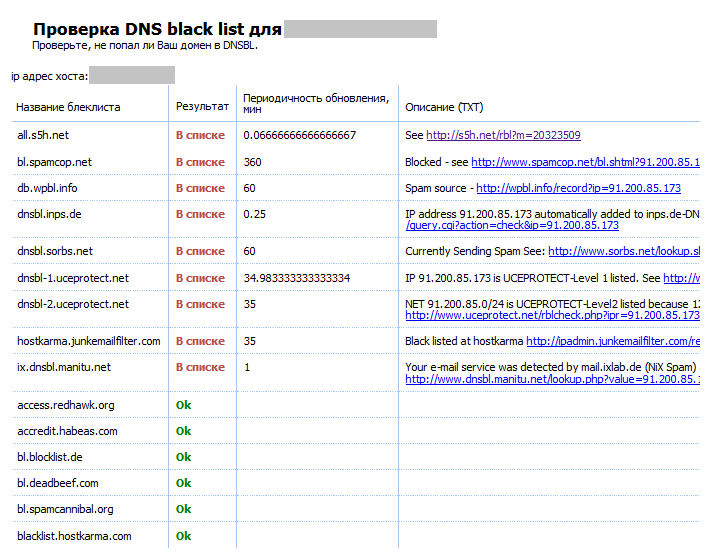
Меня недавно спросили, могу ли я поговорить с некоторыми из моих коллег о работе с багами. В частности, меня спросили, могу ли я объяснить, как выглядит хороший багрепорт и какую информацию он может содержать. Под прицелом оказалась команда Halaxy Service. Я восхищаюсь людьми, которые работают в службе поддержки, это работа может быть тяжелой, и когда у вас возникают трудные клиенты или ситуации, вы находитесь под изрядным давлением. Я работал на этой должности (в другой компании), временами это может быть очень сложно. При этом сотрудники Halaxy Service — нечто особенное. Их взаимопонимание с клиентами Halaxy превосходит все, что я когда-либо видел или слышал.
У меня было 10-15 минут на выступление. Не так много времени, чтобы по-настоящему вникнуть, тем более, что люди, с которыми я разговаривал, не были специалистами по тестированию. Моя цель состояла в том, чтобы передать некоторые ключевые моменты в понятных терминах, которые можно было бы извлечь и использовать. Я решил, что обсуждение разницы между сбоем (fault), ошибкой (error) и отказом (failure) не влезает в это обсуждение. Точно так же не было времени раскрывать эвристику как концепцию, но я кратко рассказал о важности согласованности. Чего мы хотели достигнуть так это того, чтобы люди из команды поддержки могли писать багрепорты достаточно детализированные, чтобы четко определить контекст и облегчить дальнейшее исследование и решение проблемы другим участникам разработки (включая всех членов команды, а не только разработчиков).
Я сформировал структуру на 3-х ключевых моментах при регистрации бага на основе взаимодействия с клиентами. Три простых вопроса, на которые следует полагаться при создании багрепортов. Что произошло? Как это произошло? Что должно было произойти? Давайте рассмотрим каждый из них по очереди.














 Мы с вами находимся в ситуации, когда на глобальных рынках представлены тысячи различных смартфонов под сотнями брендов.
Мы с вами находимся в ситуации, когда на глобальных рынках представлены тысячи различных смартфонов под сотнями брендов.  Задумывались ли вы о том насколько стабильна работа интернет-банкинга с которым вы работаете? Клиент-банк становится основным инструментом для работы с вашими финансами. Не важно, управляете вы деньгами огромной корпорации или работаете с личным счетом. Положить деньги на депозит, заплатить за комуслуги, закинуть деньги на карту, перевести пару миллионов партнеру на другом конце планеты — все это сейчас можно сделать не отходя от экрана.
Задумывались ли вы о том насколько стабильна работа интернет-банкинга с которым вы работаете? Клиент-банк становится основным инструментом для работы с вашими финансами. Не важно, управляете вы деньгами огромной корпорации или работаете с личным счетом. Положить деньги на депозит, заплатить за комуслуги, закинуть деньги на карту, перевести пару миллионов партнеру на другом конце планеты — все это сейчас можно сделать не отходя от экрана.