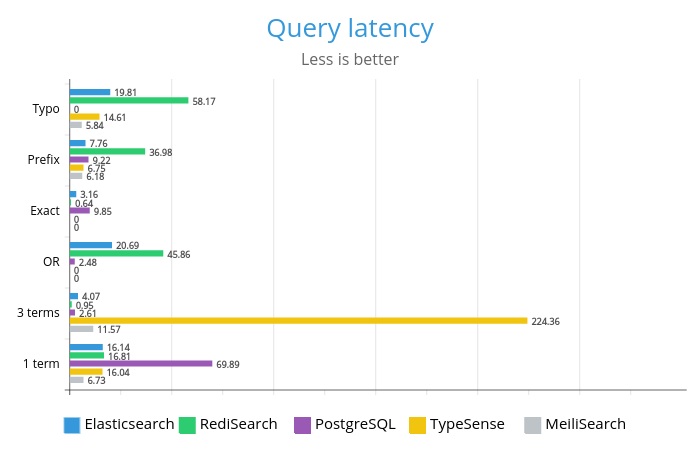
— Разве ты не понимаешь, что весь смысл новояза в том, чтобы сузить диапазон мышления? В итоге мыслепреступление станет попросту невозможным, поскольку не будет слов, которыми его можно было бы выразить.
— «1984», Джордж Оруэлл
Не так давно люди, активно интересующиеся вопросами SEO, могли заметить, что я вступил в
перебранку в твиттере с парочкой сотрудников Google. Страсти там реально накалились.
Иногда работать представителем Google за деньги бывает трудновато.
Всё началось с того, что я поставил под сомнение этичность и направленность против конкуренции таких действий Google, как поднятие в рейтинге собственных материалов, касающихся таких слов, как “SEO” и “robots.txt” (из моих областей интереса), а также Google Flights, YouTube, окошек «People Also Ask» и других особенностей поисковика, которые появляются среди самых первых результатов.
Нечестная конкуренция Google связанная с поднятием собственных сервисов в результатах поиска – проблема давно известная. Правительства разных стран проводят расследования таких действий и работают над новыми законами, касающимися этих и других проблем, связанных с монополизацией.