Уровни изоляции транзакций с примерами на PostgreSQL
Вступление
В стандарте SQL описывается четыре уровня изоляции транзакций — Read uncommited (Чтение незафиксированных данных), Read committed (Чтение зафиксированных данных), Repeatable read (Повторяемое чтение) и Serializable (Сериализуемость). В данной статье будет рассмотрен жизненный цикл четырёх параллельно выполняющихся транзакций с уровнями изоляции Read committed и Serializable.
Для уровня изоляции Read committed допустимы следующие особые условия чтения данных:
Неповторяемое чтение — транзакция повторно читает те же данные, что и раньше, и обнаруживает, что они были изменены другой транзакцией (которая завершилась после первого чтения).
Фантомное чтение — транзакция повторно выполняет запрос, возвращающий набор строк для некоторого условия, и обнаруживает, что набор строк, удовлетворяющих условию, изменился из-за транзакции, завершившейся за это время.
Что же касается Serializable, то данный уровень изоляции самый строгий, и не имеет феноменов чтения данных.
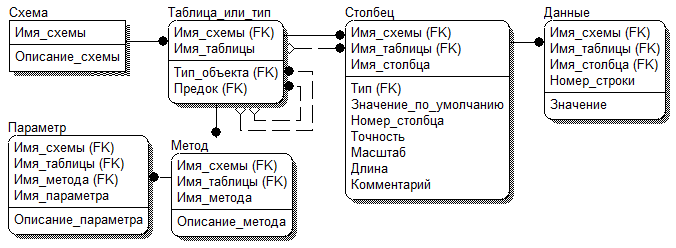
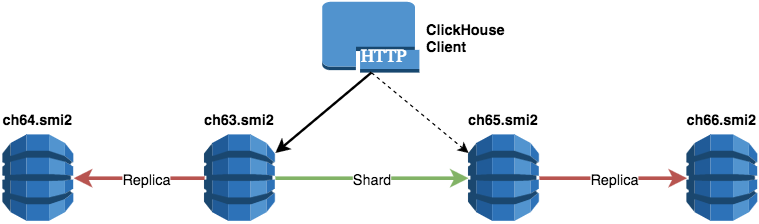

 Одним из ключевых нововведений СУБД Oracle версии 12.1.0.2 стала опция In-Memory. Основная её идея заключается в том, что для выбранных таблиц вы можете легко активировать dual-format режим, который объединяет стандартный для Oracle DB построчный формат хранения данных на диске и поколоночный формат в оперативной памяти.
Одним из ключевых нововведений СУБД Oracle версии 12.1.0.2 стала опция In-Memory. Основная её идея заключается в том, что для выбранных таблиц вы можете легко активировать dual-format режим, который объединяет стандартный для Oracle DB построчный формат хранения данных на диске и поколоночный формат в оперативной памяти.