Как создать API в облаке менее чем в 200 строках кода
Сложный
13 мин
Туториал
Перевод
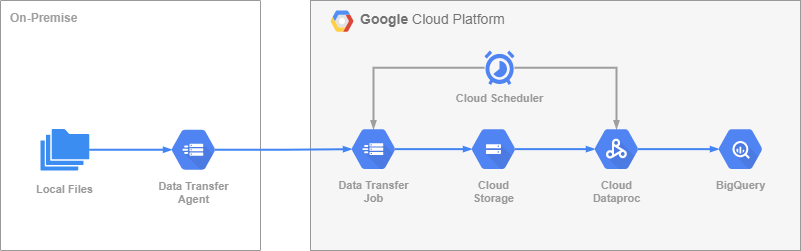
Современные облачные инструменты и пакеты Python стали настолько мощными, что с их помощью можно создать (масштабируемый) облачный API менее чем в 200 строках кода. В этом посте будет рассмотрено, как при помощи lines Google Cloud, Terraform и FastAPI развернуть в облаке полноценный API, через который можно отвечать на запросы.
Репозиторий к этому проекту находится здесь, пользуйтесь им, если захотите опробовать весь код сами.
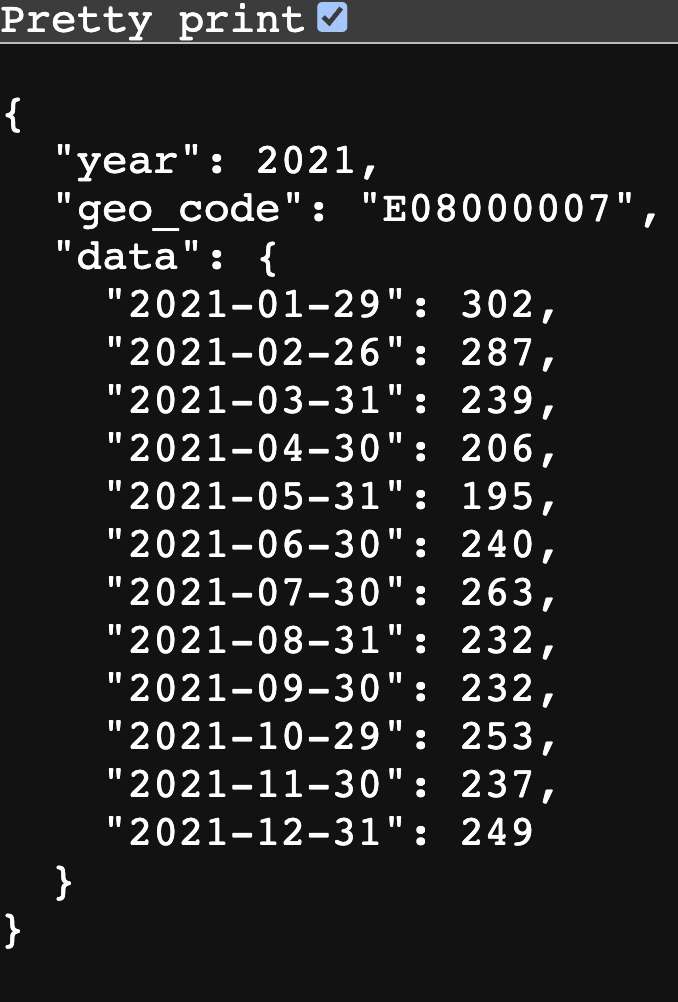
Пример API, возвращающего данные. О том, как его создать, рассказано в этом посте.
Репозиторий к этому проекту находится здесь, пользуйтесь им, если захотите опробовать весь код сами.
Пример API, возвращающего данные. О том, как его создать, рассказано в этом посте.