
Для пытливых разработчиков до сих пор остается актуальным вопрос использования табуляции и пробелов для форматирования кода. Могут ли они быть взаимозаменяемы: например, 2 пробела на табуляцию или 4? Но единого стандарта нет, поэтому иногда между разработчиками возникает непонимание. Кроме того, различные IDE и их компиляторы обрабатывают табуляцию также по-своему.
Решением вопроса обычно становится соглашение о правилах форматирования в рамках проекта или языка программирования в целом.
Команда разработчиков из Google исследовала проекты в репозитории Github. Они проанализировали код, написанный на 14 языках программирования. Целью исследования было выявить соотношение табуляций и пробелов — то есть, наиболее популярный способ форматирования текста для каждого из языков.
Реализация
Для анализа использовалась уже существующая таблица [bigquery-public-data:github_repos.sample_files], в которую записаны наименования репозиториев Github.
Напомним, что около двух месяцев назад весь открытый код Github стал доступен в форме таблиц BigQuery.
Однако для анализа были выбраны не все репозитории, а только верхние 400 тысяч репозиториев с наибольшим числом звёзд, которые они получили за период с января по май 2016 года.
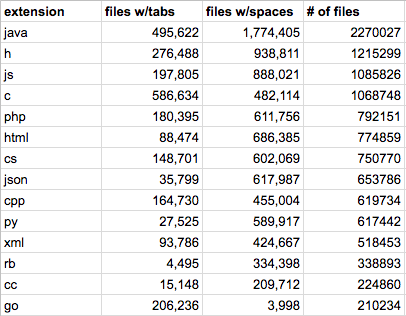
Из этой таблицы были выделены файлы, содержащие код на 14 самых популярных языках программирования. Для этого в качестве параметров sql-запроса были указаны расширения соответствующих файлов – .java, .h, .js, .c, .php, .html, .cs, .json, .py, .cpp, .xml, .rb, .cc, .go.
SELECT a.id id, size, content, binary, copies, sample_repo_name , sample_path FROM ( SELECT id, FIRST(path) sample_path, FIRST(repo_name) sample_repo_name FROM [bigquery-public-data:github_repos.sample_files] WHERE REGEXP_EXTRACT(path, r'\.([^\.]*)$') IN ('java','h','js','c','php','html','cs','json','py','cpp','xml','rb','cc','go') GROUP BY id ) a JOIN [bigquery-public-data:github_repos.contents] b ON a.id = b.id
864.6s elapsed, 1.60 TB processed
Запрос выполнялся довольно долго. И это неудивительно, так как было необходимо выполнить операцию объединения (join) таблицы из 190 миллионов строк с таблицей в 70 миллионов строк. Всего было обработано 1,6 ТБ данных. Результаты запроса доступны по этому адресу.
В таблице [contents] записаны файлы без своих дубликатов. Ниже указано общее количество уникальных файлов и их суммарный размер. Дубликаты файлов не учитывались в ходе анализа.

После этого оставалось только сформировать и запустить на выполнение финальный запрос.
SELECT ext, tabs, spaces, countext, LOG((spaces+1)/(tabs+1)) lratio FROM ( SELECT REGEXP_EXTRACT(sample_path, r'\.([^\.]*)$') ext, SUM(best='tab') tabs, SUM(best='space') spaces, COUNT(*) countext FROM ( SELECT sample_path, sample_repo_name, IF(SUM(line=' ')>SUM(line='\t'), 'space', 'tab') WITHIN RECORD best, COUNT(line) WITHIN RECORD c FROM ( SELECT LEFT(SPLIT(content, '\n'), 1) line, sample_path, sample_repo_name FROM [fh-bigquery:github_extracts.contents_top_repos_top_langs] HAVING REGEXP_MATCH(line, r'[ \t]') ) HAVING c>10 # at least 10 lines that start with space or tab ) GROUP BY ext ) ORDER BY countext DESC LIMIT 100
16.0s elapsed, 133 GB processed
Анализ каждой из строк 133 Гб кода занял 16 секунд. Добиться такой скорости помог все тот же BigQuery.
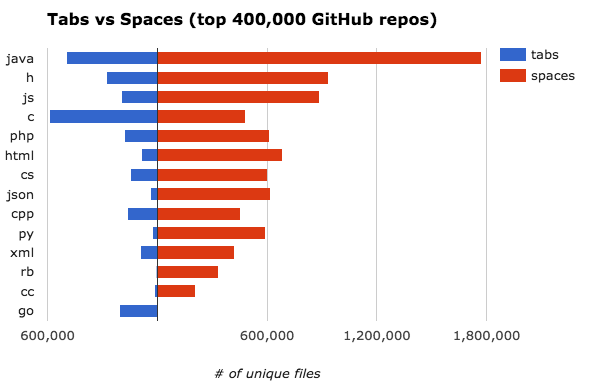
Чаще всего табуляция встречается в языке С, а пробелы — в Java.
Хотя для кого-то соотношение тех или иных управляющих символов не имеет значения, а споры на эту тему кажутся надуманными. Это не имеет значения и для некоторых IDE, которые сохраняют табуляцию как некоторое количество пробелов. Также существуют IDE, в которых это количество можно настраивать вручную.
Некоторое время назад эта проблема была обыграна в сериале «Кремниевая долина». Парень и девушка не сошлись в вопросе форматирования. В результате старый холивар не только привел к недопониманию в профессиональном плане, но и создал проблемы в их личных отношениях.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Табы или пробелы?
58.28%14 ТБ кода? А могло бы быть 5ТБ, если бы там были табы, а не пробелы.1752
41.72%Ваши табы неясно показываются и отъедают место на экране, лучше пробелы.1254
Проголосовали 3006 пользователей. Воздержались 429 пользователей.

