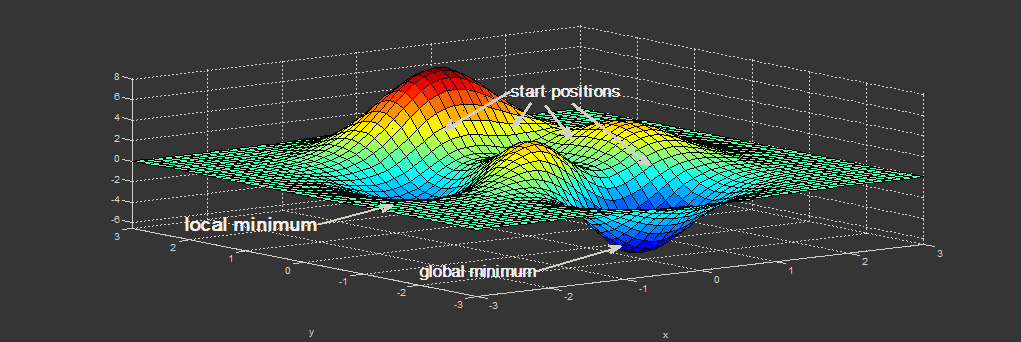
Технология машинного обучения вызывает интерес у мировых финтех-компаний и финансовых организаций, чей бизнес так или иначе связан с инвестициями, кредитованием, консалтингом и решениями в области безопасности. Мы в компании PayOnline, специализирующейся на автоматизации приема онлайн-платежей, решили рассмотреть международные финтех-кейсы применения технологии машинного обучения.
Технология машинного обучения вызывает интерес у мировых финтех-компаний и финансовых организаций, чей бизнес так или иначе связан с инвестициями, кредитованием, консалтингом и решениями в области безопасности. Мы в компании PayOnline, специализирующейся на автоматизации приема онлайн-платежей, решили рассмотреть международные финтех-кейсы применения технологии машинного обучения.В 80-х появились компьютеры, и постепенно мы наблюдали, как их использование для хранения и обработки информации становилось нормой для большинства компаний. В 90-х мы стали свидетелями интернет-бума, по-настоящему изменившего мир. Собрать информацию о чем-либо сегодня — сущий пустяк. В середине прошлого десятилетия появились социальные сети и предприниматели заметили, что клиенты начали проводить в них столько времени, сколько до этого не проводили ни на одном другом сайте. В итоге бизнесмены по всему миру начали инвестировать в социальные медиа для увеличения охвата аудитории и в маркетинговых целях. Когда широкой публике были представлены Android и iOS, произошел сдвиг парадигмы. Люди стали проводить больше времени со своими смартфонами, нежели персональными компьютерами. Со временем потребители начали пользоваться смартфонами для принятия решений, совершения покупок и даже платежей. Сегодня, поняв, что смартфоны стали неотъемлемой частью процесса принятия потребителем решений, компании стремятся предоставить им омниканальный опыт взаимодействия. В связи с этим возникает вопрос: «Какие еще существуют инновационные инструменты, способные изменить рынок?» Вероятно, компаниям следует обратить внимание на использование алгоритмов машинного обучения.

 Наша облачная платформа Voximplant — это не только телефонные и видео звонки. Это еще и набор «батареек», которые мы постоянно улучшаем и расширяем. Одна из самых популярных функций: возможность синтезировать речь, просто вызвав JavaScript метод say во время звонка. Разрабатывать свой синтезатор речи — на самая лучшая идея, мы все-таки специализируемся на телеком бэкенде, написанном на плюсах и способном обрабатывать тысячи одновременных звонков и снабжать каждый из них JavaScript логикой в реальном времени. Мы используем решения партнеров и внимательно следим за всем новым, что появляется в индустрии. Хочется через несколько лет отойти от мема «Железная Женщина» :) Статья, адаптированный перевод которой мы сделали за эти выходные, рассказывает про WaveNet, модель для генерации звука (звуковых волн). В ней мы рассмотрим как WaveNet может генерировать речь, которая похожа на голос любого человека, а также звучать гораздо натуральнее любых существующих Text-to-Speech систем, улучшив качество более чем на 50%.
Наша облачная платформа Voximplant — это не только телефонные и видео звонки. Это еще и набор «батареек», которые мы постоянно улучшаем и расширяем. Одна из самых популярных функций: возможность синтезировать речь, просто вызвав JavaScript метод say во время звонка. Разрабатывать свой синтезатор речи — на самая лучшая идея, мы все-таки специализируемся на телеком бэкенде, написанном на плюсах и способном обрабатывать тысячи одновременных звонков и снабжать каждый из них JavaScript логикой в реальном времени. Мы используем решения партнеров и внимательно следим за всем новым, что появляется в индустрии. Хочется через несколько лет отойти от мема «Железная Женщина» :) Статья, адаптированный перевод которой мы сделали за эти выходные, рассказывает про WaveNet, модель для генерации звука (звуковых волн). В ней мы рассмотрим как WaveNet может генерировать речь, которая похожа на голос любого человека, а также звучать гораздо натуральнее любых существующих Text-to-Speech систем, улучшив качество более чем на 50%.



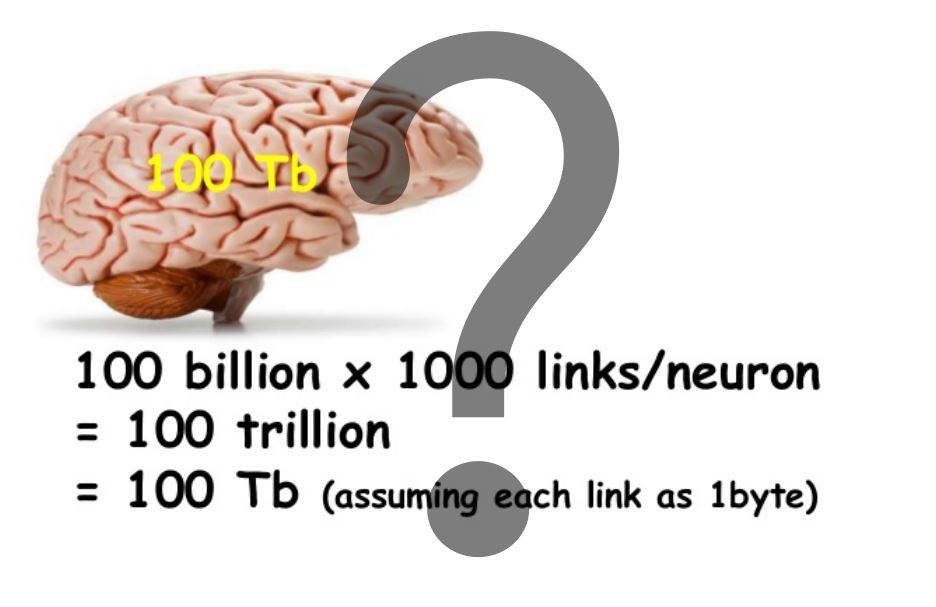 Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
 Хабр, привет! Приглашаем вас на форум Data Science Week, который проходит при поддержке DCA.
Хабр, привет! Приглашаем вас на форум Data Science Week, который проходит при поддержке DCA. 

 Ранее мы описали клеточный автомат, в котором могут возникать волны, имеющие хитрый внутренний узор. Мы показали, что такие волны способны распространять информацию по поверхности автомата. Оказалось, что любое место автомата может быть, как приемником, так и источником волн. Чтобы принять волну в каком-либо месте, достаточно посмотреть, какой узор получается в нем в момент прохождения волны. Если этот узор запомнить и впоследствии воспроизвести в том же месте, то от этого узора распространится волна, повторяющая на своем пути узор исходной волны.
Ранее мы описали клеточный автомат, в котором могут возникать волны, имеющие хитрый внутренний узор. Мы показали, что такие волны способны распространять информацию по поверхности автомата. Оказалось, что любое место автомата может быть, как приемником, так и источником волн. Чтобы принять волну в каком-либо месте, достаточно посмотреть, какой узор получается в нем в момент прохождения волны. Если этот узор запомнить и впоследствии воспроизвести в том же месте, то от этого узора распространится волна, повторяющая на своем пути узор исходной волны.
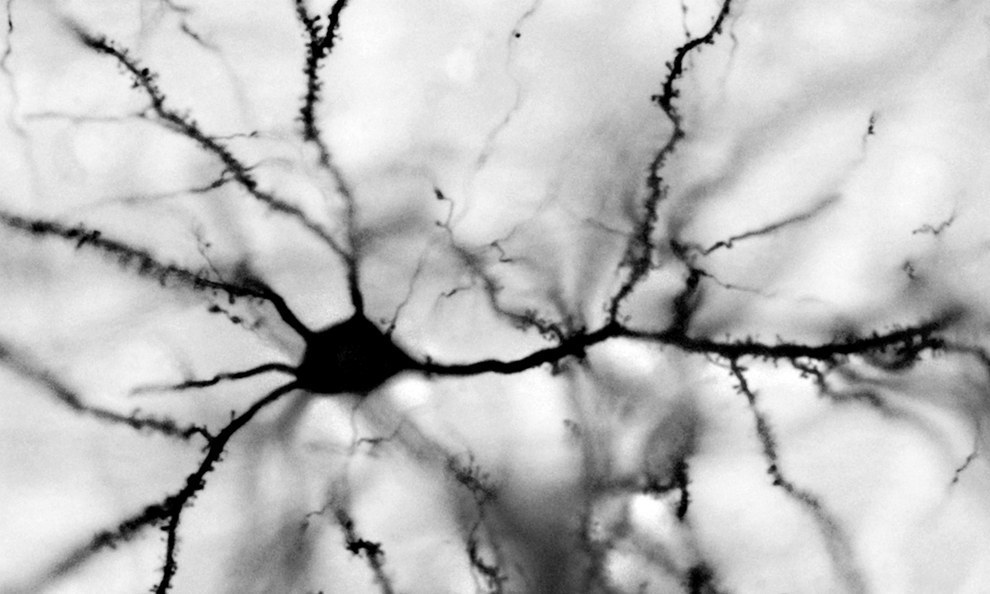 В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.
В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.