В поисках оптимального механизма синхронизации, я часто сталкивался с постами типа mutex vs…, но большой ясности в своей карте этих механизмов так и не получил. Поэтому решил написать небольшой тест, сравнивающий накладные расходы на разные типы блокирующих механизмов. Пожалуй, можно сказать, что тест измеряет латентность механизмов блокировки. Суть его в том, что некоторое количество нитей конкурируют за ресурс. Ресурс —
Цель теста — оценить затраты на синхронизацию, то бишь построить графики зависимость временных затрат от количества конкурирующих нитей для разных механизмов синхронизации.
Пучки нитей (1..N штук) выполняют одинаковое количество инкрементов, синхронизируясь разными способами.
Далее о структуре теста и результатах.
Исходники и результаты лежат на гитхабе. Можно скачать и запустить. Здесь их не привожу ибо громоздко. Ограничусь кратким описанием.
Итак, есть глобальная переменная incremented. Модификатор volatile используется для того, чтобы при компиляции с -O3 переменная не попадала в регистр.
Для последовательного варианта тест выглядит примерно так:
Факторила N!=1*2*...*M*...*(N-1)*N. Если имеем M нитей, то заведомо понятно что каждой достанется равное число инкрементов.
Активные блоки тестов (в скобках указаны ключевые слова появляющиеся в выдаче теста):
Для каждого активного блока создается по три функции. Init, thread, fini — название которых говорит за себя. Init выполняется до запуска пучка нитей, fini — после. Thread — выполняет свою долю инкрементов в каждой нити.
Всем нитям передается структура данных, содержащая количество запущенных нитей, значение «большого числа», собственный номер нити. Собственный номер нити используется для привязки нити к заданному процессору по формуле:
Привязка нити к процессору сделана для уверенности, что нити будут выполнятся на разных ядрах. Привязка реализована с помощью функции pthread_setaffinity_np.
Каждая нить выполняет свою долю инкрементов и завершается. Время выполнения измеряется в миллисекундах. Далее запускается следующий пучек нитей, либо следующий тест.
В качестве подопытного образца использовался настольный компьютер:
CPU model name: Intel® Core(TM)2 Duo CPU E8400 @ 3.00GHz
Thread libs: NPTL 2.13
2 of 2 cores online
Additition threads: 100
Big number: 11! = 0x2611500
И вот что он выдал(На картинках одно и тоже, но в разных масштабах):
Каждая точка здесь время затраченное на 11! инкрементов.


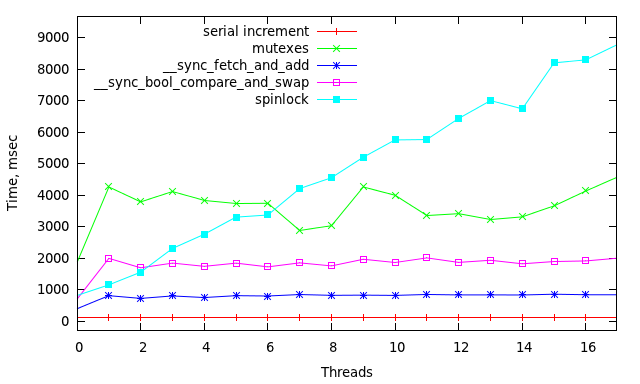
Не стану разводить философию о преимуществах отдельных механизмов, т.к. каждый нацелен на свои задачи. Однако, глядя на изображения легко оценить накладные расходы каждого из них.
В принципе, все более-менее предсказуемо. Единственная неожиданность в том, что иногда спинлок даже лучше чем CAS.
Очень интересно было бы посмотреть такие графики для машин с большим числом ядер. К сожалению, не могу получить данные по большому спектру архитектур. Поэтому призываю хабралюдей скачивать тест с гитхаба и коммитить результаты обратно или постить сюда.
Удач.
PS. Пользоваться тестом просто(-h справка):
Т.е. будет выполнено BIG_NUMBER=11! инкрементов для каждого механизма синхронизации в пучках нитей от 1 до (число_ядер + 50).
Если наберется достаточно материала, опубликую его здесь. Думаю, всем будет интересно. Спасибо.
«Полезная» работа — выполнить BIG_NUMBER инкрементов.volatile unsigned long int incremented;
Цель теста — оценить затраты на синхронизацию, то бишь построить графики зависимость временных затрат от количества конкурирующих нитей для разных механизмов синхронизации.
Пучки нитей (1..N штук) выполняют одинаковое количество инкрементов, синхронизируясь разными способами.
Далее о структуре теста и результатах.
PINC (Parallel INCrementor).
Исходники и результаты лежат на гитхабе. Можно скачать и запустить. Здесь их не привожу ибо громоздко. Ограничусь кратким описанием.
Итак, есть глобальная переменная incremented. Модификатор volatile используется для того, чтобы при компиляции с -O3 переменная не попадала в регистр.
Для последовательного варианта тест выглядит примерно так:
В случае параллельного выполнения BIG_NUMBER должен быть поровну разделён между всеми нитями, поэтому его удобно выбрать как факториал максимального числа нитей.for(long i = 0;i < BIG_NUMBER; i++) incremented++;
Факторила N!=1*2*...*M*...*(N-1)*N. Если имеем M нитей, то заведомо понятно что каждой достанется равное число инкрементов.
Активные блоки тестов (в скобках указаны ключевые слова появляющиеся в выдаче теста):
- Чистый последовательный инкремент выполняется только в одной нити(serial increment):
incremented++; - Атомарный инкремент(lock increment test)
Здесь допускаем, что эта функция разворачивается в то-то подобное «lock xaddl ..»__sync_fetch_and_add(&incremented,1);
- CAS инктемент (lock compare&swap test )
а эта в «lock cmpxchgl ..».do{ x = incremented; }while(!__sync_bool_compare_and_swap(&incremented,x , x + 1));
- Спинлок (spinlock test )
pthread_spin_lock(&spin); incremented++; pthread_spin_unlock(&spin);
- Мутекс (mutexed test)
pthread_mutex_lock(&mut); incremented++; pthread_mutex_unlock(&mut);
Структура теста
Для каждого активного блока создается по три функции. Init, thread, fini — название которых говорит за себя. Init выполняется до запуска пучка нитей, fini — после. Thread — выполняет свою долю инкрементов в каждой нити.
Всем нитям передается структура данных, содержащая количество запущенных нитей, значение «большого числа», собственный номер нити. Собственный номер нити используется для привязки нити к заданному процессору по формуле:
процессор = номер_нити % число_процессоровПривязка нити к процессору сделана для уверенности, что нити будут выполнятся на разных ядрах. Привязка реализована с помощью функции pthread_setaffinity_np.
Каждая нить выполняет свою долю инкрементов и завершается. Время выполнения измеряется в миллисекундах. Далее запускается следующий пучек нитей, либо следующий тест.
Результаты
В качестве подопытного образца использовался настольный компьютер:
CPU model name: Intel® Core(TM)2 Duo CPU E8400 @ 3.00GHz
Thread libs: NPTL 2.13
2 of 2 cores online
Additition threads: 100
Big number: 11! = 0x2611500
И вот что он выдал(На картинках одно и тоже, но в разных масштабах):
Каждая точка здесь время затраченное на 11! инкрементов.
Не стану разводить философию о преимуществах отдельных механизмов, т.к. каждый нацелен на свои задачи. Однако, глядя на изображения легко оценить накладные расходы каждого из них.
В принципе, все более-менее предсказуемо. Единственная неожиданность в том, что иногда спинлок даже лучше чем CAS.
Очень интересно было бы посмотреть такие графики для машин с большим числом ядер. К сожалению, не могу получить данные по большому спектру архитектур. Поэтому призываю хабралюдей скачивать тест с гитхаба и коммитить результаты обратно или постить сюда.
Удач.
PS. Пользоваться тестом просто(-h справка):
make;./pinc -f11 -t50 Т.е. будет выполнено BIG_NUMBER=11! инкрементов для каждого механизма синхронизации в пучках нитей от 1 до (число_ядер + 50).
Если наберется достаточно материала, опубликую его здесь. Думаю, всем будет интересно. Спасибо.

