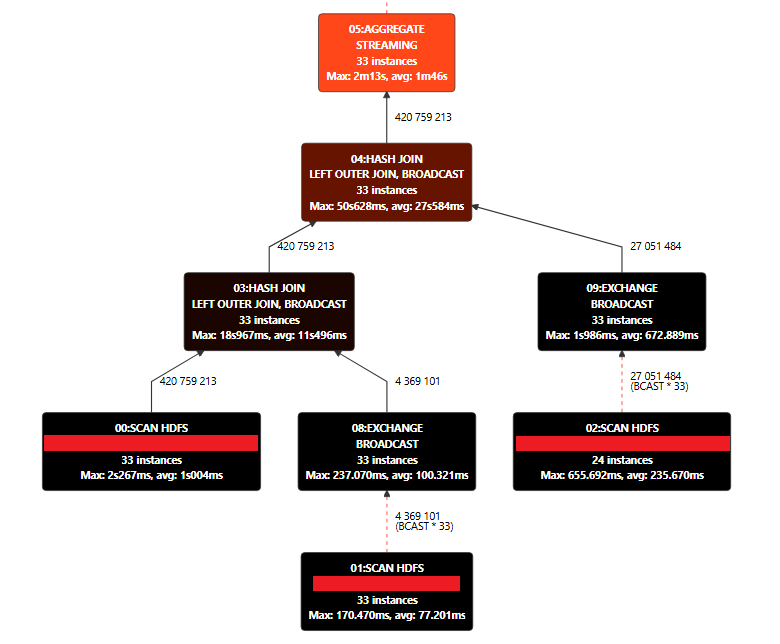
Что делать с запросами к СУБД, выполнение которых затягивается на десятки минут, как можно оптимизировать вложенные операторы, чтобы получить нужные данные за секунды? За счет чего подобные операции выполняются в Visiology автоматически? Ответы на эти вопросы мы попробуем дать сегодня на примере небольшого синтетического теста со сложным SQL-запросом, и разберемся при чем тут комбинаторы в ClickHouse. Эта статья будет полезна тем, кто интересуется SQL-оптимизаторами, а также всем существующим и будущим пользователям Visiology, кто хочет заглянуть под капот системы. Если вы из их числа, добро пожаловать под кат :)