В
первом посте об этой игре я рассказал о технических сложностях, которые пришлось преодолеть. Второй пост, который вы сейчас читаете — более лёгкий для восприятия. Здесь я проиллюстрирую гифками весь путь построения физической модели и кратко расскажу о каждом шаге.
От создания нового проекта в Юнити до публикации бета-версии в Стиме прошло 10 месяцев. 90% времени ушло на создание, оптимизацию и вылизывание физической модели, остальное — на геймплей.
Цель была в том, чтобы создать полностью физический мир. Но подход, реализованный в Red Faction показался слишком громоздким и не слишком реалистичным. В той игре меши при взрыве разбивались на куски, на которые натягивались физические коллайдеры. Я решил не мучаться с сопроматом и множеством частных случаев разрушений, а сделать простую систему, работающую во всех случаях.
Сделал всё из взаимодействующих частиц: землю, здания, танки игроков, врагов, снаряды и бонусы — всё. Взаимодействия между частицами реализовал на видеокарте, поскольку для параллельных вычислений она в 50-100 раз производительней процессора.
Получившаяся из частиц материя сначала выглядела странно, и напоминала то ли жидкость, то ли газ:

А для игры нужно было что-то прочное, способное держать форму. Испробовав разные способы взаимодействия частиц, я нашёл, что сила Леннарда-Джонса даёт самую прочную субстанцию. Получилось что-то вроде манной каши. Для экспериментов я добавил взрывы по клику мыши.







 Поэзия — та же добыча радия.
Поэзия — та же добыча радия.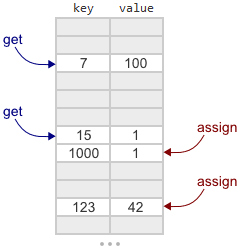




 В предыдущей части были сформулированы требования к процедуре универсального обобщения. Одно из требований гласило, что результат обобщения должен не просто содержать набор понятий, кроме этого полученные понятия обязаны формировать некое пространство, в котором сохраняются представление о том, как полученные понятия соотносятся между собой.
В предыдущей части были сформулированы требования к процедуре универсального обобщения. Одно из требований гласило, что результат обобщения должен не просто содержать набор понятий, кроме этого полученные понятия обязаны формировать некое пространство, в котором сохраняются представление о том, как полученные понятия соотносятся между собой.
 В принципе, любая информационная система сталкивается с одними и теми же вопросами. Как собрать информацию? Как ее интерпретировать? В какой форме и как ее запомнить? Как найти закономерности в собранной информации и в какой форме их записать? Как реагировать на поступающую информацию? Каждый из вопросов важен и неразрывно связан с остальными. В этом цикле мы пытаемся описать то, как эти вопросы решаются нашим мозгом. В этой части пойдет разговор о, пожалуй, самой загадочной составляющей мышления — процедуре поиска закономерностей.
В принципе, любая информационная система сталкивается с одними и теми же вопросами. Как собрать информацию? Как ее интерпретировать? В какой форме и как ее запомнить? Как найти закономерности в собранной информации и в какой форме их записать? Как реагировать на поступающую информацию? Каждый из вопросов важен и неразрывно связан с остальными. В этом цикле мы пытаемся описать то, как эти вопросы решаются нашим мозгом. В этой части пойдет разговор о, пожалуй, самой загадочной составляющей мышления — процедуре поиска закономерностей.