Речь, как ни странно, пойдёт о использующем свёрточную сеть классификаторе текстов (векторизация отдельных слов — это уже другой вопрос). Код, тестовые данные и примеры их применения — на bitbucket (уперся в ограничения размера от github и предложение применить Git Large File Storage (LFS), пока не осилил предлагаемое решение).
Использованы конвертированные наборы: reuters — 22000 записей, watson-й — 530 записей, и ещё 1 watson-й — 50 записей. Кстати, не отказался бы от подкинутого в комменты/ЛС (но лучше таки в комменты) набора текстов на русском.
За основу взята одна реализация описанной тут сети. Код использованной реализации на github.
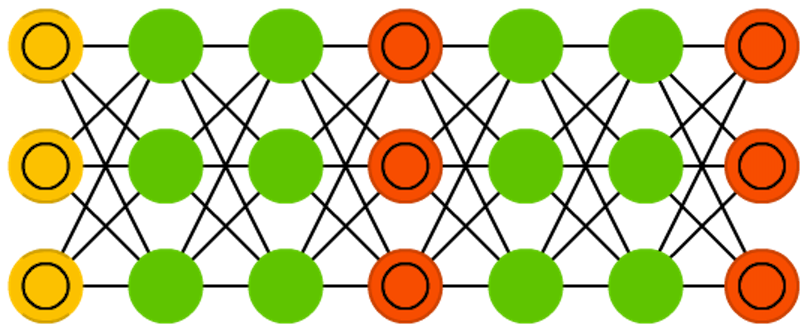
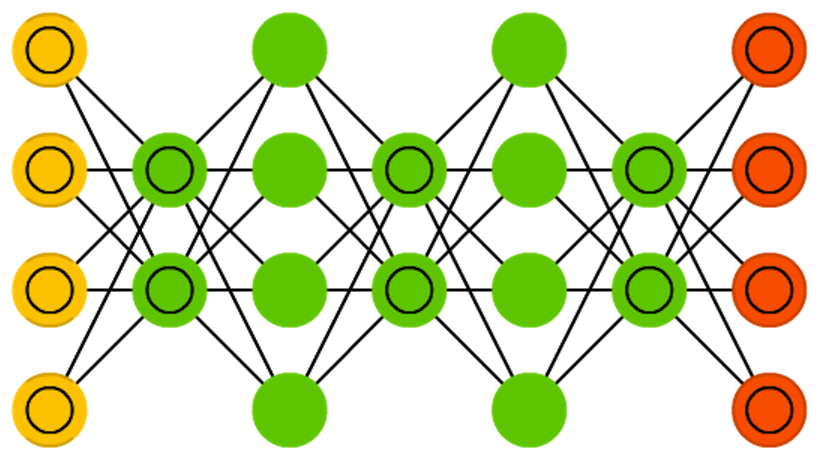
В моём случае — на входе сети находятся векторы слов (использована gensim-я реализация word2vec). Структура сети изображена ниже:

Вкратце:
Стоп слова отфильтровываю предварительно (на reuter-м dataset-е это не сказывалось, но в меньших по объему наборах — оказало влияние). Об этом ниже.
Наборы данных
Использованы конвертированные наборы: reuters — 22000 записей, watson-й — 530 записей, и ещё 1 watson-й — 50 записей. Кстати, не отказался бы от подкинутого в комменты/ЛС (но лучше таки в комменты) набора текстов на русском.
Устройство сети
За основу взята одна реализация описанной тут сети. Код использованной реализации на github.
В моём случае — на входе сети находятся векторы слов (использована gensim-я реализация word2vec). Структура сети изображена ниже:
Вкратце:
- Текст представляется как матрица вида word_count x word_vector_size. Векторы отдельных слов — от word2vec, о котором можно почитать, например, в этом посте. Так как заранее мне неизвестно, какой текст подсунет пользователь — беру длину 2 * N, где N — число векторов в длиннейшем тексте обучающей выборки. Да, ткнул пальцев в небо.
- Матрица обрабатывается свёрточными участками сети (на выходе получаем преобразованные признаки слова)
- Выделенные признаки обрабатываются полносвязным участком сети
Стоп слова отфильтровываю предварительно (на reuter-м dataset-е это не сказывалось, но в меньших по объему наборах — оказало влияние). Об этом ниже.