
Интегральная статистика: любой маркетолог и продакт отдаст за это душу
4 мин
Мнение
Recovery Mode

Как сделать глубокую статистику, которая позволит выявить определенные шаблоны в восприятии и поведении людей?
Как сделать глубокую статистику, которая позволит выявить определенные шаблоны в восприятии и поведении людей?

Хайп? Философия? Повседневность? Будущее?
Давайте разбираться.
TL;DR:
Онтология в IT - это способ структурировать знания о мире в виде связанных категорий и их свойств.
Например, в онтологии "Игры престолов" есть категории "дома", "персонажи" и связи между ними. Когда мы наполняем онтологию реальными данными, получается граф знаний.
Семантический слой - это более абстрактное понятие, включающее все способы придания смысла данным.
Вместе они помогают ИИ-системам лучше понимать контекст и давать более точные ответы.
Динамические онтологии используются для выявления скрытых связей в больших объемах данных, что помогает принимать более обоснованные бизнес-решения.
В задаче на триангуляцию используются в основном углы и расстояния для определения позиции точек в пространстве. Но при этом в общей математике положения понятие угла вторично, по сравнению с понятием расстояния. Ярким примером является метрическое пространство с понятием метрики. При этом параметр длины хорошо реализована в физике, в том числе в физике сферических волн.

Демо выразительной мощи математики. Эта наука предлагает экстремально компактный способ для представления мыслей. И картинка это подтверждает: всего в двух абзацах определена вся суть аристотелевской логики (силлогистики, Ὄργανον), которая в оригинале занимает несколько книг.Формальная логика развилась к эпохе ЭВМ настолько, что стала основой одних из первых систем ИИ, в первую очередь экспертных систем и баз знаний.

Это небольшая статья, но, чтобы её написать, нужно было очень много проделать. Тут кратко описано про язык, про сбор нами данных и про обучение моделей. Это скорее не инструкция, как делать, а способ заявить о проделанном.
Про народ и язык
Раз в названии написано «переводчик», значит речь идёт о языке. На нём говорят карачаево‑балкарцы (официально народ искусственно разделён на «карачаевцев» и «балкарцев») — кавказцы, проживающие к северу, востоку и западу от горы Эльбрус в основном в Республиках Карачаево‑Черкессия и Кабардино‑Балкария.

Привет, я Вячеслав — руководитель отдела маркетинга ispmanager. Мы создаем сложный программный продукт, для которого нужна документация. Использовали Confluence, но решили поменять ПО — еще до того, как Atlassian ушел из РФ.
Рассказываю, почему решили мигрировать c Confluence, какие альтернативы тестировали, как запустили свой аналог и не скатились в «продуктовую пропасть». А еще расскажу, что пошло не по плану и почему мы отказались вкладывать в развитие продукта 10 миллионов рублей.

Введение
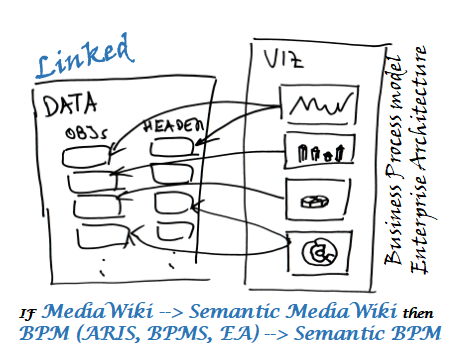
Представление моделей бизнес‑процессов на основе онтологий (онтологическое моделирование) эквивалентно Semantic BPM. Введение в семантический BPM (Business Process Management) см. «Semantic BPM. Семантика и синтаксис бизнес‑процессов» [semBPM24]. Если кратко, то можно провести аналогию: если классическая BPM система (BPMS: ARIS, бизнес‑студия, fox‑manager и т. п.) — это технологический аналог mediawiki (wikipedia), то Semantic BPM — это технологический аналог semantic mediaWiki (Wikidata), т. е.
IF MediaWiki → Semantic MediaWiki then BPM (ARIS, BPMS, EA) → Semantic BPM
Основной замысел (цель) семантического представления процессов (BPM, EA) не классическими BPM‑системами, а семантическими (Linked Data) — такой же, как и у семантических wiki
Одно из ключевых дополнений к wiki‑гиперссылки (html) это указание не просто что «ОбъектА связан с ОбъектомБ» (т. е. просто «связано») и соответствующий кликабельный переход (wiki‑ссылки, markdown syntax), а указание, что «ОбъектА связан с ОбъектомБ» такими‑то типом отношения (впрочем, как и задание других свойств объекта через отношения).
Изначально все BPMS (изначально называемые CASE‑средствами) — семантические, т.к. их суть — это отношения между объектами, только в них семантика глубоко спрятана «под капотом» BPMS и нестандартная (собственная, проприетарная). Semantic BPM «поднимает» семантическую составляющую на поверхность (возможность работы с семантическим слоем) и использует стандартные сематические технологии Linked Data.
В основе RDF (Resource Description Framework) — триплеты «субъект — отношение — объект» лежит ERD: Entity Relationship (ER) diagram. RDF \ ERD — это способ формализации знаний на основе атома знания — триплета. Вообще ER, subject, predicate, типы рассуждений и другие базовые элементы для работы со знаниями в СССР содержались в школьных учебниках [Логика54].

Префиксы помогают разработчикам быстро понять предназначение переменных и функций, что особенно полезно в больших проектах или когда код должен быть понятен новым участникам команды

С.Б. Пшеничников
В статье изложен новый математический аппарат вербальных вычислений в NLP (обработке естественного языка). Слова погружаются не в действительное векторное пространство, а в алгебру предельно разреженных матричных единиц. Вычисления становятся доказательными и прозрачными. На примере показаны развилки в вычислениях, которые остаются незамеченными при использовании традиционных подходов, а результат при этом может быть неожиданным.
Использование IT в обработке естественного языка (Natural Language Processing, NLP) требует стандартизации текстов, например, токенизации или лемматизации. После этого можно пробовать применять математику, поскольку она является высшей формой стандартизации и превращает исследуемые объекты в идеальные, например, таблицы данных в матрицы элементов. Только на языке матриц можно искать общие закономерности данных (чисел и текстов).
Если текст превращается в числа, то в NLP это сначала натуральные числа для нумерации слов, которые затем погружаются в действительное векторное пространство.
Возможно, следует не торопиться это делать, а придумать новый вид чисел более пригодный для NLP, чем числа для исследования физических явлений. Такими являются матричные гипербинарные числа. Гипербинарные числа - один из видов гиперкомплексных чисел.
Для гипербинарных чисел существует своя арифметика и если к ней привыкнуть, то она покажется привычнее и проще пифагорейской арифметики.
В системах поддержки принятия решений (DSS) текстами являются оценочные суждения и пронумерованная шкала вербальных оценок. Далее (как и в NLP) номера превращаются в векторы действительных чисел и используются как наборы коэффициентов средних арифметических взвешенных.
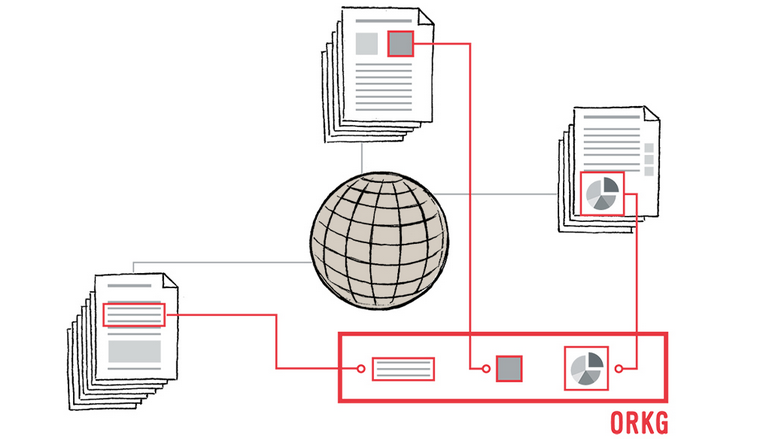
На сегодняшний день для представления и обмена результатами исследований мы используем методы, которые были разработаны много веков назад. С момента зарождения современной науки (публикации первого научного журнала "Transactions of the Royal Philosophical Society", 1665 г.) мы используем все тот же метод передачи научных знаний – статьи. Немецкая национальная научно-техническая библиотека TIB и исследовательский центр L3S при Университете Лейбница в Ганновере изобретают новый подход к научной коммуникации. Вместо того чтобы представлять исследования в виде статичных PDF файлов, они работают над динамическим графом знаний - Open Research Knowledge Graph, где научные идеи, подходы и методы представлены в структурированном машиночитаемом формате.
Онтологический инжиниринг в области Управления бизнес-процессами (BPM). Семантический BPM (Business Process Management), впрочем, как и семантический ЕА (Enterprise Architecture), – это заимствование концепций (подходов к описанию и онтологизации) \ инструментов Linked Data к указанным направлениям (формализация процессов и архитектур предприятий).
«Красная нить»: когда мы формализуем процессы - мы говорим об одном и том же, но на разных языках (нотациях), поэтому стандартизация Языка семантики, онтологических концептов BPM (EA) – важная, но еще недостаточно популяризированная составляющая развития BPM (следующий этап, ВРМ 3.0). Отделение («мух от котлет») семантики от синтаксиса позволит «рафинировать» понятийный (смысловой) анализ бизнес-процессов и при их аналитике оперировать базовыми (семантическими) концептами (образами).
В Semantic BPM, как и в Semantic Web (семантическая паутина), смысл представленного процесса \ архитектуры понятен не только человеку, но и машинам и они могут его читать и обрабатывать. Эти смыслы, обычно передаваемые «человек – человек» на языке синтаксиса / графической грамматики через нотации VAD, EPC, BPMN, UML (плюс еще несколько десятков подобных вариантов \ форматов «обертывания», включая Дракон), исходно формализуются на языке семантики (стек Linked Data или аналогичный) и уже потом упаковываются в схемы с конкретной нотацией («пишутся» на языке какой-либо нотации). Для единого понимания смысловой составляющей схем применяется общая ВРМ-онтология, толковый словарь ВРМ.

Пшеничников С.Б.
Знаковые последовательности (например, вербальные и нотные тексты) можно превратить в математические объекты. Слова и числа стали одной сущностью, представлением матричной единицы, которая является матричным обобщением целых чисел и гиперкомплексным числом. Матричная единица — это матрица в которой один элемент равен единице, а остальные — нули.
Если слова текста представить такими матрицами, то конкатенация (объединение с сохранением порядка) слов и текстов становится операцией сложения матриц.
С текстами можно совершать преобразования с помощью алгебраических операций, например делить с остатком один текст на другой. Математически распознавать смысл текста и вычислять контекст слов. При этом алгебра помогает интерпретировать все промежуточные этапы вычислений.
Человек видит и слышит только то, что понимает (И. В. Гёте). Понимает то, чему придает смысл как значимости для него. Смысл субъективен и зависит от интересов, мотиваций и чувств.
Л. С. Выготский различал понятия «смысл» и «значение»: «если „значение“ слова является объективным отражением системы связей и отношений, то „смысл“ — это привнесение субъективных аспектов значения соответственно данному моменту и ситуации».
По Г. Фреге «значения» — это свойства, отношения объектов, «смысл» — это только часть этих свойств. При этом и «значения» и «смысл» именуются одним «знаком», например словом. Два человека могут из списка значений выбрать для одного слова два непересекающихся фрагмента (два смысла) для его толкования.
В первой части говорили про использование поиска и генерации ответа с помощью языковых моделей. В этой части рассмотрим память и агентов.
Для этой задачи использую LLM (Large Language Models - например, chatGPT или opensouce модели) для внутренних задач (а-ля поиск или вопрос-ответную систему по необходимым данным).
Я пишу на языке R и также увлекаюсь NLP (надеюсь, я не один такой). Но есть сложности из-за того, что основной язык для LLM - это python. Соответственно, на R мало примеров и документации, поэтому приходится больше времени тратить, чтобы “переводить” с питона, но с другой стороны прокачиваюсь от этого.
Чтобы не городить свою инфраструктуру, есть уже готовые решения, чтобы быстро и удобно подключить и использовать. Это LangChain и LlamaIndex. Я обычно использую LangChain (дальше он и будет использоваться). Не могу сказать, что лучше, просто так повелось, что использую первое. Они написаны на питоне, но с помощью библиотеки reticulate всё работает и на R.
Казалось бы, простая задача - сверстать список пар ключ-значение. Бери <div> и делай. Но что, если захотелось подушнить? Этим и займёмся в статье...
Рассмотрим три подхода к решению этой задачи: <div>, <dl>, <dt>, и <dd>, и <table>. Обсудим преимущества, недостатки и примеры.
Цель - помочь выбрать наиболее подходящий подход для конкретной задачи.

В первой части было рассказано об алгебре множеств, рассматриваемой в качестве оснований классической логики и показано, как можно обосновать без аксиом законы алгебры множеств, которые полностью соответствуют законам классической логики.
В Части 2 будут показаны недостатки и некорректности силлогистики, а также рассмотрена новая, основанная на законах алгебры множеств, математическая модель полисиллогистики, в которую добавлены новые методы логического анализа, включающие распознавание ошибок в рассуждении и методы получения абдуктивных заключений.

Сразу начну с гипотезы, положенной в основу данной статьи: вся классическая логика основана на множествах, точнее, на алгебре множеств. Должен сказать, что в современной логике и математике эта гипотеза считается ошибочной, так как еще на рубеже XIX и XX столетий сложилось убеждение (точнее, заблуждение), что понятие «множество» противоречиво. Мне представляется, что настала пора избавляться от этого и некоторых других заблуждений, связанных с логикой.

Итак, Google всё‑таки решилась выпустить в свет языковую модель Gemini не дожидаясь Нового Года, и, конечно, обещая революцию. Она де превосходит все публично доступные модели, и местами превосходит людей. Отдельной её особенностью является мультимодальность (в частности способность работать с изображениями и видео) в почти реалтайм режиме, чему есть довольно впечатляющие демонстрации.
Давайте же сравним её с флагманом OpenAI/Microsoft — GPT-4, на трудном поле математики.

Я полгода собирался написать эту статью и одной из причин постоянного откладывания её написания было то, что я не знал как её начать. Поэтому, начну банально.
Привет, меня зовут Михаил Елисейкин, я более 20 лет в IT, более 20 лет изучаю историю техники, и сейчас хочу сказать, что эти два профессиональных сообщества объединяю не только я, но и общая распространённая проблема - игнорирование реальности.
Это и в самом деле именно так: имея данные о статистике производства, материалах на входе, продукции на выходе, бухгалтерской отчётности и т.д., и историк и айтишник делают одно и то же - создают модель предприятия как производственного процесса:
Все, кто когда-либо интересовались трёхзначной логикой, троичной системой счисления или архитектурой троичных компьютеров, рано или поздно натыкались на труды Брусенцова Николая Петровича, в особенности 3 его самые известные книги:
1) Брусенцов Н.П. Начала информатики, 1994.
2) Брусенцов Н.П. Искусство достоверного рассуждения. Неформальная реконструкция аристотелевой силогистики и булевой математики мысли, 1998.
3) Брусенцов Н.П. Блуждание в трёх соснах (Приключения диалектики в информатике), 2000.
Для тех, кто не в курсе, Брусенцов Николай Петрович - главный конструктор первой в мире и Советском Союзе троичной ЭВМ "Сетунь". Об этом хорошем человеке можно найти достаточно много информации в открытых источниках. Но сейчас речь не о нём, а о разработанной им алгебре совокупностей (алгебре дизъюнктов), которая фигурирует в качестве фундамента во всех 3-х упомянутых выше книгах. К слову сказать, сами книги не являются учебниками по чистой математике или информатике. Они освещают проблемы злоупотребления формализмом в современной математической логике, а также содержат пути к возрождению и развитию аристотелевой силогистики. Мотивацией к написанию данной статьи послужило то, что каждую книгу пришлось прочитать раза по три, прежде чем в голове сложилась более или менее цельная картина. Этому также поспособствовало обилие терминологии, более присущей философским трактатам, нежели учебникам по математике. Поэтому цель данной статьи - получить представление об этой алгебре и облегчить чтение вышеуказанных книг. Статья носит обзорный характер, знакомит читателя с некоторыми понятиями (акценты расставлены жирным шрифтом) и пытается ответить на вопросы, неосвещённые в книгах явно.