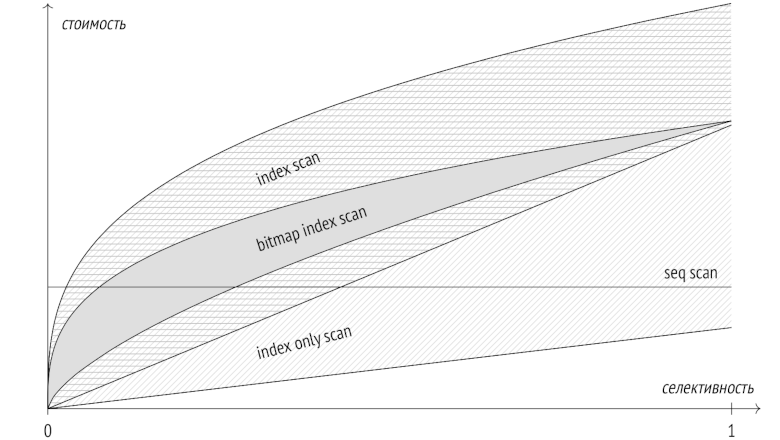
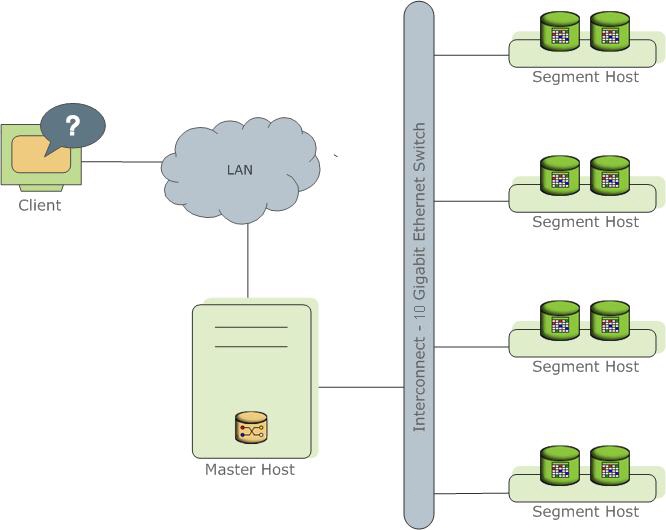
Всем привет! Искусственный интеллект уже научился писать простые запросы к базам данных, но можно ли совсем избавиться от кода в работе аналитиков? Мы расскажем про наши нейросетевые эксперименты, в которых мы научили BI-систему слушать, понимать и отрабатывать запросы аналитиков на естественном языке.
В команде R&D SberData мы ищем и разрабатываем технологии обработки, хранения и анализа данных Сбера. Мы исследуем все перспективные технологии, которые появляются на рынке, разрабатываем новые продукты, которые использует Сбер и его партнёры. Одно из приоритетных направлений для нас — это анализ данных. В Сбере более 100 тысяч пользователей BI (Business Intelligence). Естественно, что у такого количества аналитиков самые разные потребности и требования к сервису и продукту. И возможность сделать их работу проще и удобнее — это большой вызов и интересная задача для нашей команды. В этот раз мы пробовали научить LLM-модель написать правильный SQL-код по запросу на естественном языке.