
Цикл статей «Логика сознания» подошел к своей середине. Семь предыдущих частей были посвящены описанию паттерно-волновой модели распространения информации в мозгу, присущего этой модели механизма квазиголографической памяти, смысловой модели информации и того как миниколонки коры создают пространство вычисления контекстов.
Предлагаемая модель не относится к мейнстриму нейронауки. Большинство современных исследователей считают, что искусственные нейронные сети и биологические нейронные конструкции близки по своей сути и основаны на общих принципах. В нашей модели, мозг не имеет ничего общего с нейронными сетями. Различие приблизительно такое же, как между классической и квантовой механикой. Внешне результаты местами могут быть похожи, но в основе лежат совершенно разные принципы.






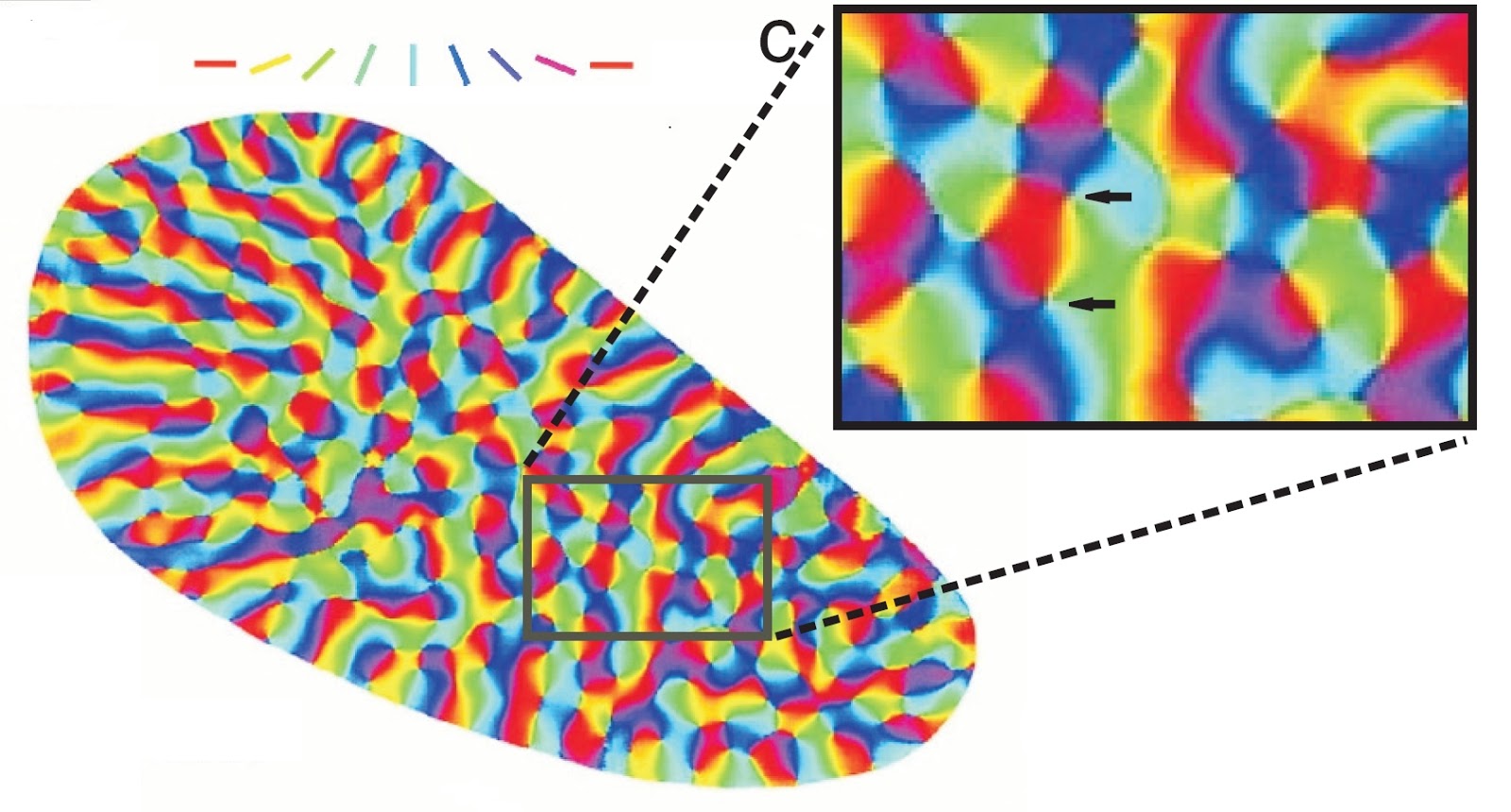



 Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований
Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований 

