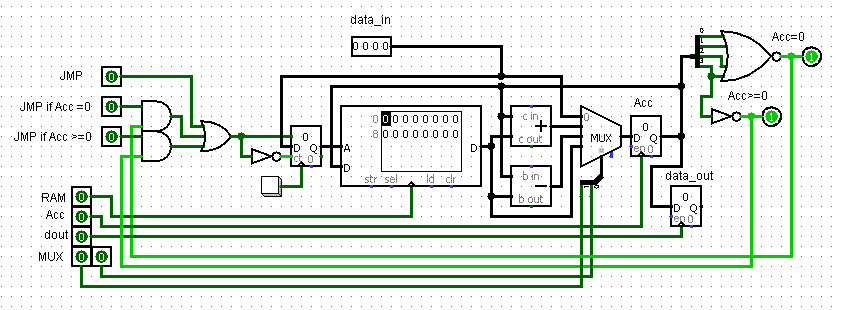
Загружаем числа в ОЗУ
Обнуляем Асс
Переключаем MUX2
Вычитаем первое число (записанное в ОЗУ) из Асс
Вычитаем второе число (записанное в ОЗУ) из Асс
Загружаем сумму в ОЗУ и в data_out
module tR4;
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 4;
reg JMP, Z_JMP, PZ_JMP;
wire Z_flag, PZ_flag;
reg Output_button;
wire [3:0] data_out;
reg [1:0] MUX_switch;
reg Acc_button;
wire [3:0] Acc;
reg timer555, RAM_button;
wire [1:0] counter;
reg [DATA_WIDTH-1:0] data_in;
wire [DATA_WIDTH-1:0] RAM_out;
R4 test_R4
(JMP,Z_JMP,PZ_JMP,Z_flag,PZ_flag,Output_button,data_out,MUX_switch,Acc_button,Acc,
counter,timer555,RAM_button,data_in,RAM_out);
initial
begin
timer555 = 0;
forever #20 timer555 = ~timer555;
end
initial
begin
data_in[0] = 0;
data_in[1] = 0;
data_in[2] = 0;
data_in[3] = 0;
JMP = 0; Z_JMP = 0; PZ_JMP = 0;
Acc_button = 0;
RAM_button = 0;
Output_button = 0;
MUX_switch[0] = 0;
MUX_switch[1] = 0;
#5 JMP = 1;
#5 data_in[0]=0; data_in[1]=1; JMP = 0;
#5 Acc_button = 1;
#5 RAM_button = 1;
#5 data_in[0]=0; data_in[1] = 0; Acc_button = 0; RAM_button = 0;
#5 data_in[0]=1; data_in[1]=1;
#15 Acc_button = 1;
#5 RAM_button = 1;
#5 Acc_button = 0;
#5 data_in[0]=0; data_in[1] = 0; RAM_button = 0;
#10 Acc_button = 1;
#10 Acc_button = 0;
#60 MUX_switch[1] = 1;
#10 Acc_button = 1;
#10 Acc_button = 0;
#30 Acc_button = 1;
#10 Acc_button = 0;
#30 RAM_button = 1; Output_button = 1;
#10 RAM_button = 0; Output_button = 0;
end
endmodule
<img src="https://habrastorage.org/webt/jb/fq/c4/jbfqc45piovx4besdmw0pkxz_oa.gif" />
Проверим, что когда в Асс лежит положительное число, перехода Z_JMP не происходит:
```verilog
module tR4_jmp;
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 4;
reg JMP, Z_JMP, PZ_JMP;
wire Z_flag, PZ_flag;
reg Output_button;
wire [3:0] data_out;
reg [1:0] MUX_switch;
reg Acc_button;
wire [3:0] Acc;
reg timer555, RAM_button;
wire [1:0] counter;
reg [DATA_WIDTH-1:0] data_in;
wire [DATA_WIDTH-1:0] RAM_out;
R4 test_R4
(JMP,Z_JMP,PZ_JMP,Z_flag,PZ_flag,Output_button,data_out,MUX_switch,Acc_button,Acc,
counter,timer555,RAM_button,data_in,RAM_out);
initial
begin
timer555 = 0;
forever #20 timer555 = ~timer555;
end
initial
begin
data_in[0] = 0;
data_in[1] = 0;
data_in[2] = 0;
data_in[3] = 0;
JMP = 0; Z_JMP = 0; PZ_JMP = 0;
Acc_button = 0;
RAM_button = 0;
Output_button = 0;
MUX_switch[0] = 0;
MUX_switch[1] = 0;
#5 JMP = 1;
#5 data_in[0]=0; data_in[1]=1; JMP = 0;
#5 Acc_button = 1;
#5 data_in[0]=1; data_in[1]=1; Acc_button = 1;
#5 data_in[0]=1; data_in[1]=1; Acc_button = 0;
#5 Z_JMP = 1;
#5 PZ_JMP = 1; Z_JMP = 0;
#5 PZ_JMP = 0;
end
endmodule

Поместим команду безусловного перехода в ОЗУ
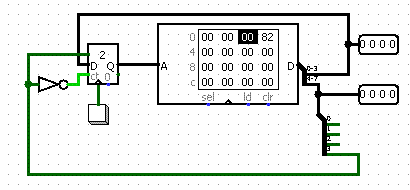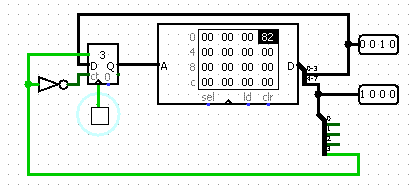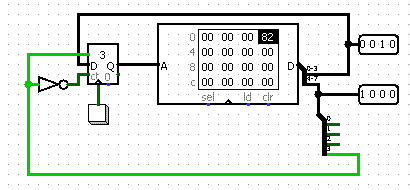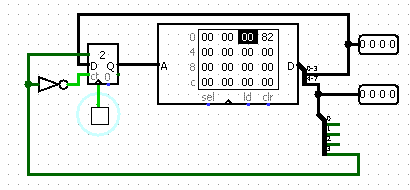
Конструкция вида
//wire Counter_load;
always @ (posedge timer555)
if (Counter_load)
counter <= RAM_out[3:0];
else
counter <= counter + 2'b01;
в ModelSim работать не будет, поэтому будем использовать дополнительную команду reset_count, которая инициализирует счетчик, обнуляя его, т.е.
module resCount (reset_count, counter, timer555,
RAM_button, data_in, RAM_out);
parameter ADDR_WIDTH = 4;
parameter DATA_WIDTH = 8;
input reset_count;
output [ADDR_WIDTH-1:0] counter;
input timer555;
input RAM_button;
input [DATA_WIDTH-1:0] data_in;
output [DATA_WIDTH-1:0] RAM_out;
wire Counter_load;
assign Counter_load = RAM_out[7];
reg [ADDR_WIDTH-1:0] counter;
always @ (posedge timer555 or posedge reset_count)
if (reset_count)
counter <= 4'b0000;
else if (Counter_load)
counter <= RAM_out[3:0];
else
counter <= counter + 4'b0001;
wire [ADDR_WIDTH-1:0] adr;
assign adr = counter;
reg [DATA_WIDTH-1:0] mem [2**ADDR_WIDTH-1:0];
always @(posedge RAM_button)
mem [adr] <= data_in;
assign RAM_out = mem[adr];
endmodule
test bench
module tresCount;
parameter ADDR_WIDTH = 4;
parameter DATA_WIDTH = 8;
reg reset_count;
reg timer555, RAM_button;
wire [ADDR_WIDTH-1:0] counter;
reg [DATA_WIDTH-1:0] data_in;
wire [DATA_WIDTH-1:0] RAM_out;
resCount test_resCount(reset_count, counter,
timer555, RAM_button, data_in, RAM_out);
initial // Clock generator
begin
timer555 = 0;
forever #20 timer555 = ~timer555;
end
initial
begin
data_in[0] = 0;
data_in[1] = 0;
data_in[2] = 0;
data_in[3] = 0;
data_in[4] = 0;
data_in[5] = 0;
data_in[6] = 0;
data_in[7] = 0;
RAM_button = 0;
reset_count =1;
#5 reset_count =0;
#1500 data_in[7] =1;
#5 RAM_button = 1;
#5 data_in[7] =0; RAM_button = 0;
end
endmodule
Добавим в схему MUX2 и Асс. Будем производить запись в Асс командой RAM_out[6].
assign Acc_button = RAM_out[6];
К тактовому входу Асс подключим лог. элемент И
//в модуле regiser4 заменим (posedge reg_button) на (negedge reg_button)
.reg_button(Acc_button & timer555),
Смысл подключения лог. элемента И к тактовому входу в том, что теперь по фронту timer555 можно переключать мультиплексор, а по спаду производить запись в аккумулятор. Т.о. мы поместили две команды в один такт.
Будем производить переключение MUX2 командой RAM_out[5]
assign MUX_switch = RAM_out[5];

module register4
(
input [3:0] reg_data,
input reg_button,
output reg [3:0] q
);
always @(negedge reg_button) // заменим "posedge" на "negedge"
q <= reg_data;
endmodule
module R50 (reset_count, counter, timer555, RAM_button, data_in,
RAM_out, mux_switch_out, mux_out,Acc_out);
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 8;
input reset_count;
output [ADDR_WIDTH-1:0] counter;
input timer555;
input RAM_button;
input [DATA_WIDTH-1:0] data_in;
output [DATA_WIDTH-1:0] RAM_out;
output [3:0] Acc_out;
output mux_switch_out;
output [3:0] mux_out;
wire Counter_load;
assign Counter_load = RAM_out[7];
//Counter
reg [ADDR_WIDTH-1:0] counter;
always @ (posedge timer555 or posedge reset_count)
if (reset_count)
counter <= 2'b00;
else if (Counter_load)
counter <= RAM_out[1:0];
else
counter <= counter + 2'b01;
wire [ADDR_WIDTH-1:0] adr;
assign adr = counter;
//RAM
reg [DATA_WIDTH-1:0] mem [2**ADDR_WIDTH-1:0];
always @(posedge RAM_button)
mem [adr] <= data_in;
assign RAM_out = mem[adr];
// MUX2
wire MUX_switch;
assign MUX_switch = RAM_out[5];
reg [3:0] MUX2;
always @*
MUX2 = MUX_switch ? RAM_out : data_in[3:0]; // возьмём 4 разряда из data_in
assign mux_out = MUX2;
assign mux_switch_out = MUX_switch;
wire Acc_button;
assign Acc_button = RAM_out[6];
//Acc
register4 Acc_reg(
.reg_data(mux_out),
.reg_button(Acc_button & timer555),
.q(Acc_out)
);
endmodule
В тестбенче запишем в ячейку 00 число 0101, а в ячейку 01 число 1010; загрузим эти числа в аккумулятор
module tR50;
parameter ADDR_WIDTH = 2;
parameter DATA_WIDTH = 8;
reg reset_count;
reg timer555, RAM_button;
wire [ADDR_WIDTH-1:0] counter;
reg [DATA_WIDTH-1:0] data_in;
wire [DATA_WIDTH-1:0] RAM_out;
wire mux_switch_out;
wire [3:0] mux_out;
wire [3:0] Acc_out;
R50 test_R50(reset_count, counter, timer555, RAM_button, data_in,
RAM_out, mux_switch_out, mux_out,Acc_out);
initial // Clock generator
begin
timer555 = 0;
forever #20 timer555 = ~timer555;
end
initial
begin
data_in[0] = 1;
data_in[1] = 0;
data_in[2] = 1;
data_in[3] = 0;
data_in[4] = 0;
data_in[5] = 1;
data_in[6] = 1;
data_in[7] = 0;
RAM_button = 0;
reset_count =1;
#5 RAM_button = 1; reset_count = 0;
#5 data_in[0]=0; data_in[2]=0; data_in[5]=0; data_in[6]=0; RAM_button=0;
#15 data_in[1]=1; data_in[3]=1; data_in[5]=1;data_in[6]=1;
#5 RAM_button=1;
#5 data_in[1]=0; data_in[3]=0; data_in[5]=0; data_in[6]=0; RAM_button=0;
end
endmodule

Поместим второе ОЗУ в общую схему и будем производить запись в ОЗУ командой RAM1_out[4].
assign RAM2_button = RAM1_out[4];

module register4
(
input [3:0] reg_data,
input reg_button,
output reg [3:0] q
);
always @(negedge reg_button)
q <= reg_data;
endmodule
module R51 (reset_count, counter, timer555, RAM1_button, data_in,
RAM1_out, RAM2_out, mux_switch_out, mux_out,Acc_out);
parameter ADDR_WIDTH = 3;
parameter DATA_WIDTH = 8;
input reset_count;
output [ADDR_WIDTH-1:0] counter;
input timer555;
input RAM1_button;
input [DATA_WIDTH-1:0] data_in;
output [DATA_WIDTH-1:0] RAM1_out;
output [3:0] RAM2_out;
output [3:0] Acc_out;
output mux_switch_out;
output [3:0] mux_out;
wire Counter_load;
assign Counter_load = RAM1_out[7];
//Counter
reg [ADDR_WIDTH-1:0] counter;
always @ (posedge timer555 or posedge reset_count)
if (reset_count)
counter <= 2'b00;
else if (Counter_load)
counter <= RAM1_out[1:0];
else
counter <= counter + 2'b01;
wire [ADDR_WIDTH-1:0] adr1;
assign adr1 = counter;
//RAM1
reg [DATA_WIDTH-1:0] mem1 [2**ADDR_WIDTH-1:0];
always @(posedge RAM1_button )
mem1 [adr1] <= data_in;
assign RAM1_out = mem1[adr1];
wire [ADDR_WIDTH-1:0] adr2;
assign adr2 = RAM1_out[3:0];
wire RAM2_button;
assign RAM2_button = RAM1_out[4];
//RAM2
reg [3:0] mem2 [2**ADDR_WIDTH-1:0];
always @(posedge RAM2_button)
mem2 [adr2] <= Acc_out;
assign RAM2_out = mem2[adr2];
// MUX2
wire MUX_switch;
assign MUX_switch = RAM1_out[5];
reg [3:0] MUX2;
always @*
MUX2 = MUX_switch ? RAM2_out : data_in[3:0];
assign mux_out = MUX2;
assign mux_switch_out = MUX_switch;
wire Acc_button;
assign Acc_button = RAM1_out[6];
//Acc
register4 Acc_reg(
.reg_data(mux_out),
.reg_button(Acc_button & timer555),
.q(Acc_out)
);
endmodule
В тестбенче загрузим числа 0100 и 1000 из Асс в нулевую 0000 и первую 0001 ячейки ОЗУ mem2 (затем загрузим эти числа в Асс из ОЗУ mem2)
module tR51;
parameter ADDR_WIDTH = 3;
parameter DATA_WIDTH = 8;
reg reset_count;
reg timer555, RAM1_button;
wire [ADDR_WIDTH-1:0] counter;
reg [DATA_WIDTH-1:0] data_in;
wire [DATA_WIDTH-1:0] RAM1_out;
wire [3:0] RAM2_out;
wire mux_switch_out;
wire [3:0] mux_out;
wire [3:0] Acc_out;
R51 test_R51(reset_count, counter, timer555, RAM1_button, data_in,
RAM1_out, RAM2_out, mux_switch_out, mux_out,Acc_out);
initial // Clock generator
begin
timer555 = 0;
forever #20 timer555 = ~timer555;
end
initial
begin
data_in[0] = 0;
data_in[1] = 0;
data_in[2] = 0;
data_in[3] = 0;
data_in[4] = 0;
data_in[5] = 0;
data_in[6] = 1;
data_in[7] = 0;
RAM1_button = 0;
reset_count =1;
#5 RAM1_button = 1; reset_count = 0;
#5 RAM1_button = 0; data_in[6] = 0;
#10 data_in[4] = 1;
#5 RAM1_button = 1;
#5 data_in[4] = 0; RAM1_button = 0;
#30 data_in[6] = 1;
#5 RAM1_button = 1;
#5 data_in[6] = 0; RAM1_button = 0;
#30 data_in[4] = 1; data_in[0] = 1;
#5 RAM1_button = 1;
#5 data_in[4] = 0; data_in[0] = 0; RAM1_button = 0;
#30 data_in[6] = 1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[6] = 0;
#30 data_in[5] = 1; data_in[6] = 1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[5] = 0; data_in[6] = 0;
#30 data_in[5] = 1; data_in[6] = 1; data_in[0] = 1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[0] = 0; data_in[5] = 0; data_in[6] = 0;
#70 data_in[2] = 1;
#80 data_in[2] = 0; data_in[3] = 1;
#40 data_in[3] = 0;
end
endmodule

Добавлю, что схема c лог. элементом И на тактовом входе аккумулятора не всегда будет работать корректно (зависит от платы). Заменим лог. элемент И на триггер Acc_dff, загрузку в триггер будем производить по отрицательному фронту (по спаду) тактового сигнала timer555, загрузку в аккумулятор будем производить по положительному фронту
// Acc_dff
reg Acc_dff;
always @(negedge timer555)
Acc_dff <= Acc_button;
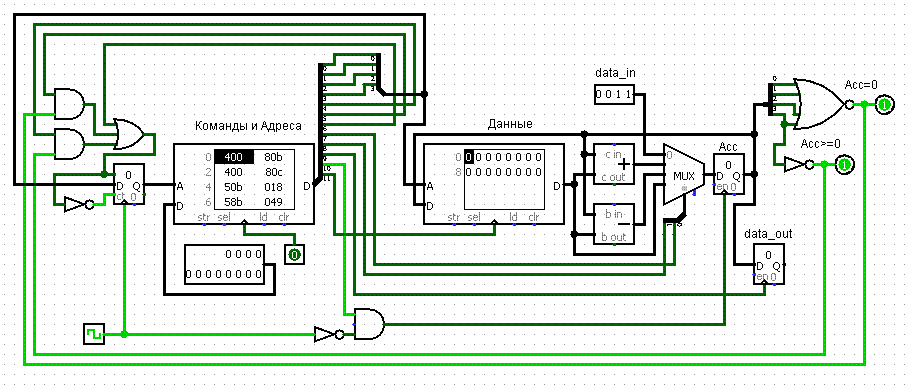
Итак, добавив остальные команды, создадим модуль R52 (LMC)

module register4
(
input [3:0] reg_data,
input reg_button,
output reg [3:0] q
);
always @(posedge reg_button) // negedge -> posedge
q <= reg_data;
endmodule
module R52 (Z_flag, PZ_flag, reset_count, counter, timer555, RAM1_button, data_in,
RAM1_out, RAM2_out, mux_switch_out, mux_out, Acc_out, data_out, Acc_dff);
parameter ADDR_WIDTH = 4;
parameter DATA_WIDTH = 12;
input reset_count;
input timer555;
input RAM1_button;
input [DATA_WIDTH-1:0] data_in;
output [ADDR_WIDTH-1:0] counter;
output [1:0] mux_switch_out;
output [3:0] mux_out;
output [3:0] Acc_out;
output [3:0] data_out;
output [DATA_WIDTH-1:0] RAM1_out;
output [3:0] RAM2_out;
output Z_flag, PZ_flag;
output Acc_dff;
wire JMP_button, Z_JMP_button,PZ_JMP_button;
assign JMP_button = RAM1_out[6];
assign Z_JMP_button = RAM1_out[5];
assign PZ_JMP_button = RAM1_out[4];
wire Z_JMP,PZ_JMP;
assign Z_JMP = Z_flag & Z_JMP_button;
assign PZ_JMP = PZ_flag & PZ_JMP_button;
//Counter
reg [ADDR_WIDTH-1:0] counter;
always @ (posedge timer555 or posedge reset_count)
if (reset_count)
counter <= 4'b0000;
else if (JMP_button|Z_JMP|PZ_JMP)
counter <= RAM1_out[3:0];
else
counter <= counter + 4'b0001;
wire [ADDR_WIDTH-1:0] adr1;
assign adr1 = counter;
//RAM1
reg [DATA_WIDTH-1:0] mem1 [2**ADDR_WIDTH-1:0];
always @(posedge RAM1_button )
mem1 [adr1] <= data_in;
assign RAM1_out = mem1[adr1];
//RAM2_adr
wire [ADDR_WIDTH-1:0] adr2;
assign adr2 = RAM1_out[2:0];
//RAM2_button
wire RAM2_button;
assign RAM2_button = RAM1_out[11];
//RAM2
reg [3:0] mem2 [2**ADDR_WIDTH-1:0];
always @(posedge RAM2_button)
mem2 [adr2] <= Acc_out;
assign RAM2_out = mem2[adr2];
// sum
wire [3:0] sum;
assign sum = Acc_out + RAM2_out;
//subtract
wire [3:0] subtract;
assign subtract = Acc_out - RAM2_out;
// MUX4
wire [1:0] mux_switch;
assign mux_switch[0] = RAM1_out[7];
assign mux_switch[1] = RAM1_out[8];
reg [3:0] MUX4;
always @*
MUX4 = mux_switch[1] ? (mux_switch[0] ? RAM2_out : subtract)
: (mux_switch[0] ? sum : data_in[3:0]);
assign mux_out = MUX4;
assign mux_switch_out[0] = mux_switch[0];
assign mux_switch_out[1] = mux_switch[1];
//Acc_button
wire Acc_button;
assign Acc_button = RAM1_out[10];
// Acc_dff
reg Acc_dff;
always @(negedge timer555)
Acc_dff <= Acc_button;
//Acc
register4 Acc_reg(
.reg_data(mux_out),
//.reg_button(Acc_button & timer555),
.reg_button(Acc_dff),
.q(Acc_out)
);
//data_out
wire Output_button;
assign Output_button = RAM1_out[9];
register4 Output_reg(
.reg_data(Acc_out),
.reg_button(Output_button),
.q(data_out)
);
// flags
assign Z_flag = ~(|Acc_out);
assign PZ_flag = ~Acc_out[3];
endmodule
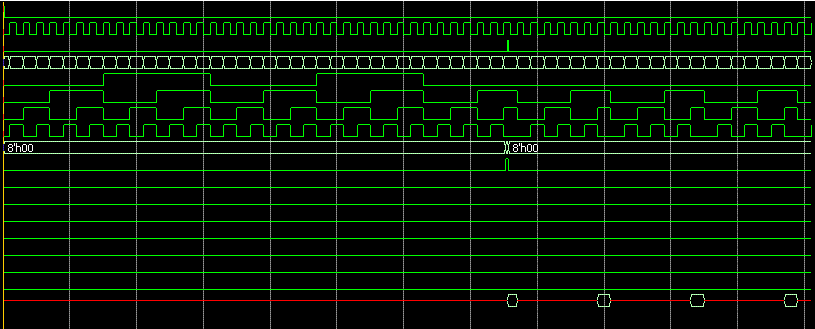
В тестбенче проверим, как работает алгоритм поиска максимального числа.
Особенность загрузки команд в ОЗУ заключается в том, что после загрузки всех команд нам приходится возвращаться (340ns) в ячейку 8 и загружать ещё одну команду
module tR52;
parameter ADDR_WIDTH = 4;
parameter DATA_WIDTH = 12;
reg reset_count;
reg timer555;
reg RAM1_button;
reg [DATA_WIDTH-1:0] data_in;
wire [ADDR_WIDTH-1:0] counter;
wire [1:0]mux_switch_out;
wire [3:0] mux_out;
wire [3:0] Acc_out;
wire [3:0] data_out;
wire [DATA_WIDTH-1:0] RAM1_out;
wire [3:0] RAM2_out;
wire Z_flag, PZ_flag;
wire Acc_dff;
R52 test_R52(Z_flag, PZ_flag, reset_count, counter, timer555, RAM1_button, data_in,
RAM1_out, RAM2_out, mux_switch_out, mux_out,Acc_out, data_out, Acc_dff);
initial // Clock generator
begin
timer555 = 0;
forever #20 timer555 = ~timer555;
end
initial
begin
data_in[0] = 0;
data_in[1] = 0;
data_in[2] = 0;
data_in[3] = 0;
data_in[4] = 0;
data_in[5] = 0;
data_in[6] = 0;
data_in[7] = 0;
data_in[8] = 0;
data_in[9] = 0;
data_in[10] = 1;
data_in[11] = 0;
RAM1_button = 0;
reset_count =1;
// загружаем 1-ое число в Асс
#5 RAM1_button = 1; reset_count = 0;
#5 RAM1_button = 0; data_in[10] = 0; data_in[0] = 0;
// сохраняем 1-ое число в ячейке 0
#10 data_in[11] = 1;
#5 RAM1_button = 1;
#5 data_in[11] = 0; RAM1_button = 0;
// загружаем 2-ое число в Асс
#30 data_in[10] = 1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[10] = 0;
// сохраняем 2-ое число в ячейке 0
#30 data_in[11] = 1;data_in[0] = 1;
#5 RAM1_button = 1;
#5 data_in[11] = 0;data_in[0] = 0; RAM1_button = 0;
//вычитаем 1-ое число из Асс
#30 data_in[8]=1; data_in[10] = 1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[8]=0; data_in[10] = 0;
// Если Acc>=0, переходим на ячейку 8
#30 data_in[4]=1; data_in[3]=1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[4]=0; data_in[3]=0;
// загружаем 1-ое число
#30 data_in[7] = 1; data_in[8] = 1; data_in[10] = 1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[7] = 0; data_in[8] = 0; data_in[10] = 0;
// безусловный переход в ячейку 9
#30 data_in[6] = 1; data_in[3]=1; data_in[0]=1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[6] = 0; data_in[3]=0; data_in[0]=0;
//выводим число в data_out
#30 data_in[9] = 1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[9] = 0;
// безусловный переход в ячейку 8
#30 data_in[6] = 1; data_in[3]=1; data_in[0]=0;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[6] = 0; data_in[3]=0; data_in[0]=0;
//загружаем 2-ое число
#30 data_in[7] = 1; data_in[8] = 1; data_in[10] = 1; data_in[0] = 1;
#5 RAM1_button = 1;
#5 RAM1_button = 0; data_in[7] = 0; data_in[8] = 0; data_in[10] = 0; data_in[0] = 0;
#75 RAM1_button = 1;
#5 RAM1_button = 0;
#230 data_in[2]=1; data_in[0]=0; //первое число
#80 data_in[2]=0; data_in[0]=1; // второе число
end
endmodule
Ссылка на github с кодами программ.
Бесплатную студенческую версию ModelSim под Windows можно скачать с сайта www.model.com.
Далее необходимо (заполнив форму) скачать файл student_license.dat и поместить этот файл в основную директорию программы ModelSim.
Ссылка на файл ModelSim под Linux (Ubuntu) здесь
Инструкция по установке здесь.

 Долгое время я мечтал научиться работать с FPGA, присматривался. Потом купил отладочную плату, написал пару hello world-ов и положил плату в ящик, поскольку было непонятно, что с ней делать. Потом пришла идея: а давайте напишем генератор композитного видеосигнала для древнего ЭЛТ-телевизора. Идея, конечно, забавная, но я же Verilog толком не знаю, а так его ещё и вспоминать придётся, да и не настолько этот генератор мне нужен… И вот недавно захотелось посмотреть в сторону RISC-V софт-процессоров. Нужно с чего-то начать, а код Rocket Chip (это одна из реализаций) написан на Chisel — это такой DSL для Scala. Тут я внезапно вспомнил, что два года профессионально разрабатываю на Scala и понял: время пришло...
Долгое время я мечтал научиться работать с FPGA, присматривался. Потом купил отладочную плату, написал пару hello world-ов и положил плату в ящик, поскольку было непонятно, что с ней делать. Потом пришла идея: а давайте напишем генератор композитного видеосигнала для древнего ЭЛТ-телевизора. Идея, конечно, забавная, но я же Verilog толком не знаю, а так его ещё и вспоминать придётся, да и не настолько этот генератор мне нужен… И вот недавно захотелось посмотреть в сторону RISC-V софт-процессоров. Нужно с чего-то начать, а код Rocket Chip (это одна из реализаций) написан на Chisel — это такой DSL для Scala. Тут я внезапно вспомнил, что два года профессионально разрабатываю на Scala и понял: время пришло...