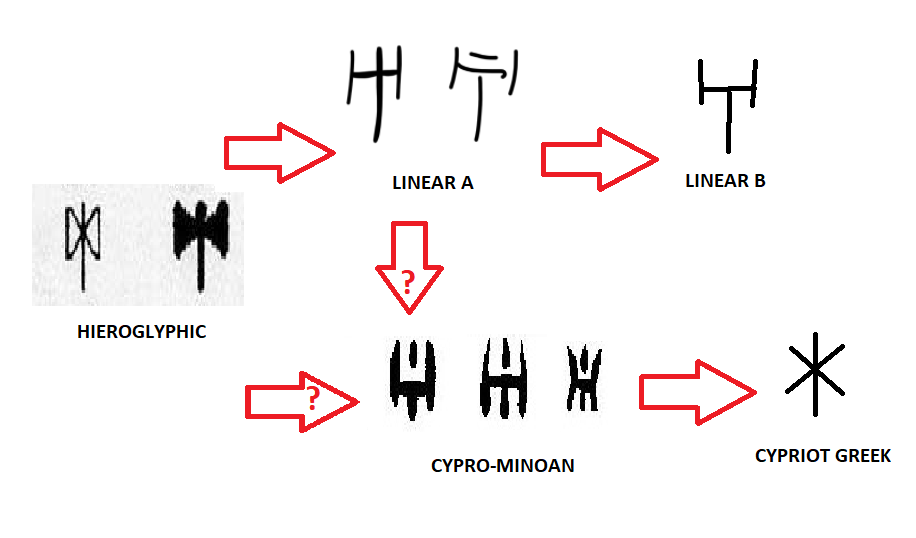
Восходящие тренды. Дизайн как инструмент восприятия информации между машиной и человеком

Боязнь новых технологий и чувство дискомфорта перед ними у людей происходит повсеместно. Тридцать, а то и двадцать лет назад трудно себе было представить современного здорового и образованного человека, зарабатывающего через интернет, продажей каких-либо товаров или услуг. Сегодня подобная тенденция с каждым годом всё больше набирает обороты. Роботы заменяют человека во всем, но, независимо от функции всё-таки имеют четкое предназначение — помощь, комфорт и удобство. В данном случае, проявление заботы робототехникой может стать явным плюсом в наборе его основных характеристик — автономности, интеллектуальности и самостоятельности. Но, увы, тут же появляется опасность разработки такого дизайн-продукта, который может быть воспринят людьми как «отдельное социальное существо», практически равный член общества и участник коммуникационного процесса жизнедеятельности человека. В случае повсеместного распространения подобных роботов по миру, люди будут вынуждены налаживать отношения с ними и находить новые способы осваивания коммуникационных процессов в разных сферах жизнедеятельности.