
Вы правильно поняли из названия, что это не совсем обычное описание алгоритма JPEG (формат файла я подробно описывал в статье «Декодирование JPEG для чайников»). В первую очередь, выбранный способ подачи материала предполагает, что мы ничего не знаем не только о JPEG, но и о преобразовании Фурье, и кодировании Хаффмана. И вообще, мало что помним из лекций. Просто взяли картинку и стали думать как же ее можно сжать. Поэтому я попытался доступно выразить только суть, но при которой у читателя будет выработано достаточно глубокое и, главное, интуитивное понимание алгоритма. Формулы и математические выкладки — по самому минимуму, только те, которые важны для понимания происходящего.
Знание алгоритма JPEG очень полезно не только для сжатия изображений. В нем используется теория из цифровой обработки сигналов, математического анализа, линейной алгебры, теории информации, в частности, преобразование Фурье, кодирование без потерь и др. Поэтому полученные знания могут пригодиться где угодно.
Если есть желание, то предлагаю пройти те же этапы самостоятельно параллельно со статьей. Проверить, насколько приведенные рассуждения подходят для разных изображений, попытаться внести свои модификации в алгоритм. Это очень интересно. В качестве инструмента могу порекомендовать замечательную связку Python + NumPy + Matplotlib + PIL(Pillow). Почти вся моя работа (в т. ч. графики и анимация), была произведена с помощью них.
Внимание, трафик! Много иллюстраций, графиков и анимаций (~ 10Мб). По иронии судьбы, в статье про JPEG всего 2 изображения с этим форматом из полусотни.
Каков бы ни был алгоритм сжатия информации, его принцип всегда будет один — нахождение и описание закономерностей. Чем больше закономерностей, тем больше избыточности, тем меньше информации. Архиваторы и кодеры обычно «заточены» под конкретный тип информации, и знают где можно их найти. В некоторых случаях закономерность видна сразу, например картина голубого неба. Каждый ряд его цифрового представления можно довольно точно описать прямой.
Будем тренироваться на
Векторное представление
Для начала проверим насколько зависимы два соседних пикселя. Логично предположить, что скорее всего, они будут очень похожи. Проверим это для всех пар изображения. Отметим их на координатной плоскости точками так, что значение точки по оси X — значение первого пикселя, по оси Y — второго. Для нашего изображения размером 256 на 256 получим 256*256/2 точек:
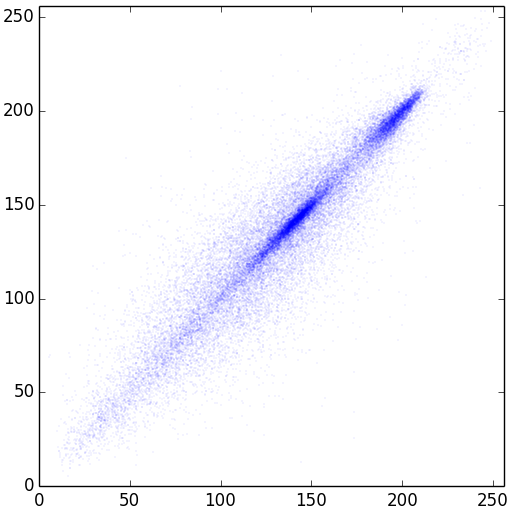
Предсказуемо, что большинство точек находится на или рядом с прямой y=x (а их там еще больше, чем видно на рисунке, так как они многократно накладываются друг на друга, и, к тому же, они полупрозрачные). А раз так, то было бы проще работать, повернув их на 45°. Для этого нужно выразить их в другой системе координат.
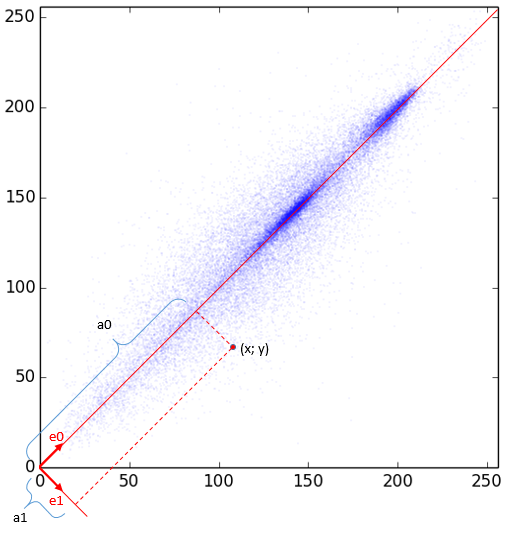
Базисные вектора новой системы, очевидно, такие:
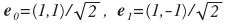 . Вынуждены делить на корень из двойки, чтобы получить ортонормированную систему (длины базисных векторов равны единичке). Здесь показано, что некоторая точка p = (x, y) в новой системе будет представлена как точка (a0, a1). Зная новые коэффициенты, мы легко можем получить старые обратным поворотом. Очевидно, первая (новая) координата является средним, а вторая — разностью x и y (но деленные на корень из 2). Представьте, что вам предложено оставить только одно из значений: либо a0, либо a1 (то есть другое приравнять нулю). Лучше выбрать a0, так как значение a1 и так, скорее всего, будет около нуля. Вот, что получится, если мы восстановим изображение только по a0:
. Вынуждены делить на корень из двойки, чтобы получить ортонормированную систему (длины базисных векторов равны единичке). Здесь показано, что некоторая точка p = (x, y) в новой системе будет представлена как точка (a0, a1). Зная новые коэффициенты, мы легко можем получить старые обратным поворотом. Очевидно, первая (новая) координата является средним, а вторая — разностью x и y (но деленные на корень из 2). Представьте, что вам предложено оставить только одно из значений: либо a0, либо a1 (то есть другое приравнять нулю). Лучше выбрать a0, так как значение a1 и так, скорее всего, будет около нуля. Вот, что получится, если мы восстановим изображение только по a0:
Увеличение в 4 раза:

Такое сжатие не очень впечатляет, честно говоря. Лучше аналогично разобьем картинку по тройкам пикселей и представим их в трехмерном пространстве.
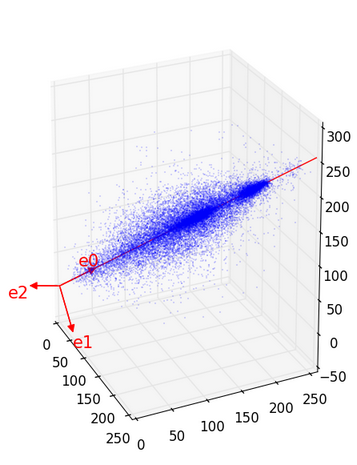
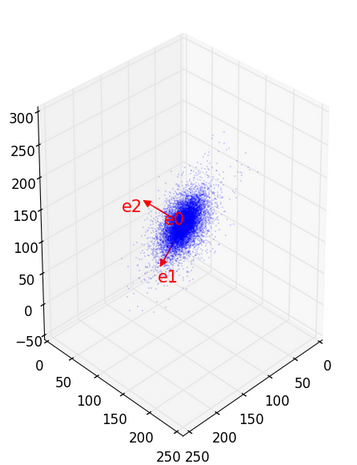
Это один и тот же график, но с разных точек зрения. Красные линии — оси, которые напрашивались сами собой. Им соответствуют вектора:
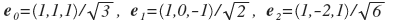 . Напоминаю, что приходится делить на некоторые константы, чтобы длины векторов стали равны единице. Таким образом, разложив по такому базису, мы получим 3 значения a0, a1, a2, причем a0 важнее a1, а a1 важнее a2. Если мы выбросим a2, то график «сплющится» в направлении вектора e2. Этот и так довольно не толстый трехмерный лист станет плоским. Он потеряет не так много, зато мы избавимся от трети значений. Сравним изображения, восстановленные по тройкам: (a0, 0, 0), (a1, a2, 0) и (a0, a1, a2). В последнем варианте мы ничего не выбросили, поэтому получим оригинал.
. Напоминаю, что приходится делить на некоторые константы, чтобы длины векторов стали равны единице. Таким образом, разложив по такому базису, мы получим 3 значения a0, a1, a2, причем a0 важнее a1, а a1 важнее a2. Если мы выбросим a2, то график «сплющится» в направлении вектора e2. Этот и так довольно не толстый трехмерный лист станет плоским. Он потеряет не так много, зато мы избавимся от трети значений. Сравним изображения, восстановленные по тройкам: (a0, 0, 0), (a1, a2, 0) и (a0, a1, a2). В последнем варианте мы ничего не выбросили, поэтому получим оригинал.
Увеличение в 4 раза:

Второй рисунок уже хорош. Резкие участки немного сгладились, но в целом картинка сохранилась очень неплохо. А теперь, точно так же поделим на четверки и визуально определим базис в четырехмерном пространстве… А, ну да. Но можно догадаться, каким будет один из векторов базиса, это: (1,1,1,1)/2. Поэтому можно посмотреть проекцию четырехмерного пространства на пространство, перпендикулярное вектору (1,1,1,1), чтобы выявить другие. Но это не лучший путь.
Наша цель — научиться преобразовывать (x0, x1, ..., xn-1) к (a0, a1, ..., an-1) так, что каждое значение ai все менее важно, чем предыдущие. Если мы сможем так делать, то, возможно, последние значения последовательности вообще можно будет выбросить. Вышеприведенные опыты намекают, что можно. Но без математического аппарата не обойтись.
Итак, нужно преобразовать точки к новому базису. Но сначала необходимо найти подходящий базис. Вернемся к первому эксперименту разбиения на пары. Будем считать обобщенно. Мы определили базисные векторы:
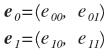
Выразили через них вектор p:
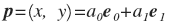
или в координатах:
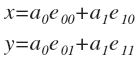
Чтобы найти a0 и a1 нужно спроецировать p на e0 и e1 соответственно. А для этого нужно найти скалярное произведение
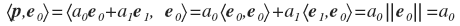
аналогично:
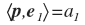
В координатах:
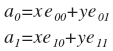
Часто бывает удобнее проводить преобразование в матричной форме.
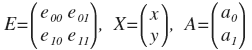
Тогда A = EX и X = ETA. Это красивая и удобная форма. Матрица E называется матрицей преобразования и является ортогональной, с ней мы еще встретимся.
Переход от векторов к функциям.
С векторами малых размерностей работать удобно. Однако мы хотим находить закономерности в бОльших блоках, поэтому вместо N-мерных векторов удобнее оперировать последовательностями, которыми представлено изображение. Такие последовательности я буду называть дискретными функциями, так как следующие рассуждения применимы и к непрерывным функциям.
Возвращаясь к нашему примеру, представим такую функцию f(i), которая определена всего в двух точках: f(0)=x и f(1)=y. Аналогично зададим базисные функции e0(i) и e1(i) на основе базисов e0 и e1. Получим:
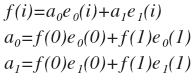
Это очень важный вывод. Теперь во фразе «разложение вектора по ортонормированным векторам» мы можем заменить слово «вектор» на «функция» и получить вполне корректное выражение «разложение функции по ортонормированным функциям». Не беда, что мы получили такую куцую функцию, так как такие же рассуждения работают и для N-мерного вектора, который можно представить как дискретную функцию с N значениями. А работа с функциями нагляднее, чем с N-мерными векторами. Можно и наоборот, представить такую функцию как вектор. Более того, обычную непрерывную функцию можно представить бесконечномерным вектором, правда уже не в евклидовом, а гильбертовом пространстве. Но мы туда не пойдем, нас будут интересовать только дискретные функции.
А наша задача нахождения базиса превращается в задачу нахождения подходящей системы ортонормированных функций. В следующих рассуждениях предполагается, что мы уже как-то определили набор базисных функций, по которым и будем раскладывать.
Допустим, у нас есть некоторая функция (представленная, например, значениями), которую мы хотим представить в виде суммы других. Можно представлять этот процесс в векторном виде. Для разложения функции нужно «спроецировать» ее на базисные функции по очереди. В векторном смысле вычисление проекции дает минимальное сближение исходного вектора к другому по расстоянию. Помня о том, что расстояние вычисляется с помощью теоремы Пифагора, то аналогичное представление в виде функций дает наилучшее среднеквадратичное приближение функции к другой. Таким образом, каждый коэффициент (k) определяет «близость» функции. Более формально, k*e(x) — лучшее среднеквадратичное приближение к f(x) среди l*e(x).
В следующем примере показан процесс приближения функции только по двум точкам. Справа — векторное представление.
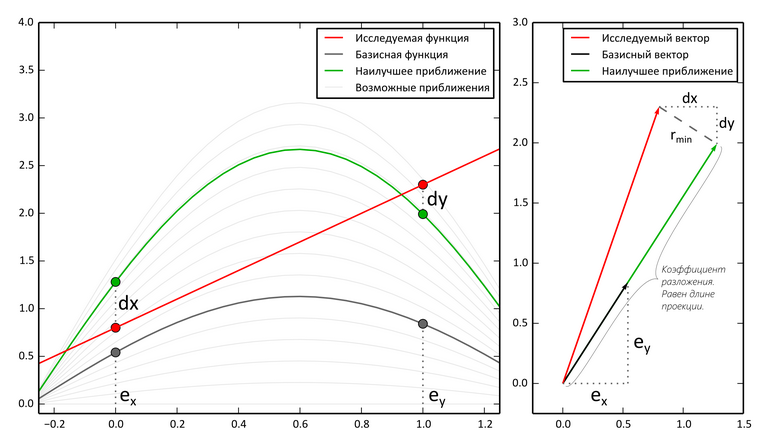
Применительно к нашему эксперименту разбивания на пары, можно сказать, что эти две точки (0 и 1 по абсцисс) — пара соседних пикселей (x, y).
То же самое, но с анимацией:
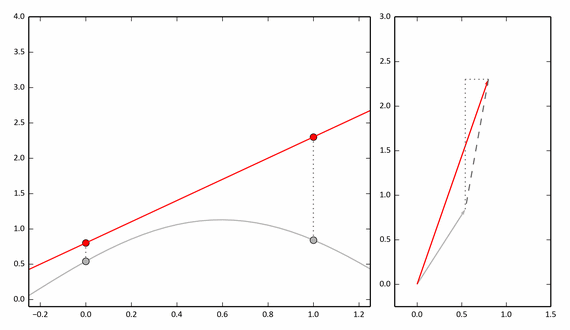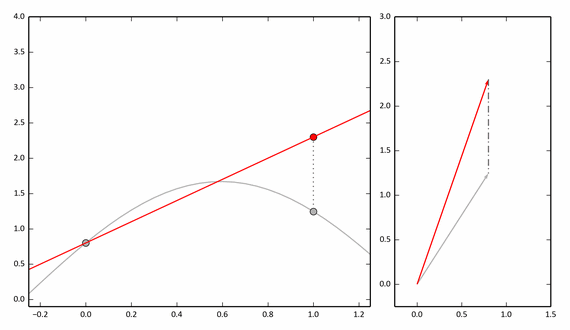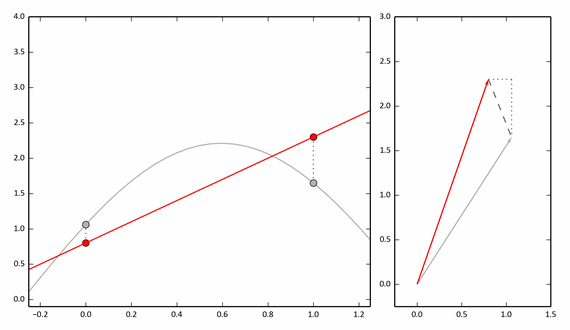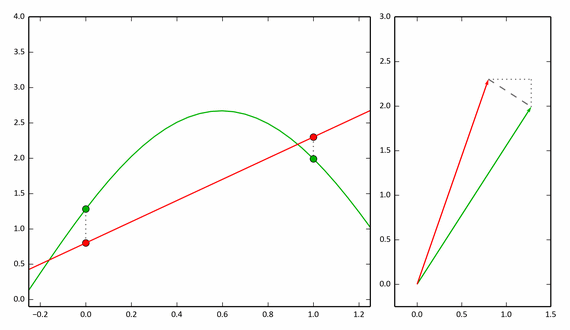
Если мы возьмем 3 точки, то нужно рассматривать трехмерные вектора, однако приближение будет точнее. А для дискретной функции с N значениями нужно рассматривать N-мерные вектора.
Имея набор полученных коэффициентов, можно легко получить исходную функцию, просуммировав базисные функции, взятые с соответствующими коэффициентами. Анализ этих коэффициентов может дать много полезной информации (в зависимости от базиса). Частным случаем этих соображений является принцип разложения в ряд Фурье. Ведь наши рассуждения применимы к любому базису, а при разложении в ряд Фурье берется вполне конкретный.
Дискретные преобразования Фурье (ДПФ)
В предыдущей части мы пришли к выводу, что неплохо было бы разлагать функцию на составные. В начале 19 века Фурье тоже задумался над этим. Правда картинки с енотом у него не было, поэтому ему пришлось исследовать распределение тепла по металлическому кольцу. Тогда он выяснил, что очень удобно выражать температуру (и ее изменение) в каждой точке кольца как сумму синусоид с разными периодами. «Фурье установил (рекомендую к прочтению, интересно), что вторая гармоника затухает в 4 раза быстрее, чем первая, а гармоники более высоких порядков затухают с ещё большей скоростью».
В общем, вскоре оказалось, что периодичные функции замечательно раскладываются на сумму синусоид. А так как в природе существует много объектов и процессов, описывающимися периодичными функциями, то появился мощный инструмент их анализа.
Пожалуй, один из самых наглядных периодических процессов — это звук.
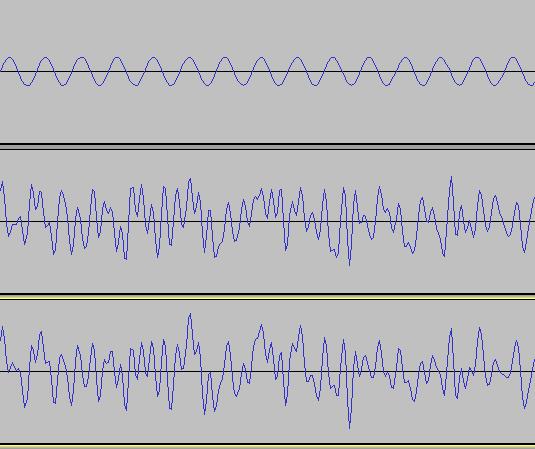
- 1-й график — чистый тон частотой 2500 герц.
- 2-й — белый шум. Т. е. шум c равномерно распределенными частотами по всему диапазону.
- 3-й — сумма первых двух.
Почему бы не попробовать взять синусоиды в качестве базиса? На самом деле мы фактически уже сделали это. Вспомним наше разложение на 3 базисных вектора и представим их на графике:
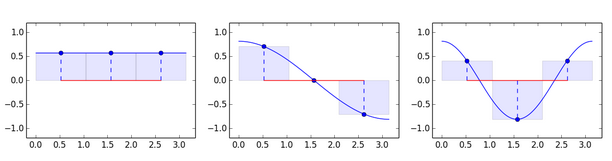
Да-да, знаю, это выглядит как подгонка, но с тремя векторами трудно ожидать большего. Зато теперь понятно, как получить, например, 8 базисных векторов:
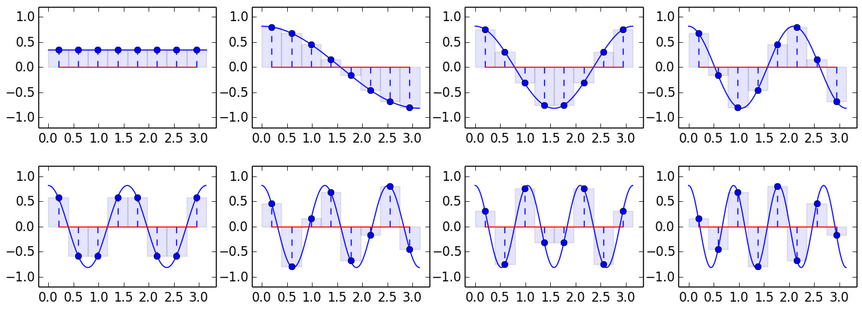
Не очень сложная проверка показывает, что эти вектора попарно перпендикулярны, т. е. ортогональны. Это значит, их можно использовать как базис. Преобразование по такому базису широко известно, и называется дискретным косинусным преобразованием (DCT). Думаю, из приведенных графиков понятно как получается формула DCT-преобразования:
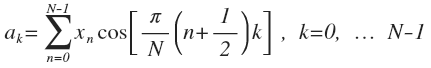
Это все та же формула: A = EX с подставленным базисом. Базисные вектора указанного DCT (они же векторы-строки матрицы E) ортогональны, но не ортонормированы. Это следует помнить при обратном преобразовании (не буду останавливаться на этом, но, кому интересно — у inverse DCT появляется слагаемое 0.5*a0, так как нулевой вектор базиса больше остальных).
На следующем примере показан процесс приближения промежуточных сумм к исходным значениям. На каждой итерации очередной базис умножается на очередной коэффициент и прибавляется к промежуточной сумме (то есть так же, как и в ранних опытах над енотом — треть значений, две трети).
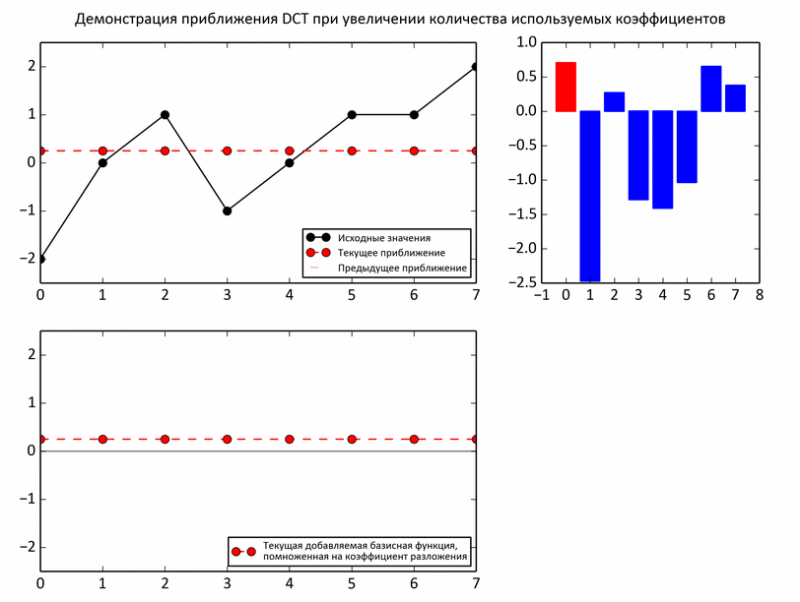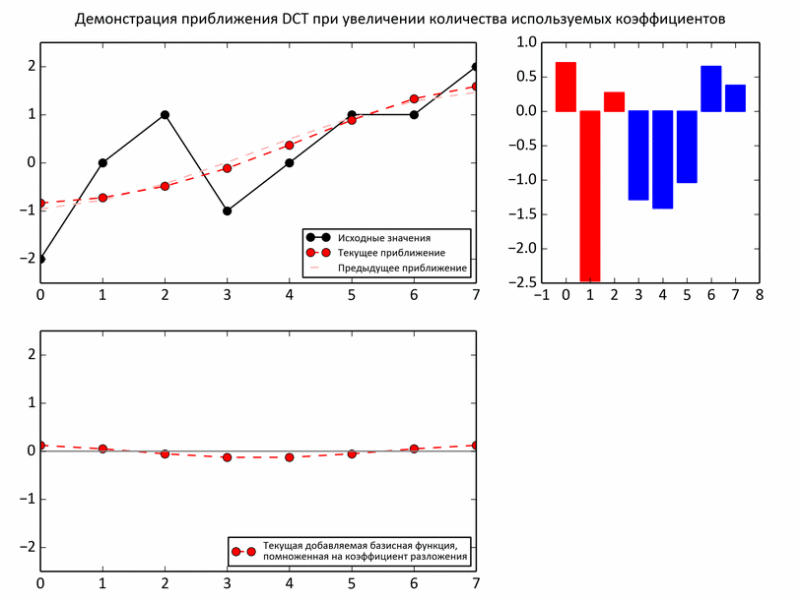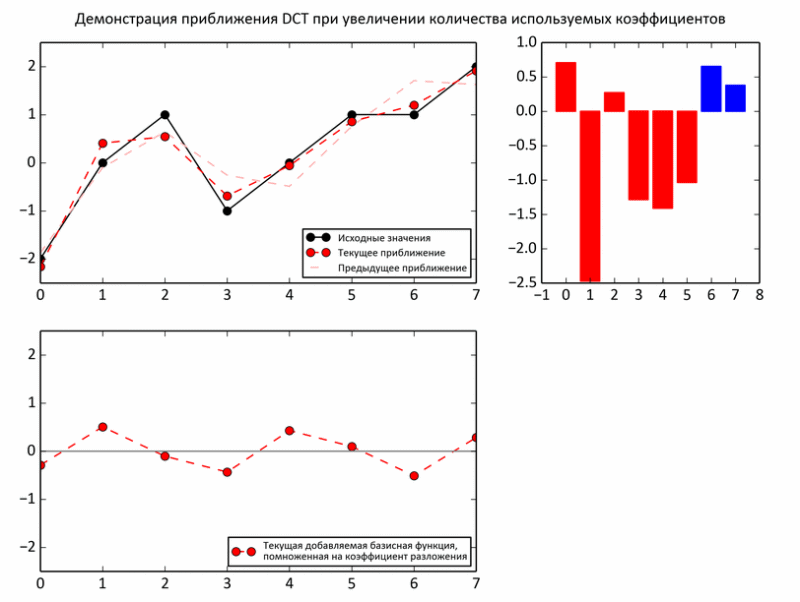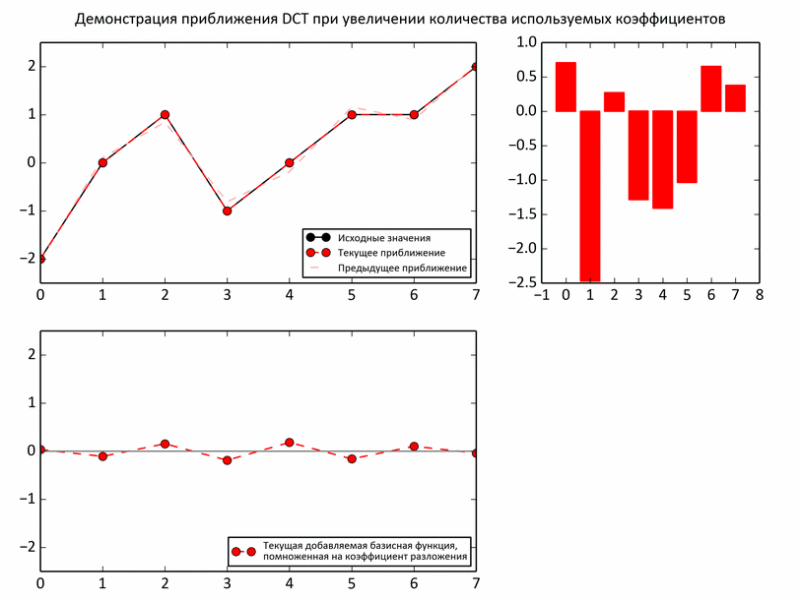
Но, все-таки, несмотря на некоторые доводы о целесообразности выбора такого базиса, реальных аргументов пока нет. Действительно, в отличие от звука, целесообразность разложения изображения на периодические функции гораздо менее очевидна. Впрочем, изображение действительно может быть слишком непредсказуемым даже на небольшом участке. Поэтому, картинку делят на достаточно маленькие кусочки, но не совсем крохотные, чтобы разложение имело смысл. В JPEG изображение «нарезается» на квадраты 8x8. В пределах такого кусочка фотографии обычно очень однородны: фон плюс небольшие колебания. Такие области шикарно приближаются синусоидами.
Ну, допустим, этот факт более или менее понятен интуитивно. Но появляется нехорошее предчувствие насчет резких цветовых переходов, ведь медленно изменяющиеся функции нас не спасут. Приходится добавлять разные высокочастотные функции, которые справляются со своей работой, но побочно проявляются на однородном фоне. Возьмем изображение 256x256 с двумя контрастными областями:

Разложим каждую строку с помощью DCT, получив, таким образом, по 256 коэффициентов на строку.
Затем оставим только первые n коэффициентов, а остальные приравняем нулю, и, поэтому, изображение будет представлено в виде суммы только первых гармоник:

Число на картинке — количество оставленных коэффициентов. На первом изображении осталось только среднее значение. На второй уже добавилась одна низкочастотная синусоида, и т. д. Кстати, обратите внимание на границу — несмотря на все лучшее приближение, рядом с диагональю хорошо заметны 2 полоски, одна светлее, другая темнее. Часть последнего изображения увеличенного в 4 раза:

И вообще, если вдали от границы мы видим первоначальный равномерный фон, то при приближении к ней, амплитуда начинает расти, наконец достигает минимального значения, а затем резко становится максимальным. Это явление известно как эффект Гиббса.
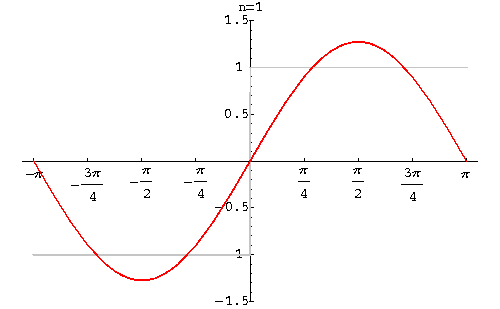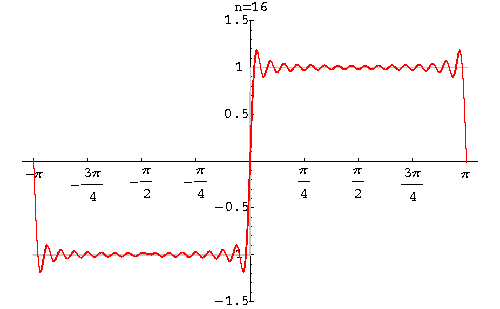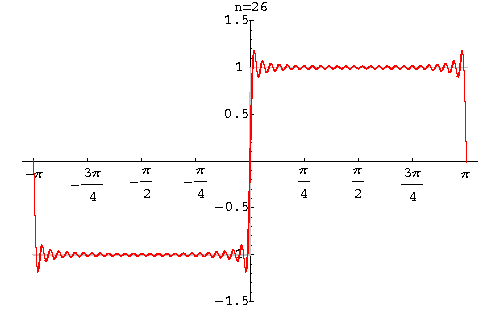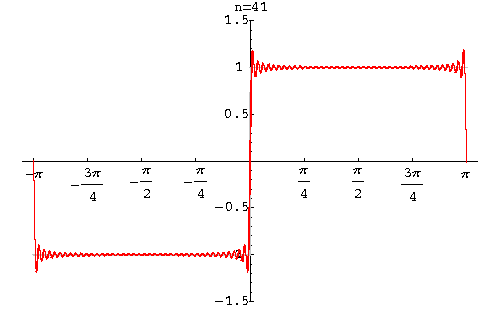
Высота этих горбов, появляющийся около разрывов функции, не уменьшится при увеличении количества слагаемых функций. В дискретном преобразовании оно пропадает только при сохранении почти всех коэффициентов. Точнее, становится незаметным.
Следующий пример полностью аналогичен вышеприведенному разложению треугольников, но уже на реальном еноте:

При изучении DCT может сложиться ложное впечатление, что всегда вполне достаточно всего нескольких первых (низкочастотных) коэффициентов. Это верно для многих кусочков фотографий, тех, чьи значения не меняются резко. Однако, на границе контрастных участков значения будут резво «скакать» и даже последние коэффициенты будут велики. Поэтому, когда слышите о свойстве сохранения энергии DCT, делайте поправку на то, что оно относится ко многим видам встречаемых сигналов, но не ко всем. Для примера подумайте, как будет выглядеть дискретная функция, коэффициенты разложения которой равны нулю, кроме последнего. Подсказка: представьте разложение в векторном виде.
Несмотря на недостатки, выбранный базис является одним из лучших на реальных фотографиях. Чуть позже мы увидим небольшое сравнение с другими.
DCT vs все остальное
Когда я изучал вопрос ортогональных преобразований, то, честно говоря, меня не очень убеждали доводы о том, что все вокруг — это сумма гармонических колебаний, поэтому нужно и картинки раскладывать на синусоиды. А может быть лучше подойдут какие-нибудь ступенчатые функции? Поэтому искал результаты исследований об оптимальности DCT на реальных изображениях. То, что «Именно DCT чаще всего встречается в практических приложениях благодаря свойству «уплотнения энергии»» написано везде. Это свойство означает, что максимальное количество информации заключено в первых коэффициентах. А почему? Нетрудно провести исследование: вооружаемся кучей разных картинок, различными известными базисами и начинаем считать среднеквадратичное отклонение от реального изображения для разного количества коэффициентов. Нашел небольшое исследование в статье(использованные изображения здесь) по этой методике. В ней приведены графики зависимости сохраненной энергии от количества первых коэффициентов разложений по разным базисам. Если вы просмотрели графики, то убедились, что DCT стабильно занимает почетное… эмм… 3-место. Как же так? Что еще за KLT преобразование? Я восхвалял DCT, а тут…
KLT
Все преобразования, кроме KLT, являются преобразованиями с постоянным базисом. А в KLT (преобразование Карунена-Лоэва) вычисляется самый оптимальный базис для нескольких векторов. Он вычисляется таким образом, что первые коэффициенты дадут наименьшую среднеквадратичную погрешность суммарно для всех векторов. Похожую работу мы проводили ранее вручную, визуально определяя базис. Сначала кажется, что это здравая идея. Мы могли бы, например, разбивать изображение на небольшие секции и для каждой вычислять свой базис. Но мало того, что появляется забота хранения этого базиса, так еще и операция его вычисления достаточно трудоемкая. А DCT проигрывает лишь немного, и к тому же у DCT существуют алгоритмы быстрого преобразования.
DFT
DFT (Discrete Fourier Transform) — дискретное преобразование Фурье. Под этим названием иногда упоминается не только конкретная трансформация, но и весь класс дискретных трансформаций (DCT, DST...). Посмотрим на формулу DFT:
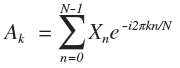
Как вы догадываетесь, это ортогональное преобразование с каким-то комплексным базисом. Так как подобная комплексная форма встречается чуть чаще, чем всегда, то имеет смысл изучить ее вывод.
Может сложится впечатление, что любой чистый гармонический сигнал (с целой частотой) при DCT разложении будет давать только один ненулевой коэффициент, соответствующий этой гармонике. Это не так, поскольку помимо частоты, важна и фаза этого сигнала. Например, разложение синуса по косинусам (подобным образом и в дискретном разложении) будет таким:
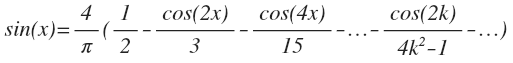
Вот вам и чистая гармоника. Она наплодила кучу других. На анимации показаны коэффициенты DCT синусоиды в разных фазах.
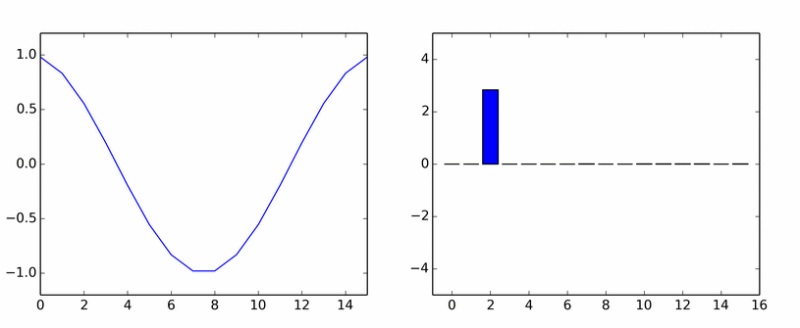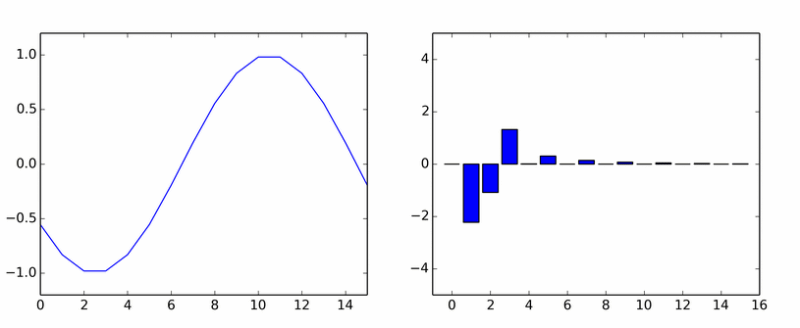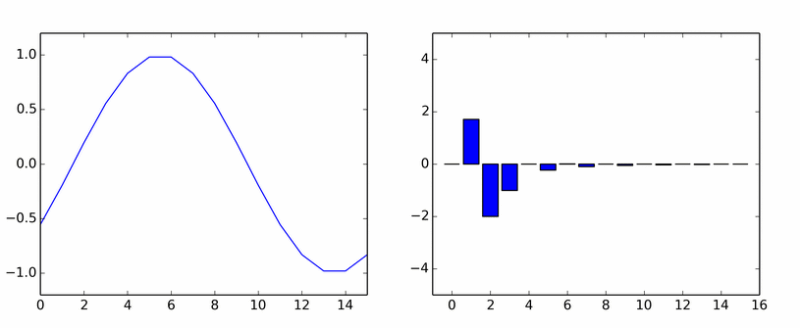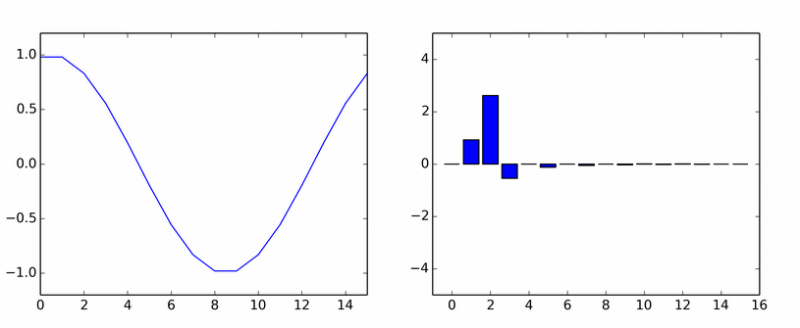
Если вам показалось, что столбики вращаются вокруг оси, то вам не показалось.
Значит теперь будем раскладывать функцию на сумму синусоид не просто разных частот, но еще и смещенных по какой-то фазе. Будет удобнее рассмотреть сдвиг фаз на примере косинуса:
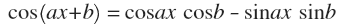
Простое тригонометрическое тождество дает важный результат: сдвиг по фазе заменяется суммой синуса и косинуса, взятых с коэффициентами cos(b) и sin(b). Значит, можно раскладывать функции на сумму синусов и косинусов (без всяких фаз). Это распространенная тригонометрическая форма. Однако, гораздо чаще используется комплексная. Для ее получения нужно воспользоваться формулой Эйлера. Просто подставим производные формулы для синуса и косинуса, получим:
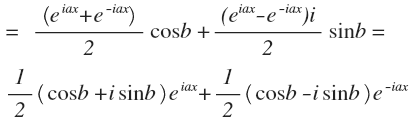
Теперь небольшая замена. Верхнее подчеркивание — сопряженное число.
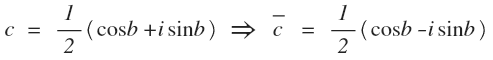
Получим итоговое равенство:
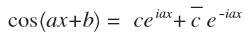
c — комплексный коэффициент, действительная часть которого равна косинусному коэффициенту, а мнимая — синусному. А множество точек (cos(b), sin(b)) является окружностью. В такой записи каждая гармоника входит в разложение и с положительной и с отрицательной частотой. Поэтому в различных формулах Фурье-анализа обычно происходит суммирование или интегрирование от минус до плюс бесконечности. Производить вычисления часто бывает удобнее именно в такой комплексной форме.
Преобразование раскладывает сигнал на гармоники с частотами от одного до N колебаний на области сигнала. Но частота дискретизации составляет N на области сигнала. А по теореме Котельникова (aka теорема Найквиста — Шеннона) частота дискретизации должна по крайней мере в два раза превышать частоту сигнала. Если это не так, то получается эффект появления сигнала с ложной частотой:
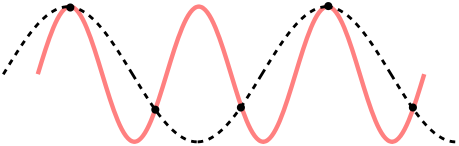
Пунктирной линий показан неверно восстановленный сигнал. С таким явлением вы часто сталкивались в жизни. Например, забавное движение колес автомобиля на видео, или муаровый эффект.
Это приводит к тому, что вторая половина из N комплексных амплитуд как будто состоит из других частот. Эти ложные гармоники второй половины являются зеркальным отображением первой и не несут дополнительной информации. Таким образом, у нас остается N/2 косинусов и N/2 синусов (образующих ортогональный базис).
Ладно, базис есть. Его составляющие — гармоники с целым числом колебаний на области сигнала, а значит, крайние значения гармоник равны. Точнее почти равны, так как последнее значение берется не совсем с края. Более того — каждая гармоника почти зеркально симметрична относительно своего центра. Все эти явления особенно сильны на низких частотах, которые нам и важны при кодировании. Это плохо еще и тем, что на сжатом изображении будут заметны границы блоков. Проиллюстрирую DFT-базис с N=8. Первые 2 ряда — косинусные составляющие, последние — синусные:
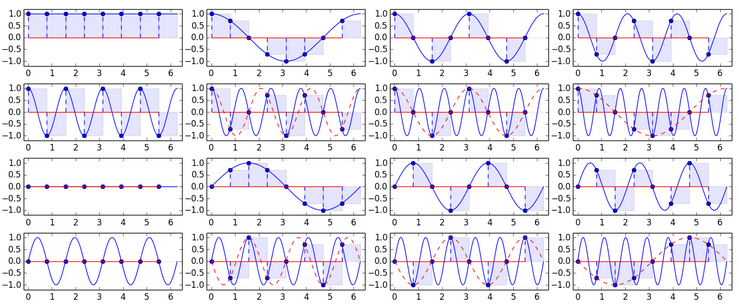
Обратите внимание на появление дублей составляющих при повышении частоты.
Можете мысленно подумать, как мог бы быть разложен сигнал, значения которого плавно уменьшаются с максимального значения в начале до минимального в конце. Более-менее адекватное приближение смогли бы сделать лишь гармоники ближе к концу, что для нас не очень здорово. На рисунке слева приближение несимметричного сигнала. Справа — симметричного:
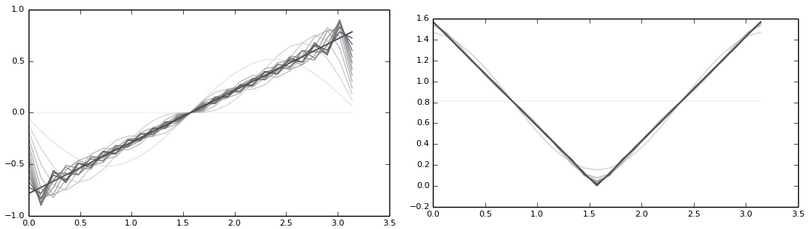
С первым дела крайне плохи.
Так может быть сделать как в DCT — уменьшить частоты в 2 или другое количество раз, чтобы количество некоторых колебаний было дробным и границы находились в разных фазах? Тогда составляющие будут неортогональны. И ничего тут не поделать.
DST
Что если вместо косинусов в DCT использовать синусы? Мы получим Discrete Sine Transform (DST). Но для нашей задачи все они неинтересны, так как и целые и половинки периодов синусов близки к нулю на границах. То есть мы получим примерно такое же неподходящее разложение, как и у DFT.
Возвращаясь к DCT
Как у него дела на границах? Хорошо. Есть противофазы и нет нулей.
Все остальное
Не-Фурье преобразования. Не буду описывать.
WHT — матрица состоит только из ступенчатых составляющих со значениями -1 и 1.
Haar — по совместительству ортогональное вейвлет-преобразование.
Они уступают DCT, но легче для вычислений.
Итак, вас посетила мысль придумать свое преобразование. Помните вот что:
- Базис должен быть ортогонален.
- С фиксированным базисом вы не сможете превзойти KLT по качеству сжатия. Между тем, на реальных фотографиях DCT почти не уступает.
- На примере DFT и DST нужно помнить про границы.
- И помнить, что у DCT есть еще хорошее преимущество — вблизи границ составляющих их производные равны нулю, а значит, переход между соседними блоками будет довольно плавным.
- У преобразований Фурье существуют быстрые алгоритмы со сложностью O(N*logN), в отличие от вычисления в лоб: O(N2).
Будет непросто, правда? Впрочем, для некоторых типов изображений можно подобрать лучший базис, чем у DCT.
Этот раздел получился похожим на рекламу дискретного косинусного преобразования. Но оно действительно классное!
Двумерные преобразования
Сейчас попробуем провести такой эксперимент. Возьмем, для примера, кусочек изображения.

Его 3D график:
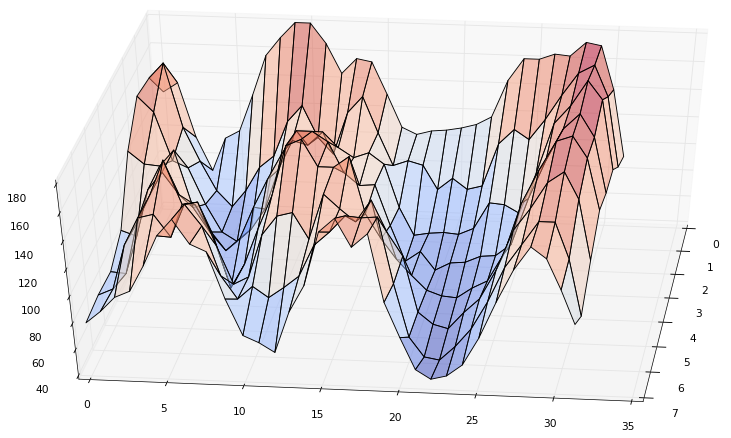
Пройдемся DCT(N=32) по каждой строке:
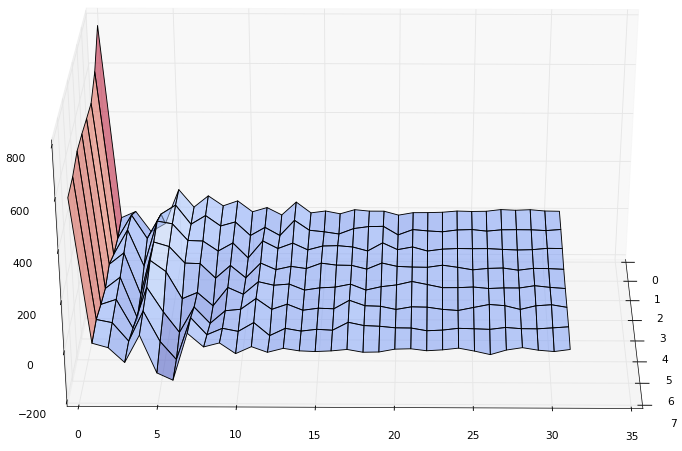
Теперь я хочу, чтобы вы пробежались глазами по каждому столбцу полученных коэффициентов, т. е. сверху вниз. Вспомните, что наша цель — оставить как можно меньше значений, убрав малозначащие. Наверняка вы догадались, что значения каждого столбца полученных коэффициентов можно разложить точно так же, как и значения исходного изображения. Никто не ограничивает нас в выборе ортогональной матрицы преобразования, но мы сделаем это опять с помощью DCT(N=8):
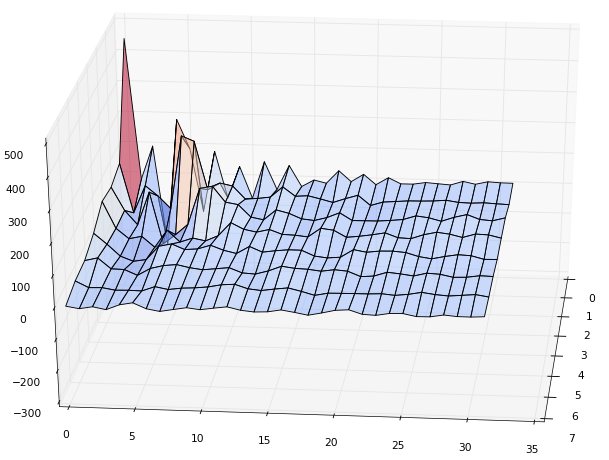
Коэффициент (0,0) получился слишком большим, поэтому на графике он уменьшен в 4 раза.
Итак, что получилось?
Левый верхний угол — самые значащие коэффициенты разложения самых значащих коэффициентов.
Левый нижний угол — самые незначащие коэффициенты разложения самых значащих коэффициентов.
Правый верхний угол — самые значащие коэффициенты разложения самых незначащих коэффициентов.
Правый нижний угол — самые незначащие коэффициенты разложения самых незначащих коэффициентов.
Понятно, что значимость коэффициентов уменьшается, если двигаться по диагонали из левого верхнего угла в правый нижний. А какой важнее: (0, 7) или (7, 0)? Что они вообще означают?
Сначала по строкам: A0 = (EXT)T = XET (транспонировали, так как формула A=EX для столбцов), затем по столбцам: A=EA0 = EXET. Если аккуратно посчитать, то получится формула:
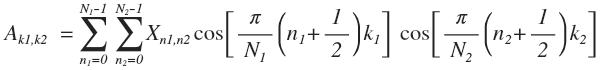
Таким образом, если вектор раскладывается на синусоиды, то матрица на функции вида cos(ax)*cos(by). Каждый блок 8x8 в JPEG представляется в виде суммы 64-х функций вида:

В Википедии и других источниках такие функции представлены в более удобной форме:

Поэтому коэффициенты (0, 7) или (7, 0) одинаково полезны.
Впрочем, фактически это обычное одномерное разложение на 64 64-мерных базиса. Все вышесказанное применимо не только к DCT, но и к любому ортогональному разложению. Действуя по аналогии, в общем случае получаем N-мерное ортогональное преобразование.
А вот уже 2-мерное преобразование енота (DCT 256x256). Опять же с обнуленными значениями. Числа — количество необнуленных коэффициентов из всех (оставлялись самые значимые значения, находящиеся в треугольной области в левом верхнем углу).

Запомните, что коэффициент (0, 0) называется DC, остальные 63 — AC.
Выбор размера блока
Товарищ спрашивает: почему в JPEG используется разбиение именно 8x8. Из заплюсованного ответа:
The DCT treats the block as if it were periodic and has to reconstruct the resulting jump at the boundaries. If you take 64x64 blocks, you'll most likely have a huge jump at the boundaries, and you'll need lots of high-frequency components to reconstruct that to a satisfactory precisionМол, DCT работает хорошо только на периодических функциях, и если вы возьмете большой размер, то, скорее всего, получите гигантский скачок на границах блока и понадобится много высокочастотных компонентов для его покрытия. Это неверно! Такое объяснение очень похоже на DFT, но не на DCT, так как оно отлично покрывает такие скачки уже первыми составляющими.
На той же странице приводится ответ из MPEG FAQ, с основными аргументами против больших блоков:
- Мало прибыли при разбиении на большие блоки.
- Увеличение вычислительной сложности.
- Высокая вероятность большого количества резких границ в одном блоке, что вызовет эффект Гиббса.
Предлагаю самостоятельно исследовать это. Начнем с первого.
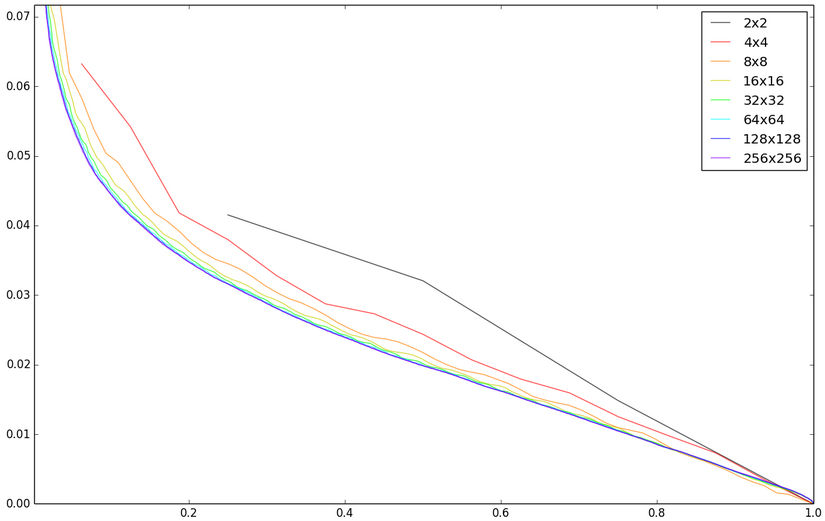
По горизонтальной оси — доля первых необнуленных коэффициентов. По вертикальной — среднеквадратичное отклонение пикселей от оригинала. Максимальное возможное отклонение взято за единицу. Разумеется, для вердикта явно недостаточно одной картинки. К тому же, я действую не совсем правильно, просто обнуляя. В реальном JPEG, в зависимости от матрицы квантования, обнуляются только маленькие значения высокочастотных компонентов. Поэтому, следующие эксперименты и выводы предназначены для поверхностного выявления принципов и закономерностей.
Можно сравнить разбиение на разные блоки с оставленными 25-ю процентами коэффициентов (слева направо, затем справа налево):

Большие блоки не показаны, так как визуально почти неотличимы от 32x32. Теперь посмотрим на абсолютную разность с исходным изображением (усиленную в 2 раза, иначе ничего толком не видно):

8x8 дает лучший результат, чем 4x4. Дальнейшее увеличение размера уже не дает хорошо заметного преимущества. Хотя я всерьез бы задумался над 16x16, вместо 8x8: увеличение сложности на 33% (о сложности в следующем абзаце), дает небольшое, но все-таки видимое улучшение при одинаковом количестве коэффициентов. Однако, выбор 8x8 выглядит достаточно обоснованным и, возможно, является золотой серединой. JPEG был опубликован в 1991. Думаю, что такое сжатие являлось очень сложным для процессоров того времени.
Второй аргумент. Нужно помнить, что при увеличении размера блока потребуется больше вычислений. Давайте оценим насколько. Сложность преобразования в лоб, как мы уже вполне умеем: O(N2), так как каждый коэффициент состоит из N слагаемых. Но на практике используется эффективный алгоритм быстрого преобразования Фурье (БПФ, Fast Fourier Transform, FFT). Его описание выходит за рамки статьи. Его сложность: O(N*logN). Для двумерного разложения нужно воспользоваться им дважды по N раз. Таким образом, сложность 2D DCT — O(N2logN). Теперь сравним сложности вычисления изображения одним блоком и несколькими маленькими:
- Одним блоком (kN)x(kN): O((kN)2log(kN)) = O(k2N2log(kN))
- k*k блоками N*N: O(k2N2logN)
Это значит, что, например, вычисление при разбиении на 64x64 в два раза сложнее, чем на 8x8.
Третий аргумент. Если у нас на изображении есть резкая граница цветов, то это скажется на всем блоке. Возможно, лучше этот блок будет достаточно мал, ведь во многих соседних блоках, такой границы, вероятно, уже не будет. Однако, вдали от границ затухание происходит достаточно быстро. К тому же сама граница будет выглядеть лучше. Проверим на примере с большим количеством контрастных переходов, опять же, только с четвертью коэффициентов:

Хотя искажения блоков 16x16 простираются дальше, чем у 8x8, но надпись более плавная. Поэтому меня убедили только первые два аргумента. Но мне что-то больше нравится разделение на 16x16.
Квантование
На данном этапе мы имеем кучу матриц 8x8 с коэффициентами косинусного преобразования. Пришло время избавляться от малозначащих коэффициентов. Существует более элегантное решение, чем просто обнулять последние коэффициенты, как мы делали выше. Нас не устраивает этот способ, так как необнуленные значения хранятся с избыточной точностью, а среди тех, кому не повезло, могли оказаться достаточно важные. Выход — нужно использовать матрицу квантования. Потери происходят именно на этом этапе. Каждый Фурье-коэффициент делится на соответствующее число в матрице квантования. Рассмотрим на примере. Возьмем первый блок от нашего енота и произведем квантование. В спецификации JPEG приводится стандартная матрица:
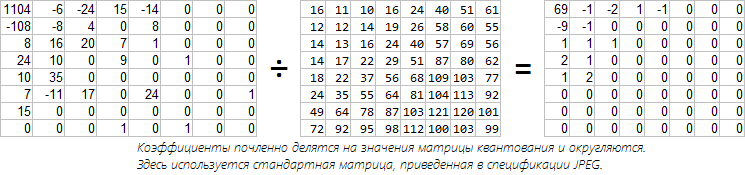
Стандартная матрица соответствует 50% качеству в FastStone и IrfanView. Такая таблица была выбрана с точки зрения баланса качества и степени сжатия. Думаю, что значение для DC-коэффициента больше соседних из-за того, что DCT ненормализовано и первое значение получается больше, чем следовало бы. Высокочастотные коэффициенты огрубляются сильнее из-за их меньшей важности. Думаю, сейчас такие матрицы используются редко, так как ухудшение качества хорошо заметно. Никто не запрещает использовать свою таблицу (со значениями от 1 до 255)
При декодировании происходит обратный процесс — квантованные коэффициенты почленно умножаются на значения матрицы квантования. Но так как мы округляли значения, то не сможем точно восстановить исходные коэффициенты Фурье. Чем больше число квантования, тем больше погрешность. Таким образом, восстановленный коэффициент является лишь ближайшим кратным.
Еще пример:
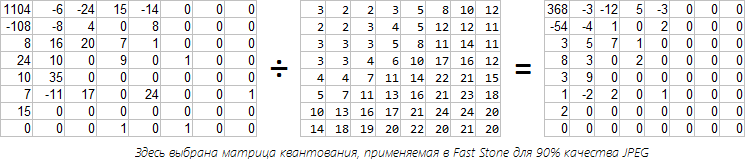
И на десерт, рассмотрим качество 5% (при кодировании в Fast Stone).

При восстановлении этого блока мы получим только усредненное значение плюс вертикальный градиент (из-за сохранившегося значения -1). Зато для него хранится всего два значения: 7 и -1. C другими блоками ситуация не лучше, вот восстановленная картинка:

Кстати, насчет 100% качества. Как вы догадываетесь, в этом случае матрица квантования состоит полностью из единиц, то есть квантования не происходит. Однако, из-за округления коэффициентов до целого, мы не можем в точности восстановить исходную картинку. Например, енот сохранил 96% пикселей точно, а 4% отличались на 1/256. Разумеется, такие «искажения» невозможно заметить визуально.
А здесь можете посмотреть матрицы квантования различных фотоаппаратов.
Кодирование
Перед тем как двигаться дальше, нам нужно на более простых примерах понять, как можно сжать полученные значения.
Пример 0 (для разминки)
Представьте такую ситуацию, что ваш знакомый забыл у вас дома листочек со списком и теперь просит продиктовать его по телефону (других способов связи нет).
Список:
- d9rg3
- wfr43gt
- wfr43gt
- d9rg3
- d9rg3
- d9rg3
- wfr43gt
- d9rg3
Как бы вы облегчили свою задачу? Особого желания мучительно диктовать все эти слова у вас нет. Но их всего два и они повторяются. Поэтому вы просто как-нибудь диктуете первые два слова и договариваетесь, что далее «d9rg3» будете называть первым словом, а «wfr43gt» — вторым. Тогда достаточно будет продиктовать: 1, 2, 2, 1, 1, 1, 2, 1.
Подобные слова мы будем обозначать как A, B, C..., и называть их символами. Причем под символом может скрываться что угодно: буква алфавита, слово или бегемот в зоопарке. Главное, что одинаковым символам соответствуют одинаковые понятия, а разным — разные. Так как наша задача — эффективное кодирование (сжатие), то будем работать с битами, так как это наименьшие единицы представления информации. Поэтому, запишем список как ABBAAABA. Вместо «первое слово» и «второе слово» можно использовать биты 0 и 1. Тогда ABBAAABA закодируется как 01100010 (8 бит = 1 байт).
Пример 1
Закодировать ABC.
3-м разным символам (A, B, C) никак нельзя сопоставить 2 возможных значений бита (0 и 1). А раз так, то можно использовать по 2 бита на символ. Например:
- A: 00
- B: 01
- C: 10
Последовательность битов, сопоставленная символу, будем называть кодом. ABC будет кодироваться так: 000110.
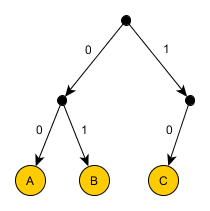
Пример 2
Закодировать AAAAAABC.
Использовать по 2 бита на символ A кажется немного расточительным. Что, если попробовать так:
- A: 0
- B: 1
- C: 00
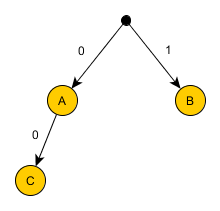
Закодированная последовательность: 000000100.
Очевидно, этот вариант не подходит, так как непонятно, как декодировать первые два бита этой последовательности: как AA или как C? Использовать какой-нибудь разделитель между кодами очень расточительно, будем думать как по-другому обойти это препятствие. Итак, неудача произошла из-за того, что код C начинается с кода A. Но мы полны решимости кодировать A одним битом, пусть даже B и С будут по два. Исходя из такого пожелания, A дадим код 0. Тогда коды B и C не могут начинаться на 0. Но могут на 1:
- A: 0
- B: 10
- C: 11
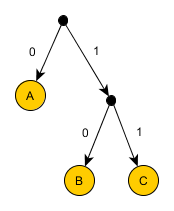
Последовательность закодируется так: 0000001011. Попробуйте мысленно декодировать ее. Вы сможете сделать это только одним способом.
Мы выработали два требования к кодированию:
- Чем больше вес символа, тем короче должен быть его код. И наоборот.
- Для однозначного декодирования код символа не может начинаться с кода любого другого символа.
Очевидно, порядок символов не важен, нас интересует только частота их встречаемости. Поэтому, с каждым символом сопоставляют некоторое число, называемое весом. Вес символа может являться как относительной величиной, отражающий долю его вхождения, так и абсолютной, равной количеству символов. Главное, чтобы веса были пропорциональны встречаемости символов.
Пример 3
Рассмотрим общий случай для 4-х символов с любыми весами.
- A: pa
- B: pb
- C: pc
- D: pd
Без потери общности, положим pa ≥ pb ≥ pc ≥ pd. Существуют всего два принципиально разных по длинам кодов варианта:
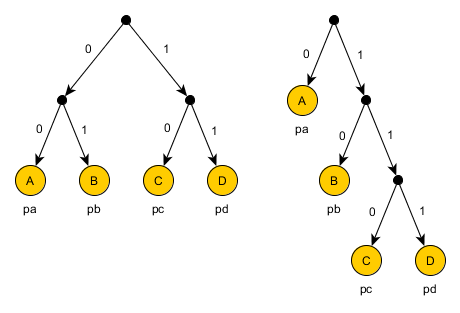
Какое из них предпочтительнее? Для этого нужно вычислить получаемые длины закодированных сообщений:
W1 = 2*pa + 2*pb + 2*pc + 2*pd
W2 = pa + 2*pb + 3*pc + 3*pd
Если W1 меньше W2 (W1-W2<0), то лучше использовать первый вариант:
W1-W2 = pa — (pc+pd) < 0 => pa < pc+pd.
Если C и D вместе встречаются чаще других, то их общая вершина получает самый короткий код из одного бита. В противном случае, один бит достается символу A. Значит, объединение символов ведет себя как самостоятельный символ и имеет вес равный сумме входящих символов.
Вообще, если p — вес символа представленный долей его вхождения (от 0 до 1), то лучшая длина кода s=-log2p.
Рассмотрим это на простом случае (его легко представить в виде дерева). Итак, нужно закодировать 2s символов с равными весами (1/2s). Из-за равенства весов длины кодов будут одинаковыми. Каждому символу потребуется s бит. Значит, если вес символа 1/2s, то его длина s. Если вес заменить заменить на p, то получим длину кода
И еще одно наблюдение — два символа с наименьшими весами всегда имеют наибольшие, но равные длины кодов. Более того, их биты, кроме последнего, совпадают. Если бы это было неверно, то, по крайней мере, один код можно было бы укоротить на 1 бит, не нарушая префиксности. Значит, два символа с наименьшими весами в кодовом дереве имеют общего родителя уровнем выше. Вы можете видеть это на примере С и D выше.
Пример 4
Попробуем решить следующий пример, по выводам, полученным в предыдущем примере.
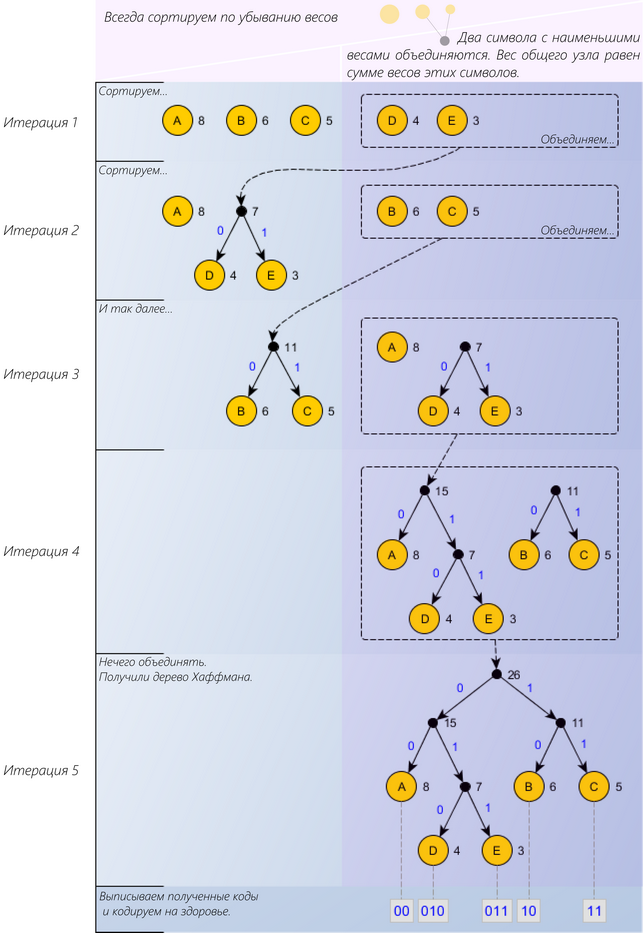
- Все символы сортируются в порядке убывания весов.
- Два последних символа объединяются в группу. Этой группе присваивается вес, равный сумме весов этих элементов. Эта группа участвует в алгоритме наравне с символами и другими группами.
Шаги повторяются, пока не останется только одна группа. В каждой группе одному символу (или подгруппе) присваивается бит 0, а другому бит 1.
Этот алгоритм называется кодированием Хаффмана.
На иллюстрации приведен пример с 5-ю символами (A: 8, B: 6, C: 5, D: 4, E: 3). Справа указан вес символа (или группы).
Кодируем коэффициенты
Возвращаемся. Сейчас мы имеем много блоков с 64-я коэффициентами в каждом, которые нужно как-то сохранить. Самое простое решение — использовать фиксированное количество бит на коэффициент — очевидно, неудачное. Построим гистограмму всех полученных значений (т.е. зависимость количества коэффициентов от их значения):
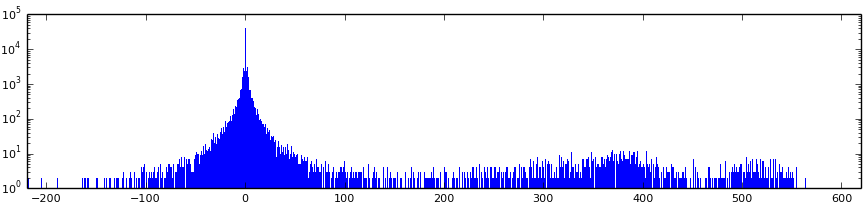
Обратите внимание — шкала логарифмическая! Сможете объяснить причину появления скопления значений превышающих 200? Это DC-коэффициенты. Так как они сильно отличаются от остальных, то неудивительно, что их кодируют отдельно. Вот только DC:
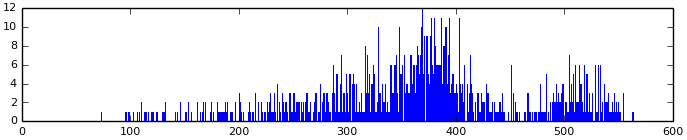
Обратите внимание, что форма графика напоминает форму графиков из самих ранних экспериментов деления на пары и тройки пикселей
Вообще, значения DC-коэффициентов могут меняться от 0 до 2047 (точнее от -1024 до 1023, так как в JPEG производится вычитание 128 из всех исходных значений, что соответствует вычитанию 1024 из DC) и распределяться довольно равномерно с небольшими пиками. Поэтому кодирование Хаффмана здесь не очень-то поможет. А еще представьте, каким большим будет дерево кодирования! И во время декодирования придется искать в нем значения. Это очень затратно. Думаем дальше.
DC-коэффициент — усредненное значение блока 8x8. Представим градиентный переход (пусть не идеальный), который часто встречается в фотографиях. Сами DC значения будут разными, но они будут представлять арифметическую прогрессию. Значит, их разность будет более-менее постоянна. Построим гистограмму разностей:
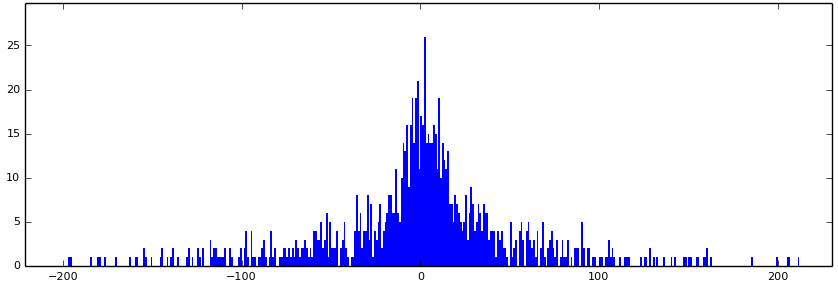
Вот это уже лучше, потому что значения, в целом, сконцентрированы около нуля (но алгоритм Хаффмана опять даст слишком большое дерево). Маленькие значения (по абсолютной величине) встречаются часто, большие редко. А так как маленькие значения занимают мало бит (если убрать ведущие нули), то хорошо выполняется одно из правил сжатия: символам с большими весами присваивать короткие коды (и наоборот). Нас пока ограничивает невыполнение другого правила: невозможность однозначного декодирования. В целом, такая проблема решается следующими способами: заморочиться с кодом-разделителем, указывать длину кода, использовать префиксные коды (они вам уже известны — это случай, когда ни один код не начинается с другого). Пойдем по простому второму варианту, т. е. каждый коэффициент (точнее, разница соседних) будет записываться так: (длина)(значение), по такой табличке:
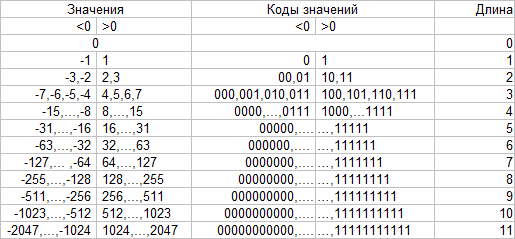
То есть положительные значения прямо кодируются их двоичным представлением, а отрицательные — так же, но с заменой ведущей 1 на 0. Осталось решить, как кодировать длины. Так как их 12 возможных значений, то можно использовать 4 бита для хранения длины. Но вот тут-то как раз лучше использовать кодирование Хаффмана.
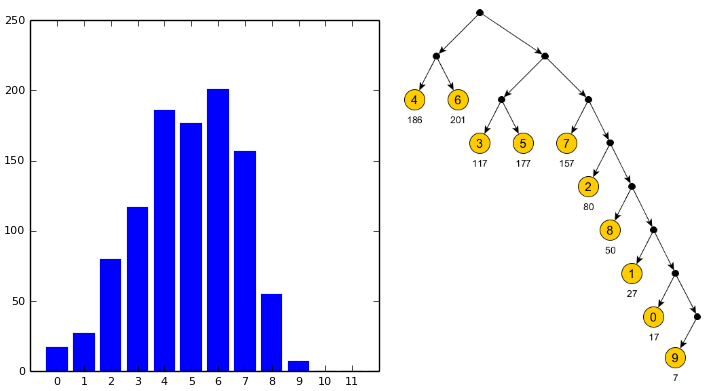
Значений с длинами 4 и 6 больше всего, поэтому им достались самые короткие коды (00 и 01).
Особенности реализации в JPEG:
Может возникнуть вопрос: почему на примере у значения 9 код 1111110, а не 1111111? Ведь можно смело поднять «9» на уровень выше, рядом с «0»? Дело в том, что в JPEG нельзя использовать код, состоящий только из единиц — такой код зарезервирован.
Есть еще одна особенность. Коды, полученные описанным алгоритмом Хаффмана могут не совпасть по битам с кодами в JPEG, хотя их длины будут одинаковыми. Используя алгоритм Хаффмана, получают длины кодов, а сами коды генерируются (алгоритм прост — начинают с коротких кодов и добавляют их по очереди в дерево как можно левее, сохраняя свойство префиксности). Например, для дерева выше хранится список: 0,2,3,1,1,1,1,1. И, разумеется, хранится список значений: 4,6,3,5,7,2,8,1,0,9. При декодировании коды генерируются таким же способом.
Теперь порядок. Мы разобрались как хранятся DC:
[код Хаффмана для длины DCdiff(в битах)][DCdiff]
где DCdiff = DCтекущее — DCпредыдущее
Смотрим AC:
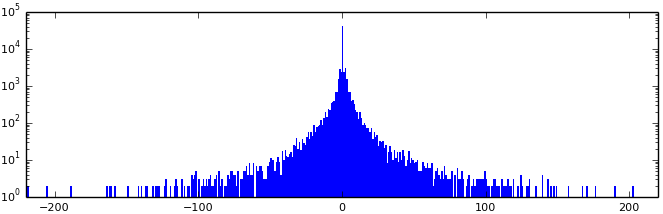
Так как график очень похож на график для разностей DC, то принцип тот же: [код Хаффмана для длины AC (в битах)][AC]. Но не совсем! Так как на графике шкала логарифмическая, то не сразу заметно, что нулевых значений примерно в 10 раз больше, чем значения 2 — следующего по частоте. Это понятно — не все пережили квантование. Вернемся к матрице значений, полученной на этапе квантования (используя матрицу квантования FastStone, 90%).
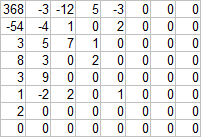
Так как встречается много групп подряд идущих нулей, то появляется идея — записывать только количество нулей в группе. Такой алгоритм сжатия называется RLE (Run-length encoding, кодирование повторами). Осталось выяснить направление обхода «подряд идущих» — кто за кем? Выписать слева направо и сверху вниз — не очень эффективно, так как ненулевые коэффициенты концентрируются около левого верхнего угла, а чем ближе к правому нижнему — тем больше нулей.
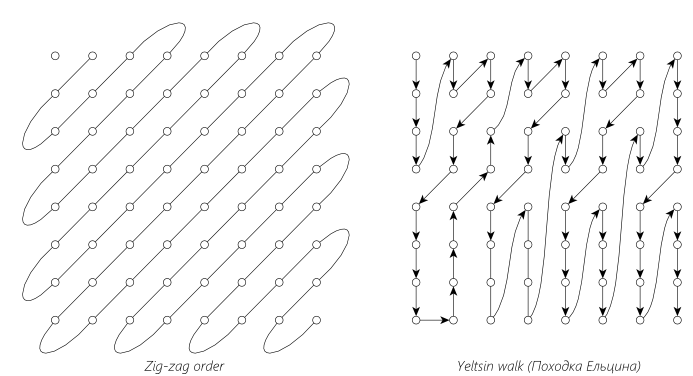
Поэтому, в JPEG используется порядок, называемый «Zig-zag», он показан на левом рисунке. Такой способ хорошо выделяет группы нулей. На правом рисунке — альтернативный способ обхода, не относящийся к JPEG, зато с любопытным названием (пруф). Он может использоваться в MPEG при сжатии видео с чересстрочной разверткой. Выбор алгоритма обхода не влияет на качество изображения, но может увеличить количество кодируемых групп нулей, что в итоге может отразиться на размере файла.
Модифицируем нашу запись. Для каждого ненулевого AC — коэффициента:
[Количество нулей перед AC][код Хаффмана для длины AC (в битах)][AC]
Думаю, что вы сразу скажете — количество нулей тоже отлично закодируется Хаффманом! Это очень близкий и неплохой ответ. Но можно немного оптимизировать. Представьте, что имеем некоторый коэффициент AC, перед которым было 7 нулей (разумеется, если выписывать в зигзагообразном порядке). Эти нули — дух значений, которые не выдержали квантования. Скорее всего, наш коэффициент тоже сильно потрепало и он стал маленьким, а, значит, его длина — короткой. Значит, количество нулей перед AC и длина AC — зависимые величины. Поэтому записывают так:
[код Хаффмана для (Количество нулей перед AC, длина AC (в битах)][AC]
Алгоритм кодирования остается тем же: те пары (количество нулей перед AC, длина AC), которые встречаются часто, получат короткие коды и наоборот.
Строим гистограмму зависимости количества по этим парам и дерево Хаффмана.
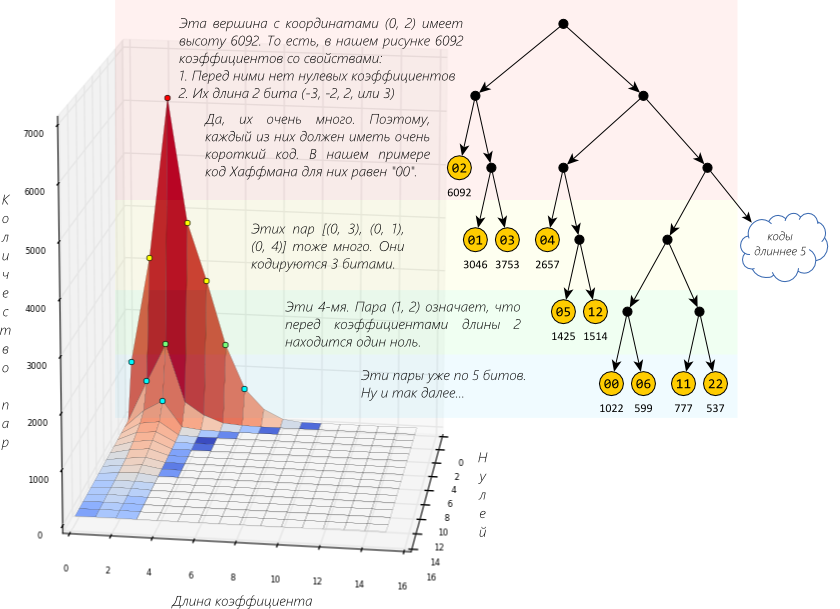
Длинный «горный хребет» подтверждает наше предположение.
Особенности реализации в JPEG:
Такая пара занимает 1 байт: 4 бита на количество нулей и 4 бита на длину AC. 4 бита — это значения от 0 до 15. Для длины AC хватит с избытком, но ведь нулей может быть больше 15? Тогда используется больше пар. Например, для 20 нулей: (15, 0)(5, AC). То есть, 16-й ноль кодируется как ненулевой коэффициент. Так как ближе к концу блока всегда полно нулей, то после последнего ненулевого коэффициента используется пара (0,0). Если она встретится при декодировании, значит оставшиеся значения равны 0.
Выяснили, что каждый блок закодирован хранится в файле так:
[код Хаффмана для длины DCdiff]
[DCdiff]
[код Хаффмана для (количество нулей перед AC1, длина AC1]
[AC1]
…
[код Хаффмана для (количество нулей перед ACn, длина ACn]
[ACn]
Где ACi — ненулевые AC коэффициенты.
Цветное изображение
Способ представления цветного изображения зависит от выбранной цветовой модели. Простое решение — использовать RGB и кодировать каждый цветовой канал изображения по отдельности. Тогда кодирование не будет отличаться от кодирования серого изображения, только работы в 3 раза больше. Но сжатие изображения можно увеличить, если вспомнить, что глаз более чувствительнее к изменению яркости, чем цвета. Это значит, что цвет можно хранить с бОльшими потерями, чем яркость. У RGB нет отдельного канала яркости. Она зависит от суммы значений каждого канала. Поэтому, RGB-куб (это представление всех возможных значений) просто «ставят» на диагональ — чем выше, тем ярче. Но на этом не ограничиваются — куб немного поджимают с боков, и получается скорее параллелепипед, но это лишь для учета особенностей глаза. Например, он более восприимчив к зеленому, чем синему. Так появилась модель YCbCr.
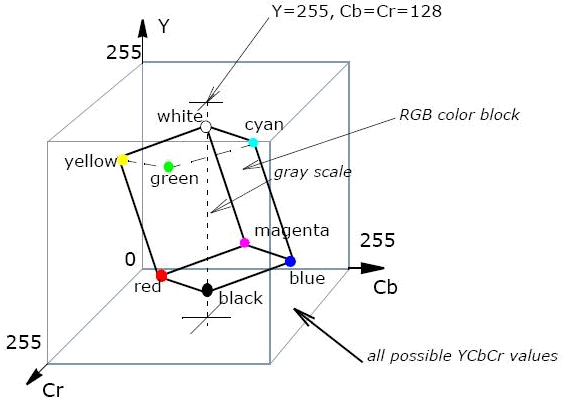
(Изображение с Intel.com)
Y — компонента яркости, Cb и Cr являются синей и красной цветоразностными компонентами. Поэтому, если хотят сильнее сжать изображение, то RGB переводят в YCbCr, и каналы Cb и Cr прореживают. То есть разбивают на небольшие блоки, например 2x2, 4x2, 1x2, и усредняют все значения одного блока. Или, другими словами, уменьшают размер изображения для этого канала в 2 или 4 раза по вертикали и/или горизонтали.

Каждый блок 8x8 кодируется (DCT + Хаффман), и закодированные последовательности записываются в таком порядке:

Любопытно, что спецификация JPEG не ограничивает в выборе модели, то есть реализация кодировщика может как угодно разделить изображение по цветовым компонентам (каналам) и каждый будет сохранен по отдельности. Мне известно об использовании Grayscale (1 канал), YCbCr (3), RGB (3), YCbCrK (4), CMYK (4). Первые три поддерживаются почти всеми, а вот с последними 4-канальными бывают проблемы. FastStone, GIMP поддерживают их корректно, а штатные программы Windows, paint.net


Если они различаются по цветам, или видна только одна картинка, то, скорее всего, у вас IE (любой версии) (UPD. в комментариях говорят «или Safari»). Можете попробовать открыть статью в разных браузерах.
И еще кое-что
В двух словах о дополнительных возможностях.
Progressive mode
Разложим полученные таблицы коэффициентов DCT на сумму таблиц (примерно так (DC, -19, -22, 2, 1) = (DC, 0, 0, 0, 0) + (0, -20, -20, 0, 0) + (0, 1, -2, 2, 1)). Сначала закодируем все первые слагаемые (как мы уже научились: Хаффман и обход зигзагом), затем вторые и т. д. Такой трюк полезен при медленном интернете, так как сперва загружаются только DC коэффициенты, по которым строится грубая картинка c «пикселями» 8x8. Затем округленные AC коэффициенты, позволяющие уточнить рисунок. Затем грубые поправки к ним, затем более точные. Ну и так далее. Коэффициенты округляются, так как на ранних этапах загрузки точность не столь важна, зато округление положительно сказывается на длине кодов, так как для каждого этапа используется своя таблица Хаффмана.
Lossless mode
Сжатие без потерь. DCT нет. Используется предсказание 4-й точки по трем соседним. Ошибки предсказания кодируются Хаффманом. По-моему, используется чуть чаще, чем никогда.
Hierarhical mode
По изображению создается несколько слоев с разными разрешениями. Первый грубый слой кодируется как обычно, а затем только разница (уточнение изображения) между слоями (прикидывается вейвлетом Хаара). Для кодирования используется DCT или Lossless. По-моему, используется чуть реже, чем никогда.
Арифметическое кодирование
Алгоритм Хаффмана создает оптимальные коды по весу символов, но это верно только для фиксированного соответствия символов с кодами. Арифметическое не имеет такой жесткой привязки, что позволяет использовать коды как бы с дробным числом бит. Утверждается, что оно уменьшает размер файла в среднем на 10% по сравнению с Хаффманом. Не распространено из-за проблем с патентом, поддерживается не всеми.
Я надеюсь, что теперь вам понятен алгоритм JPEG интуитивно. Спасибо за прочтение!
UPD
vanwin предложил указать использованное ПО. С удовольствием сообщаю, что все доступны и бесплатны:
- Python + NumPy + Matplotlib + PIL(Pillow). Основной инструмент. Нашелся по выдаче «Matlab free alternative». Рекомендую! Даже если вам не знаком Python, то уже через пару часов научитесь производить расчеты и строить красивые графики.
- JpegSnoop. Показывает подробную информацию о jpeg-файле.
- yEd. Редактор графов.
- Inkscape. Делал в нем иллюстрации, такие как пример алгоритма Хаффмана. Прочитал несколько уроков, оказалось очень здорово.
- Daum Equation Editor. Искал визуальный редактор формул, так как с Latex-ом не очень дружу. Daum Equation — плагин к Хрому, мне показался очень удобен. Помимо мышкотыкания, можно редактировать Latex.
- FastStone. Думаю, его представлять не надо.
- PicPick. Бесплатная альтернатива SnagIt. Сидит в трее, скриншотит что скажут куда скажут. Плюс всякие плюшки, типа линейки, пипетки, угломера и пр.

