Любопытное наблюдение: когда говоришь о репликации Oracle, тебе сразу говорят «да знаем мы про этот GoldenGate!». Конечно, знаете, ведь это решение предлагает непосредственный вендор объекта репликации. При этом за кадром остаются не менее интересные решения. Вендор Quest нам говорит, что в России о
Shareplex больше известно в компаниях с иностранным участием, чем в исконно русских. Всё потому, что коллеги из за рубежа рассказали своим российским коллегам о том, что есть такой Shareplex и он очень даже хорош для репликации, а где-то даже превосходит решение от Oracle.
Начиная с Oracle 19c, RAC можно использовать только в версии Enterprise Edition (EE). Если вы решили обновиться до 19c, а у вас одна из предыдущих версий СУБД Oracle Standard Edition работает в режиме RAC, остается несколько вариантов:
- Переход с SE на EE;
- Переезд в облако;
- Конвертация Oracle RAC в Standalone;
- Использование SE с HA;
- Репликация.
Возможно, кто-то уже решил для себя эту дилемму. Интересно услышать о принятом вами решении в комментариях. С версии 19c в Oracle также пропадает поддержка Oracle Streams — еще одного инструмента для репликации.
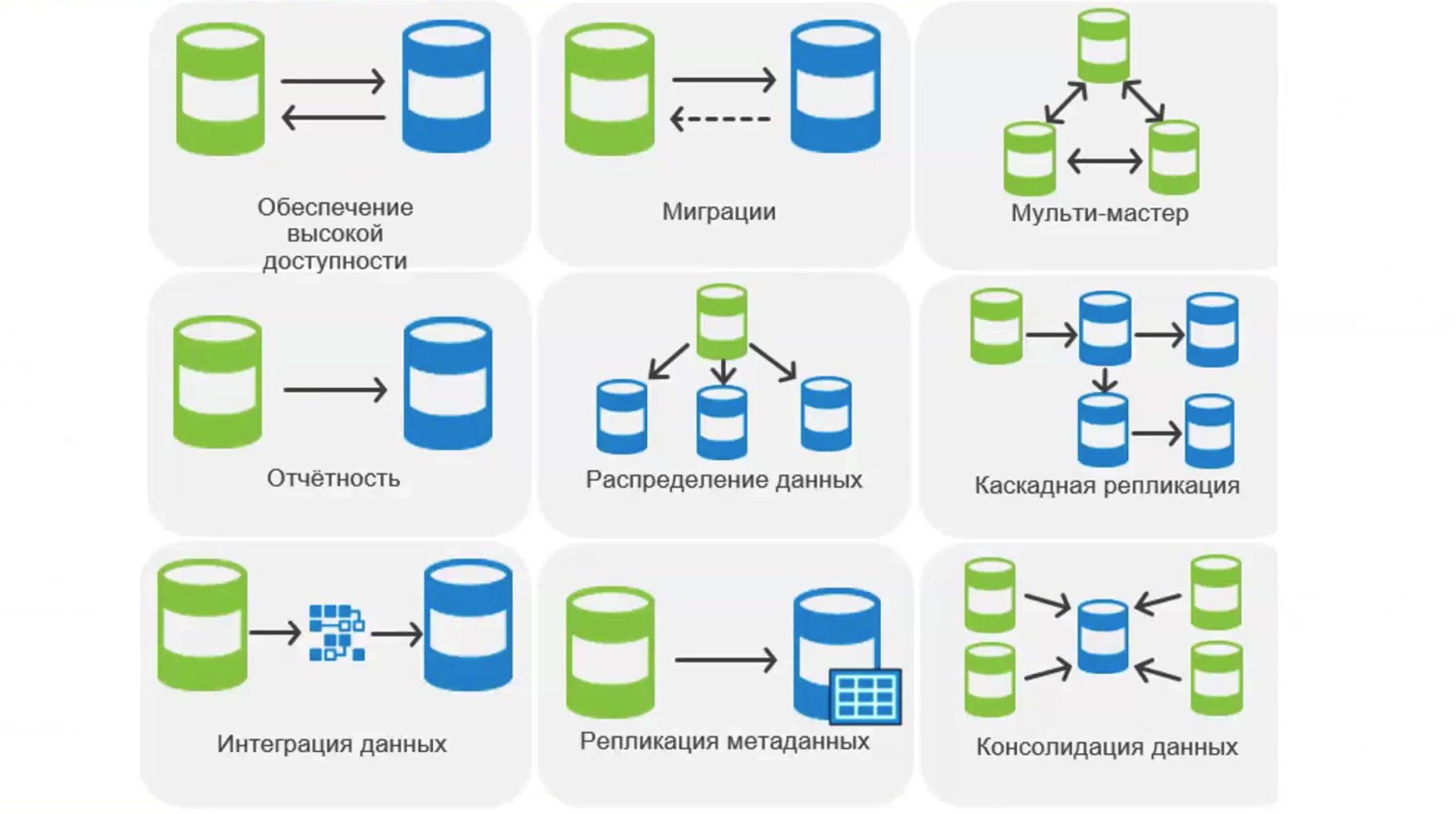
Другой кейс использования репликации — это т.н. ZeroImpact интеграция Oracle с внешними системами посредством чтения Redo/Archive логов. Например, в одном из банков был кейс репликации Oracle в Kafka для того, чтобы оперативно предлагать банковские продукты клиентам, оставившим свои данные на сайте.
Shareplex также поддерживает репликацию в PostgreSQL, что в итоге приводит к снижению стоимости владения СУБД. Кстати, это один из популярных кейсов использования инструмента для репликации.
В этой статье я познакомлю вас с возможностями Shareplex, расскажу о его преимуществах и предложу пилотный проект. Погнали!