Как мы делаем веб-сервис для автоматизации рабочих задач на базе агентов LLM
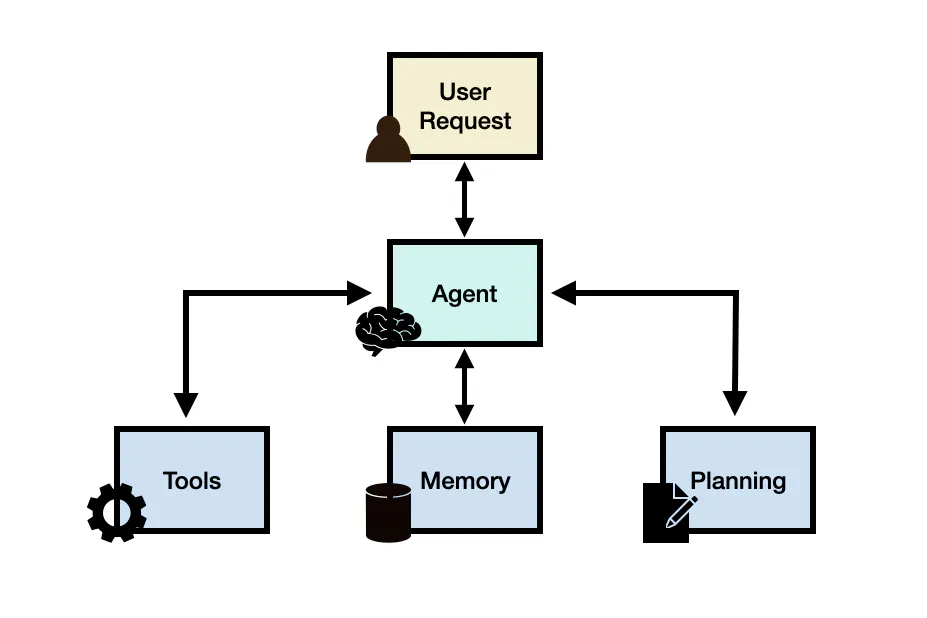
Друзья, всем привет! Сегодня хотим рассказать про то, как мы — Виталий, Даниил, Роберт и Никита — при поддержке AI Talent Hub, совместной магистратуры Napoleon IT и ИТМО, создаем Цифработа — сервис цифровых работников, который помогает оптимизировать временные затраты у сотрудников на выполнение рабочих задач с помощью агентов больших языковых моделей (LLM).
В данной статье мы вкратце рассмотрим, кто такие агенты, как они могут автоматизировать рабочие процессы, и обсудим ключевые вызовы, с которыми мы столкнулись при разработке сервиса. Сразу хочется отметить, что данная статья, скорее, служит обзором нашего решения проблемы и тех задач, над которыми мы работали, нежели преследует цель предоставить подробное руководство по применению агентов или проектированию архитектуры сервиса.
Предлагаем начинать!