Низкоуровневая оптимизация параллельных алгоритмов или SIMD в .NET
12 мин
В настоящее время огромное количество задач требует большой производительности систем. Бесконечно увеличивать количество транзисторов на кристалле процессора не позволяют физические ограничения. Геометрические размеры транзисторов нельзя физически уменьшать, так как при превышении возможно допустимых размеров начинают проявляться явления, которые не заметны при больших размерах активных элементов — начинают сильно сказываться квантовые размерные эффекты. Транзисторы начинают работать не как транзисторы.
А закон Мура здесь ни при чем. Это был и остается законом стоимости, а увеличение количества транзисторов на кристалле — это скорее следствие из закона. Таким образом, для того, чтобы увеличивать мощность компьютерных систем приходится искать другие способы. Это использование мультипроцессоров, мультикомпьютеров. Такой подход характеризуется большим количеством процессорных элементов, что приводит к независимому исполнение подзадач на каждом вычислительном устройстве.

 Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.
Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.


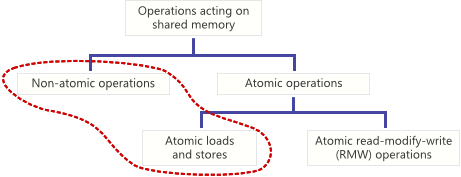

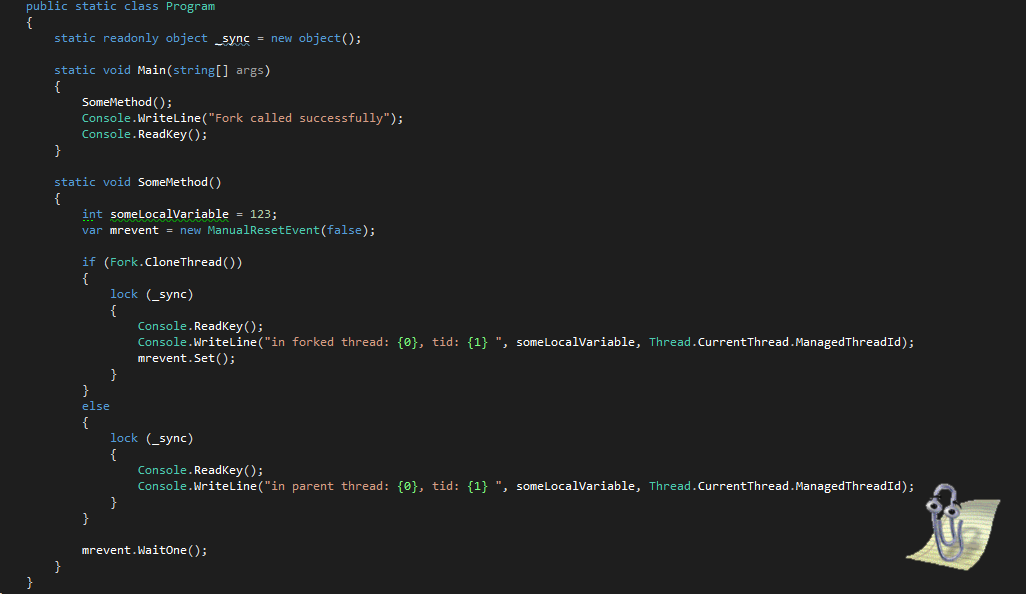

 Делаем отгружаемые сборки: взаимодействуем между доменами без маршаллинга
Делаем отгружаемые сборки: взаимодействуем между доменами без маршаллинга