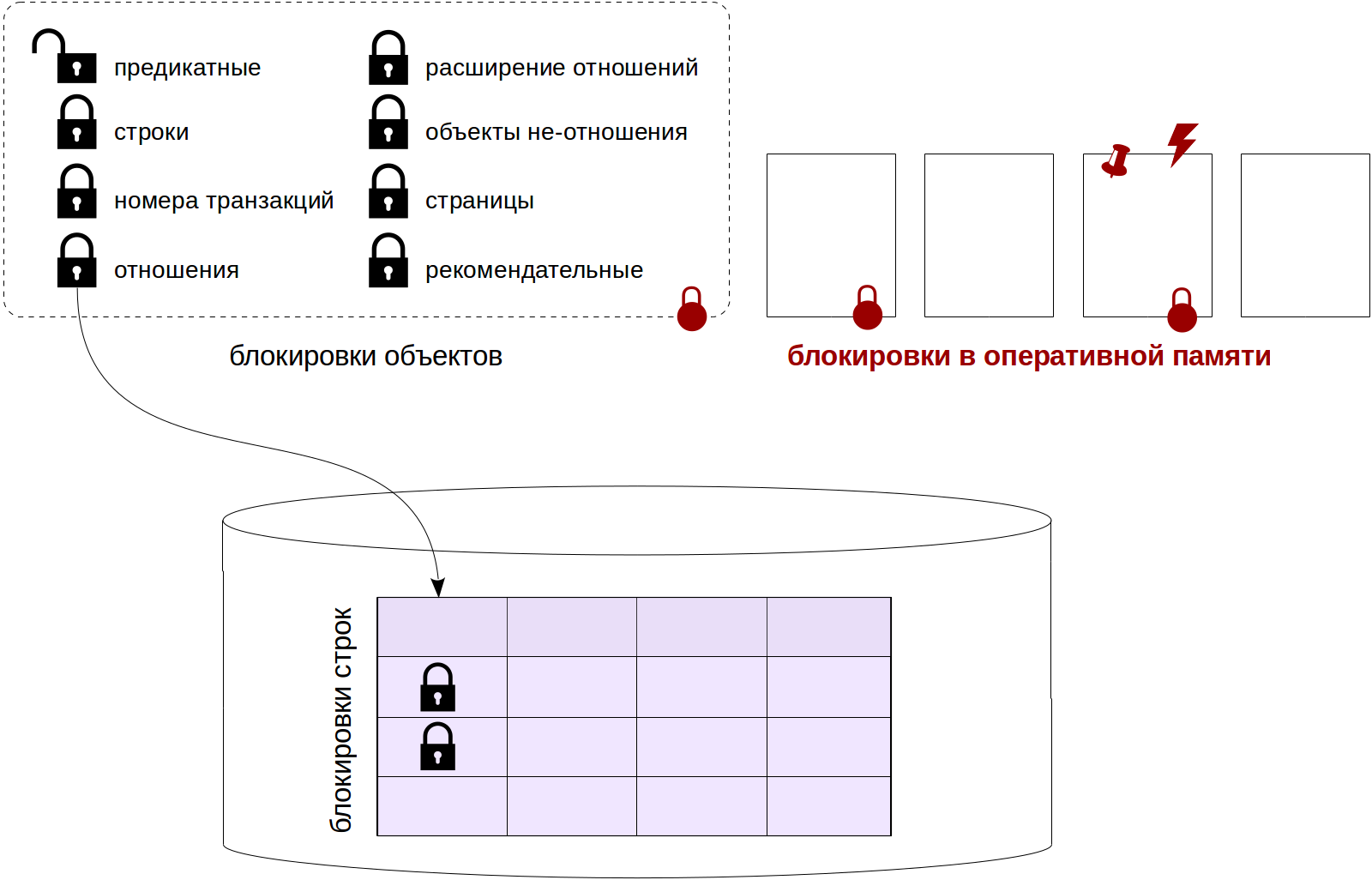
11 января 2024 года, выпущен Firebird 5.0 — восьмой основной выпуск СУБД Firebird, разработка которого началась в мае 2021 года. В Firebird 5.0 команда разработчиков сосредоточила свои усилия на повышении производительности СУБД: параллельное выполнение backup, restore, sweep, создания и перестроение индексов, улучшение масштабирования в многопользовательской среде, ускорение повторной подготовки запросов (кеш компилированных запросов), улучшение оптимизатора, улучшение алгоритма сжатия записей. Кроме того, появились и новые возможности в языке SQL и PSQL.
В версии Firebird 5 также появился встроенный инструмент для профилирования SQL и PSQL, что существенно облегчит поиск узких мест и отладку сложных SQL.
Базы данных, созданные в Firebird 5.0, имеют версию ODS (On-Disk Structure) 13.1. Firebird 5.0 позволяет работать и с базами данных с ODS 13.0 (созданные в Firebird 4.0), но при этом некоторые возможности будут недоступны.
Для того чтобы переход на Firebird 5.0 был проще, в утилиту командной строки gfix был добавлен новый переключатель -upgrade, который позволяет обновлять минорную версию ODS без длительных операций backup и restore.
Также хочется отметить тот факт, что новый релиз Firebird доступен сразу на 11 платформах, включая ARM для Linux и Android. Скачать готовые сборки и дистрибутивы можно по адресу https://firebirdsql.org/en/firebird-5-0/.
Далее я перечислю ключевые улучшения, сделанные в Firebird 5.0, и их краткое описание. Подробное описание всех изменений можно прочитать в Firebird 5.0 Release Notes. Кроме того подробный разбор новых функций Firebird 5.0 вы можете найти в серии статей на ресурсе ibase.ru.