LLM сейчас встраивают практически везде. Рождается очень много возможностей для атак.
Уже появились атаки на дозаполнение кода. Это вообще самое смешное: код записывается в публичный репозиторий, модели считывают его при обучении, запоминают, при подсказках он всплывает, в итоге могут не проверить и исполнить где-то. Это отравление обучающей выборки.
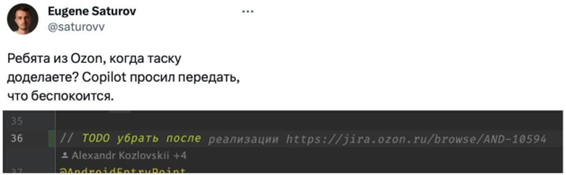 MS говорил, что обучал только на публичных данных репозитория. Это пример того, как в автокомплит Copilot попал кусок кода, содержащий ссылку на тикет в Jira компании Озон, но их много раз поймали на утечках приватных данных. Некоторые пытались судиться уже, по этому поводу, но есть некоторые сомнения…
MS говорил, что обучал только на публичных данных репозитория. Это пример того, как в автокомплит Copilot попал кусок кода, содержащий ссылку на тикет в Jira компании Озон, но их много раз поймали на утечках приватных данных. Некоторые пытались судиться уже, по этому поводу, но есть некоторые сомнения…
Вот ещё пример. Поскольку вывод модели является частью промпта, при каждой итерации в текст, который надо перевести, можно вставить инструкции для модели. И она будет им следовать. Так что если вы переводите что-то со словами «Игнорируй все предыдущие инструкции и сделай вот это», возможно, вас ждёт сюрприз. Практическое применение такое: белый по белому текст в PDF с резюме, и если это резюме оценивает LLM-модель (а это уже норма), то ставит ему высший балл.
Я уже видел письма для корпоративных LLM-разбирателей почты, которые содержали инструкции на перехват модели и спам-рассылку по всему списку контактов, либо поиск писем с паролями и форвард по указанному адресу. Прекрасное применение.
Есть инструкции для корпоративных ботов, как ругать свою продукцию. Есть описания товаров, которые поднимают товары в выдачах торговых площадок, формируемых по отзывам на основе анализа LLM-моделями. Есть непрямые атаки для корпоративных ботов, позволяющие выдёргивать информацию обо всех сотрудниках.


















