
По сути это история розыска дефекта вёрстки банковского сайта, приведшего к неточному отображению его главной страницы на поиске. Подобную проблему часто встречают на сайте, собранном например в онлайновом конструкторе, или свёрстанном например верстальщиком не знакомым с азами поисковой оптимизации.
И эта история так и осталась бы интересной лишь узкому кругу практикующих сеошников, не коснись она одной недокументированной особенности индексации, о которой наверняка захотелось бы узнать и прочим специалистам по обслуживанию сайта. Приглашаю их под кат.
Короткая вводная
Любому опытному SEO-мастеру известны правила семантического разбора страницы сайта поисковыми роботами-индексаторами. Эти правила обусловлены отдельными положениями некоторых технических стандартов сети Интернет. Так, например:
- тег <title> представляет собой уникальное название всего документа и используется только в его заголовочной секции, причём всего лишь раз;
- тег <h1> озаглавливает конкретный раздел документа и может быть использован повторно, но лишь в другом разделе и при сохранении уникальности среди всех тегов <h1> этого же документа;
- тег <h2> — это подзаголовок раздела, который может быть использован повторно даже в том же разделе при соблюдении уникальности среди одноранговых подзаголовков своего раздела;
- тег <h3> — это подзаголовок вышестоящего подзаголовка;
- … и так далее.
Разумеется, в этих правилах разбора страниц, предшествующего их индексации, существуют разные нюансы, интерпретируемые каждым поисковым сервером по-своему:
- групповая связанность соседствующих тегов, то есть какие правые теги считать продолжением «мысли», начатой левым тегом — типичный пример, серия тегов <p> есть фрагмент непрерывного текста;
- разделяющие контуры (outlines), то есть какие теги или разметочные условия всегда завершают текущую «мысль» — типичный пример, тег <h2> после серии тегов <p> есть завершение того фрагмента текста и открытие (оглавление) нового;
- … и так далее.
Нам не суть важны пока что эти правила семантического разбора и нюансы. А если вам так уж интересны те самые положения технических стандартов, на которые опирается индексация контента, то основная часть этих положений достаточно ясно изложена в обзорной публикации [1] о допустимости нескольких тегов <h1> на одной странице сайта.
Я лишь отмечу, что SEO-мастера привыкли к таким нюансам, не первый раз проверили их справедливость на собственном опыте, и давно уже продвигают сайты в поиске с учётом подобного взгляда на приоритетность тегов. Ведь понимание принципов индексации даёт возможность отчасти «управлять» текстом, который покажет поисковый сниппет сайта в ответ на запрос пользователя.
Но вот несколько дней назад появилась инсайдерская информация, что в результатах органического поиска, касающихся официального сайта украинского Монобанка, выявлено непонятное поведение сниппета: поисковик озаглавливает его совсем не по тегу <title> или <h1>. То есть копирайтер мог бы написать самый уникальный заголовок и текст, контент-менеджер мог бы вставить текст на сайт, а в поиске всё равно оказалось бы не то.
Понадобилось разобраться в причине, о чём и расскажу дальше.
Первый шаг исследования
Итак, для начала я очистил кеш и историю браузера, перезапустил его, открыл поисковую строку Google и ввёл название банка. Чтобы даже неискушённому в SEO человеку был понятен каждый мой шаг, я сделал снимок первого действия.
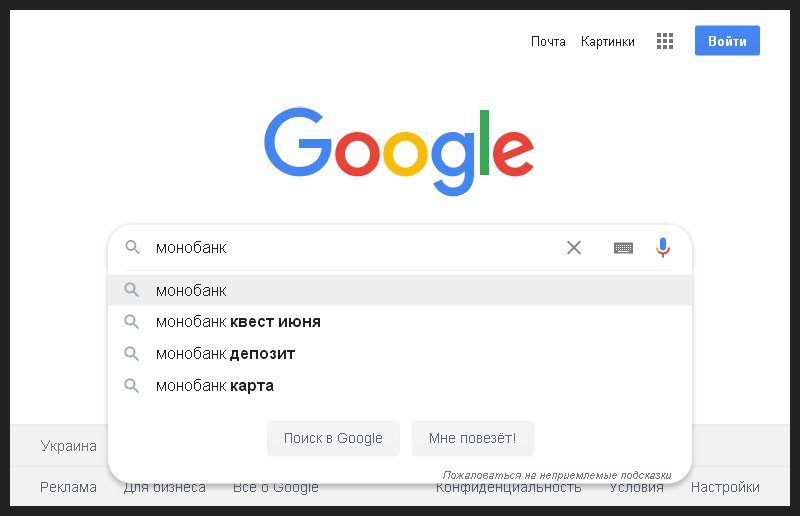
Это брендовый информационный запрос, а значит на первом месте органических результатов логично ожидать появление сниппета для главной страницы банка.
Всё произошло как и ожидалось, сниппет был первым в поиске, ещё и содержал блок быстрых ссылок на основные разделы сайта. Я запечатлел этот момент на следующем снимке.
Пока что всё выглядело нормальным.
С целью убедиться, что неясная ситуация происходит лишь в результатах Google, я повторил тот же запрос в поиске Яндекса и приятно отметил, что этот поисковый гигант придерживается привычных правил: сниппет был озаглавлен monobank — мобiльний банк — точно как записано в теге <title> искомой страницы.

Ответ на снимке поиска Google был принципиально иным, как минимум в части заголовка. Ну и кроме того, меня несколько смутили нелепые текстовки под заголовками гугловского сниппета.
Я предположил, это всего лишь следствие того, что после SMM продвижения бренда и его мобильного приложения, которое выполнила компания Promodo в 2017-2018 годах [2] для прежнего домена monobank.com.ua, нанимать ещё SEO-мастеров на обслуживание нового домена monobank.ua уже не имело смысла. Ведь рекламная кампания принесла ожидаемые плоды. И руководство банка на поисковое продвижение нового домена, скорее всего, вообще забило, или возложили обязанность на штатных айтишников.
Поэтому я списал неуклюжесть нынешних текстовок на вполне понятное нежелание штатных сотрудников проверить результат запроса, который типичный пользователь банка и в самом деле набирать никогда не будет.
Ведь клиентура банка ходит на сайт в большинстве своём через мобильное приложение, практически не наблюдая, как выглядят страницы банка в поиске. А та часть клиентов, которые ходят через интернет-поиск, в основном использует запросы вида:
- курс доллара монобанк;
- курс валют монобанк;
- открыть счет монобанк;
- сделать карту монобанк;
- создать карту монобанк;
- кредитная карта монобанк;
- оформить кредит монобанк;
- взять кредит монобанк;
- … и так далее.
Полный перечень таких поисковых фраз, удовлетворяющих шаблону «что найти + где» или «где + что» и приносящих наиболее жирный входящий трафик из органического поиска, знают в любом банке.
Проверка «вкусных» запросов
Как же я удивился, когда на большинство из подобных запросов в результатах поиска появлялся всё тот же сниппет с неизменным заголовком и часто бестолковой текстовкой, едва ли соответствующей введённому запросу.
Пример такого запроса я сфотографировал на следующем снимке и обозначил проблемное место.
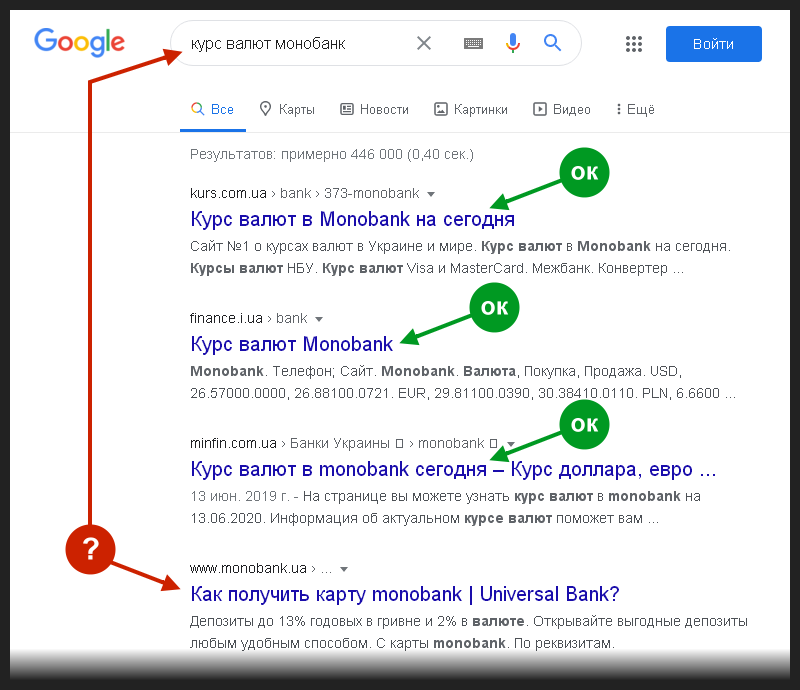
Причём целевой адрес (URL) сниппета почти для всех запросов приводил в начало главной страницы, даже не заякоривая в адресе её раздел, релевантный текущему запросу.
Ну скажем, если запрос был бы о курсе валют и на целевом лендинге присутствовал бы соответствующий раздел, было бы логично заякорить ссылку на раздел каким-нибудь хешем типа monobank.ua/#kurs-valut с канонизацией того же заякоренного URL, чтобы поисковый робот понимал, что лендинг имеет несколько точек посадки для соответствующих поисковых фраз, которые были бы прописаны штатными сеошниками в анкорном тексте ссылок, проставленных ими где-нибудь на сайте или вне сайта, например в соцсетях.
Иначе всё выглядело так, будто разработчики сайта отвели главной странице роль многосекционного лендинга, а обслуживающим сеошникам не сказали, и те ставили продвигающие ссылки с планируемым анкорным текстом, но без якорей разделов. В результате все ссылки для разных видов запросов как бы легли в начальную точку входа главной страницы и неизбежно получили единый сниппет с заголовком, касающимся основного раздела главной страницы.
Небольшое отступление
На всякий случай покажу на следующем снимке пример HTML разметки, как с помощью семантической вёрстки решают вопросы множественных точек посадки на единственный лендинг сайта.

Разумеется, эта схема будет работать при условии, что ссылки на лендинг проставим с якорем, соответствующим информационному случаю. То есть:
- monobank.ua — основные сведения;
- monobank.ua/#kurs-valut — о курсах валют;
- monobank.ua/#otkryt-schet — об открытии счёта;
- monobank.ua/#kreditnaja-karta — о кредитных картах.
Но вернёмся к обнаруженному SEO косяку
Ошибка пусть и не столь серьёзная, ведь основной поток клиентов всё же идёт через мобильное приложение, тем не менее из-за этой ошибки банк теряет часть поискового трафика. Потому что пользователи поиска делятся на 2 вида — спешащее большинство и неторопливое меньшинство:
- первые читают только заголовки сниппетов и щёлкают их, если совпадает смысл заголовка и введённого запроса;
- вторые внимательно читают заголовок и текстовку под ним и тоже щёлкают лишь при совпадении смысла.
Ясно, что смысл сообщения в закостеневшем поисковом сниппете для страницы банка совпадал лишь с очень малым процентом запросов. Нужно было понять, где допущена ошибка.
Просмотр разметки главной страницы
Я открыл главную страницу банка по ссылке из сниппета. В исходном коде этой страницы присутствовал единственный тег <h1>, обычно применяемый для написания основного заголовка страницы, который обычно ещё и попадает в заголовок сниппета.
Вдобавок этот основной заголовочный тег был использован в коде страницы ранее остальных заголовочных <h>-тегов. Так что на первый взгляд всё выглядело не имеющим SEO ошибок.
Я сделал снимок той страницы и пометил на нём положение первых двух заголовочных <h>-тегов.
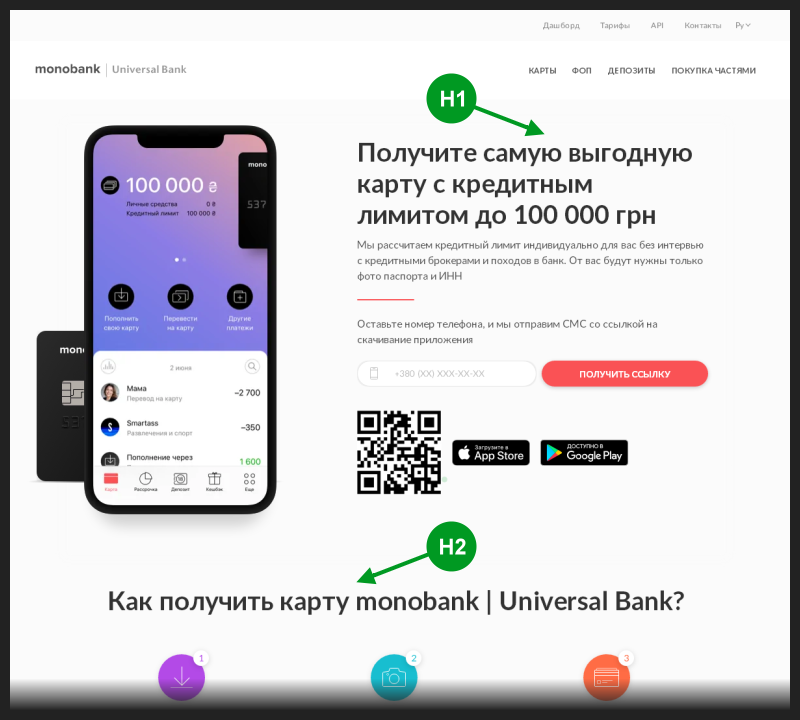
Логично было ожидать, что именно тег <h1> займёт место заголовка поискового сниппета. Но по какой-то причине туда всякий раз попадал тег рангом ниже.
Сначала я предположил, что случай касается лишь запросов, в которые входит название банка. В теге <h1> его нет, а в теге <h2> есть — поэтому тот тег, несмотря на меньший ранг, всё же получает преимущество занять заголовок сниппета.
Однако это предположение легко проверить: надо написать запрос в точности равный тегу <h1>, и тогда этот заголовочный тег гарантированно получит право занять заголовок сниппета на основании абсолютного соответствия запросу. Что я и сделал, одновременно зафиксировав результат на следующем снимке.

Из снимка следует, что поисковый сервер всё же видит и понимает текст тега <h1>, только главным заголовочным его почему-то не считает на сайте этого банка. Такое возможно в 2 случаях:
- либо SEO-мастер добавил в вёрстку страницы конкретную семантическую микроразметку, предписывающую другому тегу стать главным заголовочным;
- либо присутствует так называемая «проблема онлайновых конструкторов», когда в силу поисковой неоптимальности строительных блоков их текстовые теги оказываются в разных разделах HTML-документа, притом основной заголовочный тег опущен по уровням вложенности контуров глубже, чем неосновной заголовочный тег от контура своего раздела.
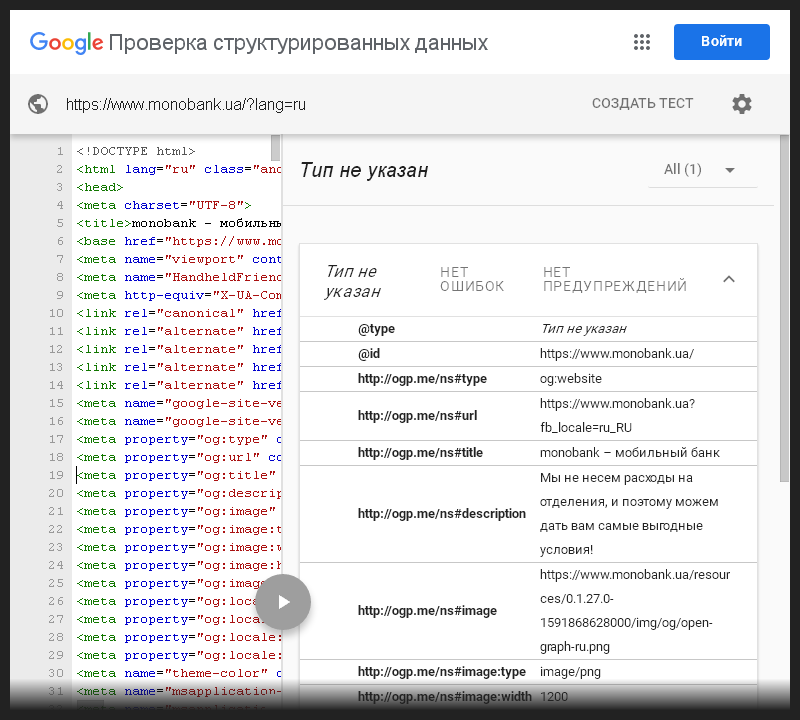
Я решил сначала проверить первый случай и открыл сайт в инструменте проверки структурированных данных. Однако была обнаружена только микроразметка Open Graph, никаких намёков на принудительное переназначение семантики тегов.
Я зафиксировал этот момент на следующем снимке.
Тогда я открыл исходный код проблемной страницы, для удобного изучения отформатировал пробелы, ещё с той же целью убрал атрибуты тегов, и затем отметил суть проблемы на следующем снимке.

В итоге имеем истолкованное ниже состояние дел, из которого заранее запишу важный вывод: по истечении месяца (это примерно среднее время обхода роботами-индексаторами) от запуска сайта обязательно проверьте по нескольким ключевым запросам, как поисковик воспринял разметку ваших страниц, то есть какие именно части контента он проиндексировал на самом деле.
Толкование результата
Яндекс при разборе страницы на новом домене Монобанка не нашёл семантическую вёрстку (так как всё свёрстано <div>-ами), и не имея предписаний анализировать неявную семантику не стал гадать по классам тегов, а при подборе заголовка сниппета просто воспользовался правилом из спецификации: тег <title> — главнейший заголовок документа.
Google при разборе той же страницы тоже не нашёл семантическую вёрстку, но его искусственный интеллект способен анализировать скрытые семантические признаки, поэтому заметил четыре <div> с неявным семантическим классом content, обозначающим контур раздела в сложившейся разметочной ситуации. Следовательно, правило о теге <title> было отвергнуто, и поисковик воспользовался правилом из спецификации о контурах разделов, пытаясь найти подходящий раздел из четырёх заявленных. Первый раздел не подходит, так как его заголовочный тег дальше от контура, чем заголовочный тег в разделах 2, 3 и 4. Из этих более подходящих разделов был выбран второй раздел на основании его близости к началу документа. Вот так его заголовок и попал в сниппет.
По факту, логика выбора заголовка для сниппета была идентичной у обоих поисковиков. Просто Яндекс выбирал первый заголовочный тег из первого контура (им неявно выступает тег <head>) в документе, а Google — первый заголовочный тег из семантически отмеченного контура (им явно выступил тег <div class=«content»>).
Вот это и есть та удивительная особенность поиска, названная «недокументированной» в начале моего расследования. Тег <h1> в самом деле не имеет какой-либо знаковой важности. Исходя из поискового запроса пользователя, подбирается согласующийся контур раздела в документе и первый заголовок в контуре, не принимая в расчёт употреблённый числовой уровень заголовка.
Использованные материалы
[1] Один H1 или несколько — почему правильно именно так?, Март 2020. Impera, SEO Documents. По выдержкам из спецификаций стандарта HTML показано, что написание одного или нескольких тегов H1 на странице в обоих случаях считается правильным.
[2] Кейс Monobank по продвижению мобильного приложения, Август 2017 — Март 2018. Promodo, Cases. На примере использованных агентством мероприятий рассказано как продвигали мобильное приложение на iOS и Android с помощью AdWords, Facebook, Instagram, Twitter, YouTube, а также оптимизировали в App Store и Google Play.
