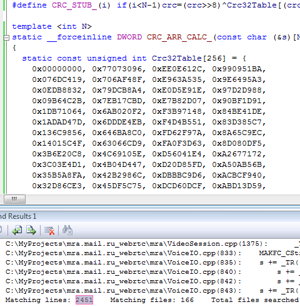
По своей программистской природе я очень не люблю неоптимальность и избыточность в коде. И вот, читая в очередной раз на работе исходный код нашего проекта, вновь наткнулся на одну особенность в способе реализации перевода строк продукта на разные языки.
Локализация здесь осуществляется довольно нехитро. Все строки, требующие перевода, оборачиваются в макрос
_TR():
wprintf(L"%s\n", _TR("Some translating string"));
Макрос возвращает нужную версию текста в зависимости от текущего используемого языка. Определён он следующим образом:
#define _TR(x) g_Translator.Translate(x)
Здесь происходит обращение к глобальному объекту
g_Translator, который в функции
Translate() считает в рантайме crc32 от указанной строки, ищет в своей xml-базе перевод с совпадающей контрольной суммой и возвращает его.
Не буду судить насколько такое решение оправдано, но оно проверено временем и показало себя достаточно надёжным. И всё бы ничего, но такое решение не лишено недостатков: по сути, функция делает лишнюю работу — контрольные суммы можно было бы подсчитать один раз на этапе компиляции, и использовать в дальнейшем уже готовые числовые значения. Это также избавило бы от необходимости хранить в исполняемом образе дублирующиеся строки, ведь они уже есть во внешнем xml-файле с переводами.
Немного погуглив по запросу «compile-time crc32» я быстро понял, что задача это не самая тривиальная, а готовых решений мне найти так и не удалось.

 История
История  На сайте
На сайте 
 чего и вам от души желаю.
чего и вам от души желаю.