
Облаками можно любоваться вечность — смотреть, как разворачиваются инстансы, как скачет загрузка dashboard'a, а ping идёт десятки миллисекунд. Вот только создать свое облако — дело сложное. Нужно не только собирать сервера, но и продумать расположение в ЦОД, подключить к сети и учесть много других мелочей, которые обеспечивают комфортный полет в облаках. Мы сделали тест, для того чтобы вы могли проверить свои знания изнанки облачных технологий. Волшебства и розовых пони тут нет, только суровое серверное железо.
Поехали!
Courier: миграция Dropbox на gRPC
16 мин
Перевод

Примечание переводчика
Большинство современных программных продуктов не являются монолитными, а состоят из множества частей, которые взаимодействуют друг с другом. При таком положении дел необходимо, чтобы общение взаимодействующих частей системы происходило на одном языке (притом что сами эти части могут быть написаны на разных языках программирования и выполняться на разных машинах). Упростить решение этой задачи помогает gRPC — open-source-фреймворк от Google, выпущенный в 2015 году. Он решает сразу ряд проблем, позволяя:
- использовать язык Protocol Buffers для описания взаимодействия сервисов;
- генерировать программный код на основании описанного протокола для 11 разных языков как для клиентской части, так и для серверной;
- реализовать авторизацию между взаимодействующими компонентами;
- использовать как синхронное, так и асинхронное взаимодействие.
gRPC показался мне довольно интересным фреймворком, и мне было интересно узнать про реальный опыт компании Dropbox по построению системы на его основе. В статье есть масса деталей, связанных с использованием шифрования, построением надёжной, наблюдаемой и производительной системы, процессом миграции со старого RPC-решения на новое.
Дисклеймер
Оригинальная статья не содержит описания gRPC, и некоторые моменты могут показаться вам непонятными. Если вы не знакомы с gRPC или другими подобными фреймворками (например, Apache Thrift), рекомендую предварительно ознакомиться с основными идеями (достаточно будет прочитать две небольшие статьи с официального сайта: «What is gRPC?» и «gRPC Concepts»).
Спасибо Алексею Иванову aka SaveTheRbtz за написание оригинальной статьи и помощь с переводом трудных мест.
Спасибо Алексею Иванову aka SaveTheRbtz за написание оригинальной статьи и помощь с переводом трудных мест.
Применение DBREPLICATION при свёртке баз данных на Microsoft SQL Server
12 мин
Для корпоративных учетных систем характерно постепенное увеличение объёма баз данных из-за накопления исторической информации. С течением времени размер БД может достигать таких размеров, что это провоцирует ряд проблем с производительностью, сервисным обслуживанием, доступным дисковым пространством и прочее. Сегодня рассмотрим два подхода к решению этой проблемы: наращивание аппаратных ресурсов и свёртка исторических данных.

1. Check Point Maestro Hyperscale Network Security — новая масштабируемая security платформа
5 мин

Компания Check Point довольно резво начала 2019 год сделав сразу несколько анонсов. Рассказать обо всем в одной статье не получится, поэтому начнем с самого главного — Check Point Maestro Hyperscale Network Security. Maestro это новая масштабируемая платформа, которая позволяет наращивать «мощность» шлюза безопасности до «неприличных» цифр и практически линейно. Достигается это естественно за счет балансировки нагрузки между отдельными шлюзами, которые работают в кластере, как единая сущность. Кто-то может сказать — "Было! Уже есть блейд-платформы 44000/64000". Однако Maestro это совсем другое дело. В рамках этой статьи я вкратце постараюсь объяснить что это, как это работает и как эта технология поможет сэкономить на защите периметра сети.
Архитектура, сертифицированная по SQL Server Data Warehouse Fast Track (DWFT): что это значит и как устроено
10 мин
Крупные производители популярного софта заботятся о своих заказчиках по-разному. Один из способов — создать программу сертификации. Чтобы, когда заказчики в раздумьях блуждают между аппаратными конфигами для конкретного софта, производитель этого софта мог подойти и с уверенностью показать пальцем: «Бери вот это и все будет хорошо».
Такую программу для своего SQL Server разработал Microsoft — SQL Server Fast Track (DWFT). По ней сертифицируются конфигурации хранилищ данных — те, которые соответствуют требованиям рабочей нагрузки и могут быть внедрены с меньшим риском, стоимостью и сложностью. Звучит прекрасно, но интересно все-таки оценить эти критерии на практике. Для этого мы подробно разберем одну из конфигураций, имеющих сертификацию SQL Server Data Warehouse Fast Track.

Такую программу для своего SQL Server разработал Microsoft — SQL Server Fast Track (DWFT). По ней сертифицируются конфигурации хранилищ данных — те, которые соответствуют требованиям рабочей нагрузки и могут быть внедрены с меньшим риском, стоимостью и сложностью. Звучит прекрасно, но интересно все-таки оценить эти критерии на практике. Для этого мы подробно разберем одну из конфигураций, имеющих сертификацию SQL Server Data Warehouse Fast Track.
Производительность торговой платформы на простом примере
7 мин
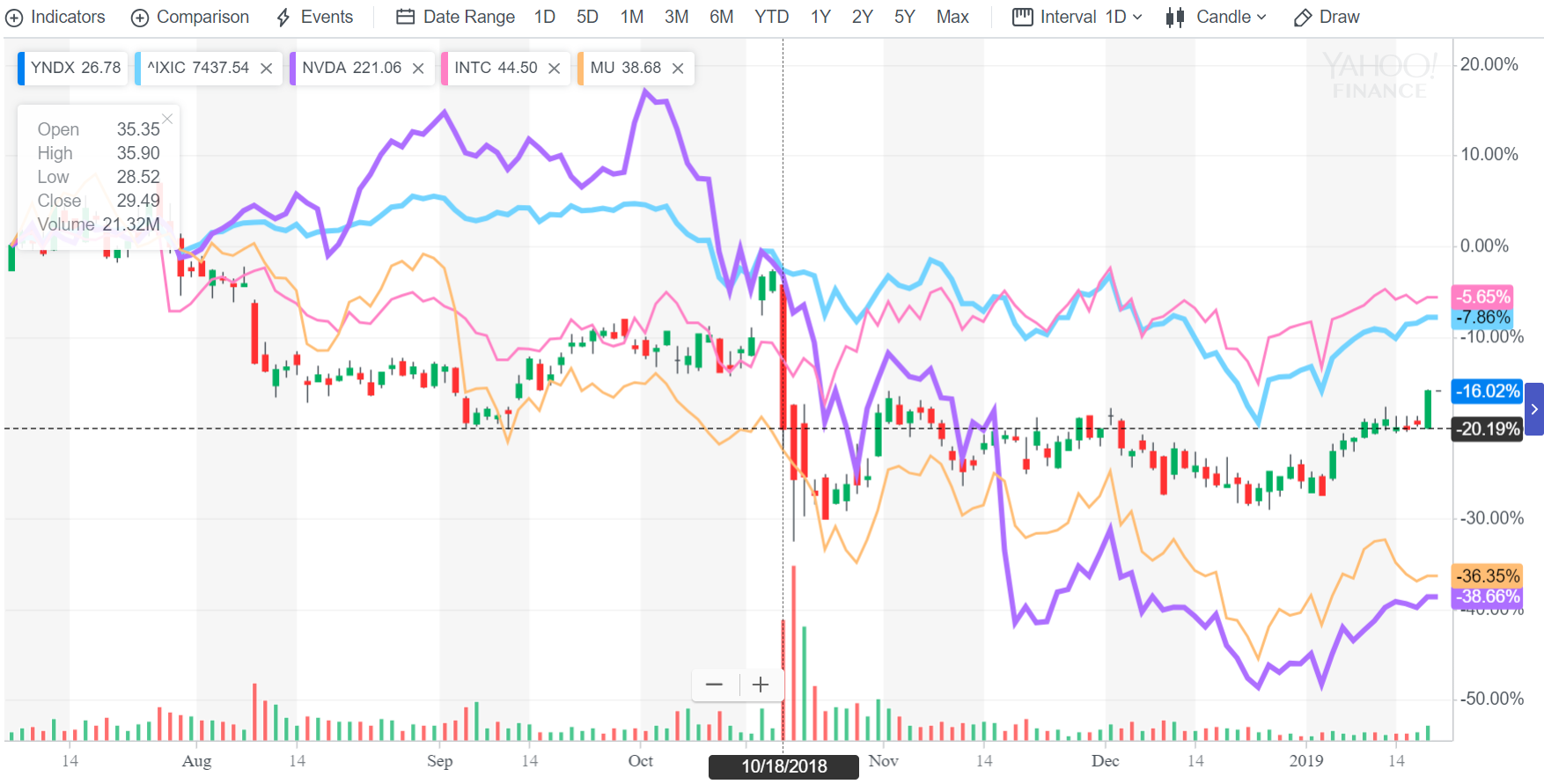
В этой статье я хочу в научно-популярной форме рассказать об оптимизации времени отклика в торговых платформах бирж и банков (HFT). Для справки речь идет о временах от сотен наносекунд до сотен микросекунд. Для большинства других приложений многие приведенные ниже методы оптимизации неактуальны просто в силу отсутствия столь жестких требований.
Обычно мы рассматриваем производительность в единицах пропускной способности. Например в Гигафлопах. Задача оптимизации в таких случаях сводится к выполнению максимального количества вычислений за единицу времени или решение задачи за минимальное время. Дизайн процессора рассчитан в первую очередь на достижение максимального количества вычислений за единицу времени и стандартные техники оптимизации на то же самое.
Однако существуют приложения где важнее время отклика, например торговые платформы в компьютерном трейдинге (HFT), поисковики, робототехника и телеком. Время отклика – это время выполнения «единичной» операции данного типа, например от получения пакета с текущими котировками с биржи до посылки заказа на биржевую операцию. На самом деле время отклика и пропускная способность (количество операций данного типа в единицу времени) тесно связаны, но разница – принципиальна. Увеличить пропускную способность часто можно просто добавив железа (больше серверов), но улучшить время отклика подобным образом проблематично (кроме случаев пиковых нагрузок).
Управление мощностями: в поисках идеального баланса
9 мин
Здравствуйте! Меня зовут Иван Давыдов, я занимаюсь исследованиями производительности в Яндекс.Деньгах.
Представьте, что у вас есть мощные сервера, на каждом из которых размещается ряд приложений. Если последних не очень много, они не мешают друг другу работать — им комфортно и уютно. Однажды вы приходите к микросервисам и выносите часть «тяжелой» функциональности в отдельные приложения.
Здесь можно увлечься, и микросервисов станет слишком много, вследствие чего станет сложно управлять ими и обеспечивать их отказоустойчивость. В итоге на каждом сервере станет «кучковаться» десяток приложений, которые борются за общие ресурсы. Получится «большая семья», а в большой семье клювом не щёлкай!
Однажды мы тоже с этим столкнулись. Моя история будет о тяжелых и бессонных ночах, когда я сидел под лампой в ночи и обстреливал прод. Всё началось с того, что мы стали замечать на боевых серверах проблемы, связанные с сетью.
Выбор режима работы web-сервера на личном опыте
6 мин
Эта статья будет полезна тем людям, у которых уже есть свой сайт, или которые планируют его открыть. Особенно интересна статья будет амбициозно настроенным вебмастерам, которые чувствуют, что звездный час их проекта не за горами и хотят подготовиться к наплыву посетителей страницы.
Даже те, кто пока только мечтают о тысячах пользователей на своём сайте, наверняка задавались вопросом: “А сколько же пользователей мой сайт выдержит, если они зайдут одновременно?” Сразу вспоминается известное выражение “Хабраэффект” – явление отказа сайта, который оказался не готов к многочисленным переходам на него после появления в интернете ссылки.
Даже те, кто пока только мечтают о тысячах пользователей на своём сайте, наверняка задавались вопросом: “А сколько же пользователей мой сайт выдержит, если они зайдут одновременно?” Сразу вспоминается известное выражение “Хабраэффект” – явление отказа сайта, который оказался не готов к многочисленным переходам на него после появления в интернете ссылки.
Оптимизация реляционных баз данных без даунтайма на примере самой нагруженной БД в Badoo
9 мин
В условиях highload сложность оптимизации реляционных баз данных возрастает на порядок, так как покупка ещё более мощного железа обходится дорого а также уже нет возможности просто выключить приложение ночью для долгого процесса альтера БД и миграции данных.
Недавно мы рассказали, как мы оптимизировали PHP-код нашего приложения. Теперь же пришёл черёд статьи про то, как мы полностью изменили внутреннюю структуру самой нагруженной и важной базы данных в Badoo, не потеряв при этом ни одного запроса.
Как «склеить» Intel-based сервер и преодолеть scale-up потолок в 8 процессоров
3 мин
Если вы занимаетесь выращиванием больших баз данных и вдруг упираетесь в потолок производительности — пришло время расширяться. Со scale-out расширением понятно: серверы добавляете и горя не знаете. Со scale-up все не так весело. Согласно стандартной glueless-архитектуре, мы берем два процессора, потом добавляем к ним еще два… так доходим до восьми и все. Больше Intel не предусмотрел, копите на новый сервер.

Но есть и альтернатива — glued-архитектура. В ней двухпроцессорные вычислительные блоки соединяются между собой через нод-контроллеры. С их помощью верхний порог на один сервер поднимается до 16 и более процессоров. В этом посте подробней расскажем о glued-архитектуре вообще и о том, как она реализована в наших серверах.
Но есть и альтернатива — glued-архитектура. В ней двухпроцессорные вычислительные блоки соединяются между собой через нод-контроллеры. С их помощью верхний порог на один сервер поднимается до 16 и более процессоров. В этом посте подробней расскажем о glued-архитектуре вообще и о том, как она реализована в наших серверах.
История о том, что не надо делать во время разработки
6 мин
Recovery Mode
Пролог: Для начала я расскажу о проекте, чтобы были представления о том как мы работали над проектом и для воссоздания той боли, которую мы чувствовали.
Я как разработчик вступил в проект в 2015-2016 точно не помню, но он работал 2-3 года ранее. Проект был очень популярен в своей сфере, а именно игровых серверов. Как странно не звучало, но проекты по игровым серверам ведутся и по сей день, недавно вакансии видел и чуток поработал в одной команде. Поскольку игровые сервера строятся на уже созданной игре, следовательно для разработки используется скриптовый язык который встроен в движок игры.
Мы разрабатываем почти с нуля проект на Garry’s Mod (Gmod), важно подметить, что на момент написания статьи Гарри создает уже новый проект S&Box на движке Unreal Engine. Мы же до сих пор сидим на Source.

Я как разработчик вступил в проект в 2015-2016 точно не помню, но он работал 2-3 года ранее. Проект был очень популярен в своей сфере, а именно игровых серверов. Как странно не звучало, но проекты по игровым серверам ведутся и по сей день, недавно вакансии видел и чуток поработал в одной команде. Поскольку игровые сервера строятся на уже созданной игре, следовательно для разработки используется скриптовый язык который встроен в движок игры.
Мы разрабатываем почти с нуля проект на Garry’s Mod (Gmod), важно подметить, что на момент написания статьи Гарри создает уже новый проект S&Box на движке Unreal Engine. Мы же до сих пор сидим на Source.
Который вообще не подходит для нашей тематики сервера.
Между небом и землей
8 мин
Эта история — об одном из проектов внедрения ИТ-решений, а именно — о развертывании системы виртуальных рабочих мест сотрудников компании «Гражданские самолеты «Сухого». И выбрали мы ее не случайно! Ведь от современной ИТ-инфраструктуры сегодня зависит успешная работа многих предприятий и организаций, особенно таких высокотехнологичных, как предприятия авиапрома.
Для сотрудников данной компании системный интегратор IBS Platformix развернул инфраструктуру виртуальных рабочих мест (Virtual Desktop Infrastructure, VDI). Ее основой стало стало аппаратное обеспечение от нескольких производителей, в том числе серверы и тонкие клиенты Lenovo.

Настройка HTTP/2 на примере Apache 2.4, PHP 7 и Ubuntu 18.04 LTS
3 мин
Я понимаю, что, возможно, Апач на данный момент не является предпочтительным выбором для запуска на нём новых проектов, то тем не менее, он существует, здравствует и проекты на нём таки работают. Выбор на него может пасть по каким-то личным предпочтениям, по требованиям совместимости, или каким-то другим соображениям… не суть. В этой статье я хочу по пунктам описать, как настроить поддержку протокола HTTP/2 на веб-сервере Apache, потому что сам им пользуюсь и в такой статье нуждаюсь нуждался, и надеюсь, что кому-нибудь она тоже пригодится на практике.
Ближайшие события
Оптимальное расположение шардов в петабайтном кластере Elasticsearch: линейное программирование
8 мин
Перевод
 В самом сердце информационно-поисковых систем Meltwater и Fairhair.ai работает набор кластеров Elasticsearch с миллиардами статей из СМИ и социальных медиа.
В самом сердце информационно-поисковых систем Meltwater и Fairhair.ai работает набор кластеров Elasticsearch с миллиардами статей из СМИ и социальных медиа.Индексные шарды в кластерах сильно отличаются по структуре доступа, рабочей нагрузке и размеру, что поднимает некоторые очень интересные проблемы.
В этой статье мы расскажем, как применили линейное программирование (линейную оптимизацию) для максимально равномерного распределения рабочей нагрузки поиска и индексирования по всем узлам в кластерах. Это решение уменьшает вероятность, что один узел станет узким местом в системе. В результате мы увеличили скорость поиска и сэкономили на инфраструктуре.
Google PageSpeed Insights кардинально обновился, что изменится?
5 мин

12 ноября Google по тихому обновил PageSpeed Insights, изменив в нем практически все. Это станет большой переменой для всей индустрии сайтостроения. Похоже, сейчас настанет некоторая волна паники и хайпа вокруг этого события. В статье — анализ перемен и что они нам принесут.
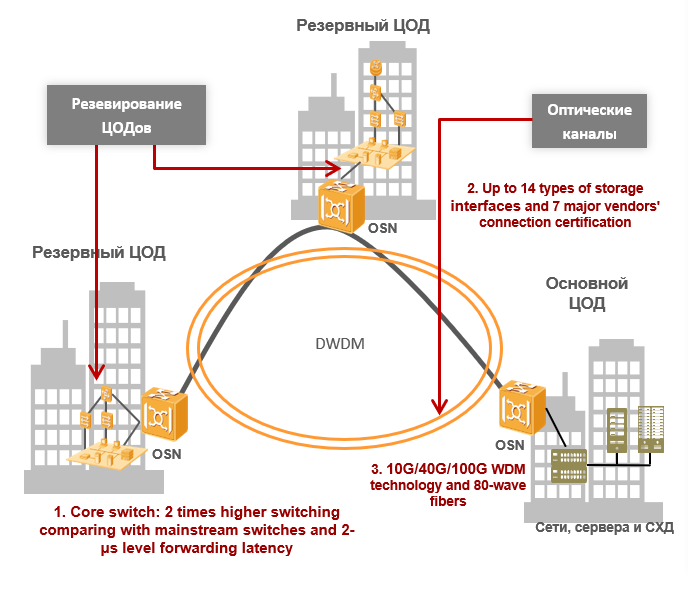
Технологии WDM: объединяем дата-центры в катастрофоустойчивые кластеры
8 мин
Несмотря на надежность современных центров обработки данных, для критически важных объектов необходим еще один уровень резервирования, ведь вся IT-инфраструктура может выйти из строя из-за техногенной или природной катастрофы. Для обеспечения катастрофоустойчивости приходится строить резервные ЦОДы. Под катом наш рассказ о возникающих при их объединении (DCI — Data Center Interconnection) проблемах.
Балансировка HTTP(S) трафика
12 мин
 Добрый день, %username%. Меня зовут Антон Резников, я работаю над проектом Облако Mail.Ru Сегодня я хочу рассказать о технологиях балансировки трафика, проиллюстрировав историей о развитии социальной сети. Все персонажи выдуманы, а совпадения почти случайны. Статья обзорная, составлена по следам доклада на Highload Junior 2017. Некоторые вещи могут показаться элементарными, но опыт проведения собеседований показывает, что это не совсем так. Кое-что будет спорным, не без этого.
Добрый день, %username%. Меня зовут Антон Резников, я работаю над проектом Облако Mail.Ru Сегодня я хочу рассказать о технологиях балансировки трафика, проиллюстрировав историей о развитии социальной сети. Все персонажи выдуманы, а совпадения почти случайны. Статья обзорная, составлена по следам доклада на Highload Junior 2017. Некоторые вещи могут показаться элементарными, но опыт проведения собеседований показывает, что это не совсем так. Кое-что будет спорным, не без этого.Если интересно, добро пожаловать под кат.
Как определить минимальный размер, необходимый для промежуточной папки репликации DFSR
7 мин
Туториал
Перевод

[Прим. переводчика. Материал статьи относится к Windows Server 2003/2003R2/2008/2008R2, но большинство из описанного справедливо и для более поздних версий ОС]
Уоррен снова здесь. Эта статья — краткое справочное руководство о том, как правильно вычислить минимальный размер промежуточной папки, необходимый для нормальной работы DFSR. Задание меньших значений может привести к замедлению репликации или вообще к ее остановке. Имейте в виду, что это лишь минимальные значения. Принимая решение о размере промежуточной папки, помните следующее: чем больше будет размер промежуточной папки, тем лучше, вплоть до размера самой реплицируемой папки. За дополнительными сведениями о том, как важно использовать верный размер промежуточной папки, обратитесь к разделу «Как определить, есть ли у вас проблема с промежуточной папкой» и постам из блогов, ссылки на которые размещены в конце этой статьи.
«Календарь тестировщика» за сентябрь. Оптимизируй тесты
7 мин
И снова в нашей ленте «Календарь тестировщика». В этом месяце Марина Третьякова, тестировщик проекта Контур.Поставки, расскажет об оптимизации тестов. Марина разберет конкретные проблемы и способы их решения, а также посоветует, как оптимизировать свои тесты и сократить время на тестирование.

Сложное решение простых проблем HighLoad WEB-сервисов
4 мин

Ключевой задачей высоконагруженных WEB-систем является способность обработать большое число запросов. Решить эту проблему можно по-разному. В этой статье я предлагаю рассмотреть необычный метод оптимизации запросов к backend через технологию content-range (range). А именно — сократить их количество без потери качества системы путем эффективного кеширования.