Подсветка синтаксиса PostgreSQL
4 мин
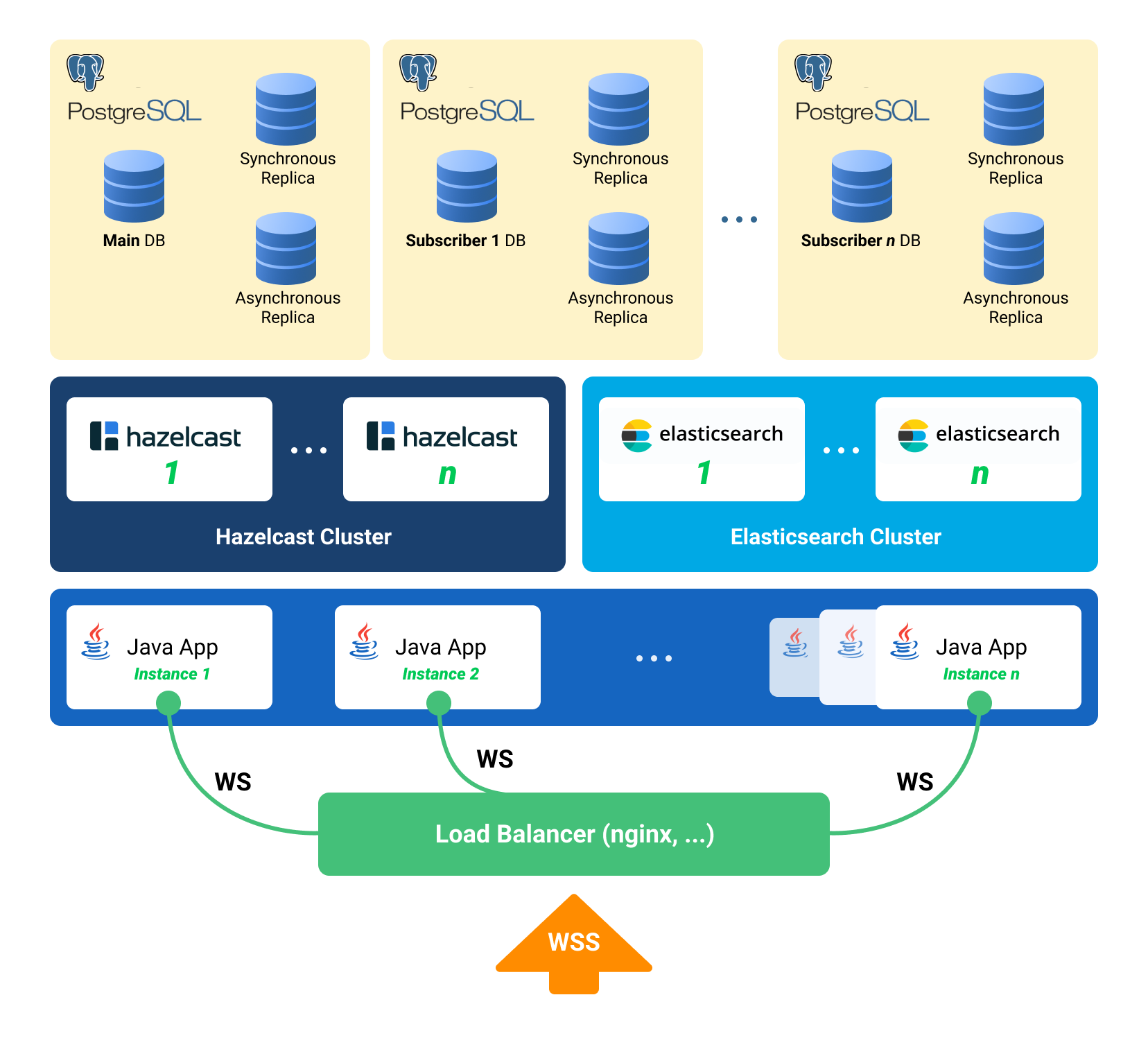
Спешу поделиться хорошей новостью: жизнь авторов статей про PostgreSQL и их читателей стала немного лучше.
Как знают все хаброписатели, для оформления исходного кода используется специальный тег
Особенно печально все было с PostgreSQL, поскольку подсветка охватывала более или менее стандартный SQL и категорически не понимала специфики нашей СУБД. Шло время, Алексей boomburum старательно исправлял мои font-ы на source (а я — обратно), пока не стало очевидно, что подсветку надо чинить. Наконец Далер daleraliyorov подсказал выход: добавить поддержку PostgreSQL в библиотеку highlightjs, которой пользуется Хабр. И вот — готово, встречайте.
Как знают все хаброписатели, для оформления исходного кода используется специальный тег
<source>, который подсвечивает синтаксис. Не секрет также, что подсветка не всегда получается идеальной, и тогда авторы (которым не все равно, как выглядят их статьи) вынуждены заниматься самодеятельностью — расцвечивать свой код с помощью <font color=...>.Особенно печально все было с PostgreSQL, поскольку подсветка охватывала более или менее стандартный SQL и категорически не понимала специфики нашей СУБД. Шло время, Алексей boomburum старательно исправлял мои font-ы на source (а я — обратно), пока не стало очевидно, что подсветку надо чинить. Наконец Далер daleraliyorov подсказал выход: добавить поддержку PostgreSQL в библиотеку highlightjs, которой пользуется Хабр. И вот — готово, встречайте.






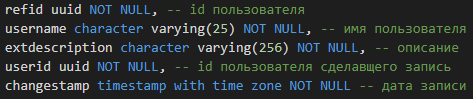


 Использовать БД только для складирования данных — это всё равно, что назвать Unix интерфейсом для работы с файлами. Посему, хочу напомнить об известных и не очень функциях БД, которые хотелось бы чаще встречать в боевых веб-приложениях.
Использовать БД только для складирования данных — это всё равно, что назвать Unix интерфейсом для работы с файлами. Посему, хочу напомнить об известных и не очень функциях БД, которые хотелось бы чаще встречать в боевых веб-приложениях.