Машинное обучение втягивает в свою орбиту все новых энтузиастов. Таким энтузиастом стал я несколько лет назад. Я – представитель одной из групп «примкнувших», экономист с практикой работы с данными. Данные – всегда проблема в экономической науке (таковой и осталась, впрочем) и было легко купиться на мантру «большие данные». От больших данных было легко перейти, вслед за Гарнтером в 2016, к машинному обучению.
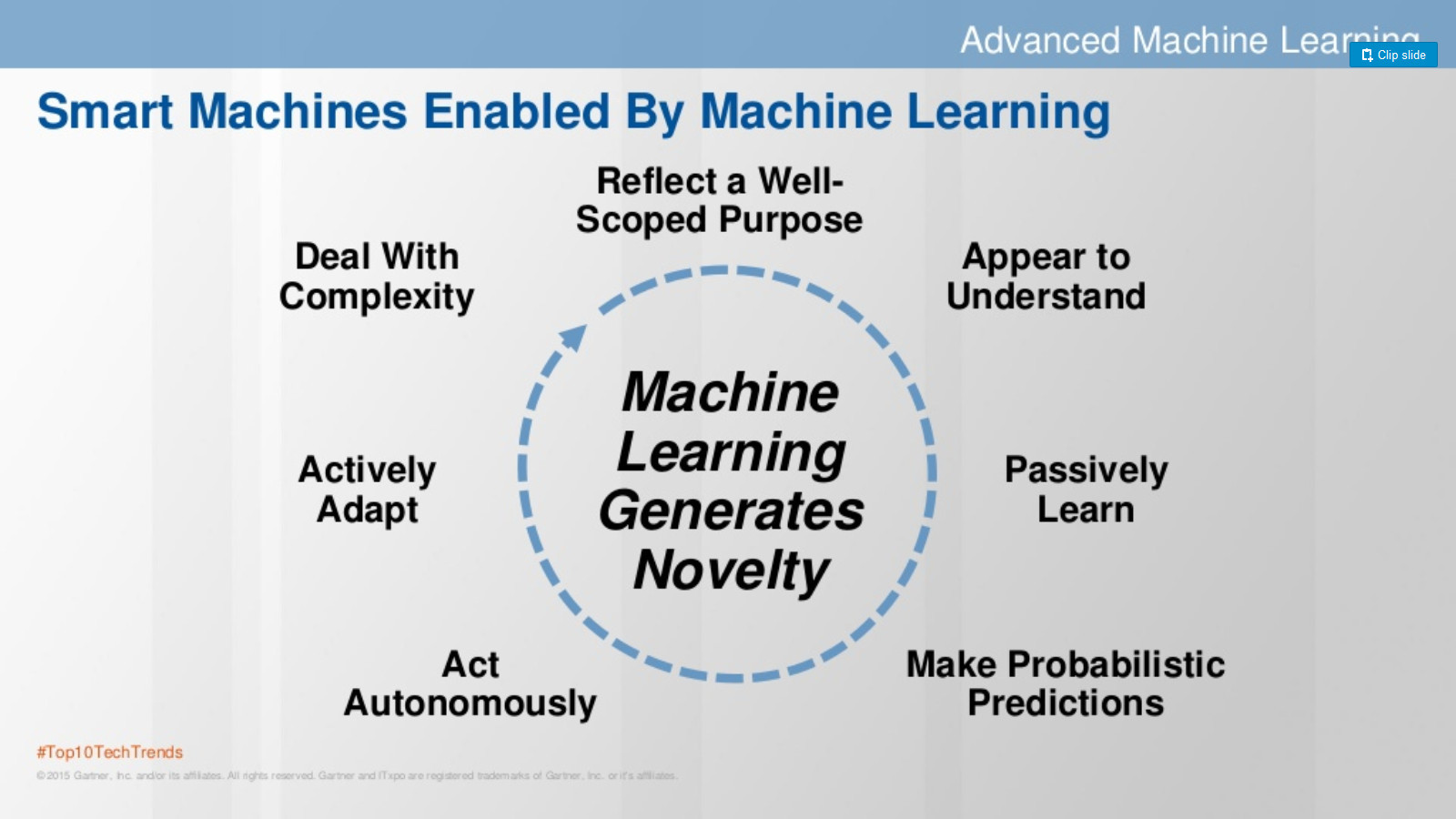
Чем больше занимаешься этой темой, тем более интересно становится, особенно в свете происходящих предсказаний типа наступления эры роботов, умных машин и т.п. И это не удивительно, что такие машины будут созданы, т.к. эволюция показывает, что человек учится расширять себя, создавая симбиоз человек-машина. Бывает идешь у своего забора, торчит гвоздь. Ох как трудно его забить без молотка. А молотком – раз и там. Поэтому не удивительно, что появляются такие же «помощники» для мозговой деятельности.
По ходу изучения темы, я не переставал думать о том, что, кажется, машинное обучение объясняет, как устроен наш разум. Ниже я перечислю уроки, которые я извлек о человеке, изучая машинное обучение. Не претендую на правоту, приношу извинения, если все это очевидно, буду рад, если материал позабавит, или если будут контр-примеры, чтобы начать (опять) жить верой в «непонятное». Кстати, у Вышки
есть курс, где машинное обучение используется для понимания работы мозга.