Как-то понадобилось интегрировать Open vSwitch (OVS) c Р-виртуализацией плюс Р-хранилище(РП), может пригодится и не только с РП.
Текущая версия РП на момент статьи была 7.0.13-31, ядро в этой версии 3.10.0-1062.12.1.rv7.131.10.1, что соответствует версии RedHat 7.7, а версия OVS, который идет в составе репозитория РП была 2.0.0. Список функционала на OVS 2.0.0 можно посмотреть тут. Ключи для РП можно взять тут.
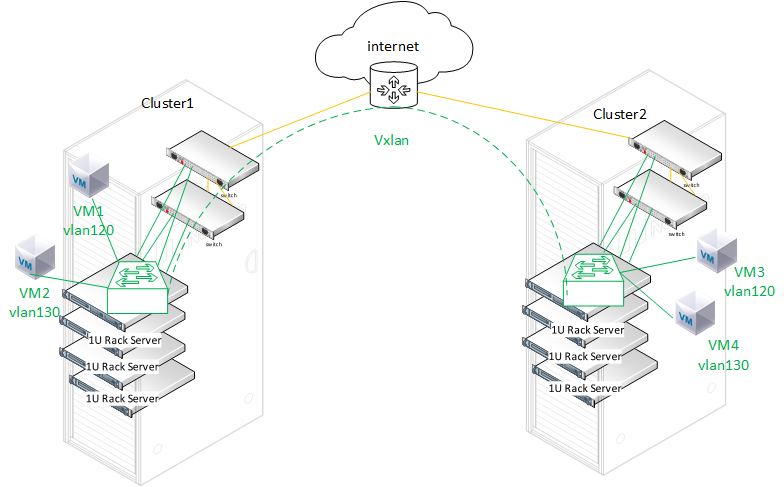
Цель была попробовать настроить VXLAN и виртуальный коммутатор в качестве альтернативы родным к технологии kvm-qemu и libvirt мостам. Если использовать голый OpenSource kvm-qemu, то там с OVS все в порядке, но захотелось это попробовать с РП, где не просто голый kvm-qemu+libvirt, а много патчей к этой связке и есть vstorage.
Железо
Для этого конечно нам понадобится железо. Минимальные требования РП это три сервера в каждом по три диска, можно конечно и два если все SSD, но в моем случае один SSD остальные HDD. Далее сеть не менее 10 гигабит два порта, в моем случае повезло было 20 гигабит два порта и дополнительный порт 5 гигабит для ввода в кластер тегированного трафика для OVS в обход классическим мостам или другими словами параллельное использование классических мостов Р-виртуализации с OVS. В общем в моем случае повезло в наличии был Synergy c 3 лезвиями, корзинами с JBOD дисками и встроенным коммутатором.
Развертывание РП
Краткая инструкция по установке:
- Устанавливаем первую ноду, в анаконде назначаем IP хосту и из этой же подсети виртуальный IP для управления Р-виртуализации, и IP для управления Р-хранилищем. Дисков как минимум должно быть 3, один для хоста (ОС/гипервизор) в моем случае HDD, второй и третий диск уже настроим через управление Р-хранилищем, где один SSD под кэш и другой под чанк сервер. На втором интерфейсе назначаем IP из другой подсети для сети хранения без шлюза.
- После установки заходим через браузер хром по IP адресу управления Р-хранилищем, далее выбираем раздел серверы и нажимаем на вопросик с прямоугольником, и выбираем раздел сеть, в нем назначаем роли для интерфейса с адресом подсети управления(роли ssh, управление, web cp) и для интерфейса с подсетью для хранения назначаем роли (ssh, хранилище).
- Далее нажимаем создать кластер вводим его имя автоматом должен подключится интерфейс с ролью хранения и выбрать подробные настройки, убедится что система правильно распределила роли на дисках, один должен быть системный, другой служба метаданных плюс кэш если это SSD и далее третий диск HDD в роли хранения (чанк сервер).
- Параллельно с установкой первой ноды можно устанавливать две последующие, назначить каждой по два IP адреса один для подсети управления Р-виртуализации, на втором интерфейсе из подсети хранения. Если оставить поля регистрации на сервере управления Р-виртуализации и управления Р-хранилище пустыми то, можно продолжить установку без указания IP адресов управления, а регистрацию выполнить потом.
- После того как последующие ноды установлены пройти по IP адресу этих хостов через ssh в cli и выполнить регистрацию, где IP это адрес управления Р-хранилищем и токен можно скопировать с веб управления р-хранилищем при нажатии добавить ноду.
- После того как обе ноды появятся в веб управлениии Р-хранилище выполнить те же действия что в пункте 2-3 только вместо создания кластера выбрать присоединить.
- Далее после создания кластера появится пункт сервисы в нем создать хранилище датастор в зависимости наличия дисков и узлов можно делать реплику 2 или 3 и т.д. если узла 3 то, реплика 2, остальное все по умолчанию.
- Далее проходим по IP адресу управления Р-виртуализации нажимаем добавить если физ. сервер если не добавлен и добавляем остальные, далее устанавливаем триал лицензию, далее в настройках хоста выполнить “Изменение настроек хоста для виртуальных сред” выбрать вместо локальной папки по умолчанию можно для всех пунктов(для первого раза лучше так) выбираем наш датастор который создавали в Р-хранилище и ставим галочку применить на все хосты.
- После это мигрируем vstorage-ui и va-nm на любой другой хост, время может занять некоторое потому что это миграция с локальных носителей на кластерные.
- После этого открываем ssh консоли всех трех узлов и вводим команду включения HA на каждом узле, где IP адрес сети хранения, после этого необходимо проверить командой #shaman stat.
- После этого можно приступать к созданию ВМ, где я в качестве гостевой установил CentOS 7.
команда регистрации ноды к выше описанному пункту 5:
#/usr/libexec/vstorage-ui-agent/bin/register-storage-node.sh -m 10.43.10.14 -t ec234873
комнда включения HA к пункту 10:
#hastart -c имя кластера -n 192.168.10.0/24
и проверка HA, где вывод должен быть примерно такой:
[root@n3 ~]# shaman stat Cluster 'rptest' Nodes: 3 Resources: 7 NODE_IP STATUS ROLES RESOURCES 192.168.10.10 Active VM:QEMU,CT:VZ7 0 CT, 0 VM 192.168.10.11 Active VM:QEMU,CT:VZ7 0 CT, 0 VM *M 192.168.10.12 Active VM:QEMU,CT:VZ7 2 CT, 0 VM
Установка и настройка OVS
На первой и третей ноде кластера были установлены OVS следующей командой:
#yum install openvswitch
После установки можно проверить командой
#ovs-vsctl show
Вывод будет примерно следующий:
[root@node1 ~]# ovs-vsctl show 180c5636-2d3d-4e08-9c95-fe5e47f1e5fa ovs_version: "2.0.0" [root@node1 ~]#
Далее необходимо создать мост виртуального коммутатора на который и будем вешать порты, интерфейсы или другие мосты.
# ovs-vsctl add-br ovsbr0
Имя моста назовем так чтобы было понятно, что это экземпляр одного виртуального коммутатора.
Далее можем создать тегированный мост для добавления к определенной ВМ.
#ovs-vsctl add-br brlv140 ovsbr0 140
Тег при этом может быть не привязан к какому-то реальному тегу с физического порта, это только в рамках виртуального коммутатора.
Далее назначаем его ВМ к виртуальной сети, где предварительно создаем xml файл:
<network> <name>ovsvl</name> <forward mode='bridge'/> <bridge name='brlv140'/> <vlan> <tag id='140'/> </vlan> <virtualport type='openvswitch'/> </network>
К сожалению веб ui Р-управления пока не поддерживает настройки с OVS, но их можно сделать через cli. Для создания и добавления виртуальных сетевых адаптеров к ВМ я воспользовался веб ui, но далее уже через cli подменил привязку этих адаптеров к ovsvl и ovsvl2 вместо Bridged. Главное потом не забыть, что изменения в сетевые настройки оборудования ВМ уже вносить через cli иначе веб ui не зная про OVS вернет Bridged.
Для просмотра существующих сетей используем команду:
#virsh net-list --all
Для добавления нашей сети:
#virsh net-define ovsvl.xml
Далее необходимо ее запустить/активировать
#virsh net-start ovsvl
И прописать в автостарт
#virsh net-autostart ovsvl
Далее необходимо добавить эту сеть к ВМ
#virsh edit имяВМ
Находим необходимые строки с интерфейсами, редактируем их или добавляем свои по аналоги существующих меняя мак адрес и номер порта(слот):
<interface type='bridge'> <mac address='00:1c:42:c6:80:06'/>
<vlan> <tag id='140'/> </vlan> <virtualport type='openvswitch'> <parameters interfaceid='5a70be5b-5576-4734-9f61-61cdfc4a884a'/> </virtualport> <target dev='vme001c42c68006'/> <model type='virtio'/> <boot order='2'/> <alias name='net0'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/> </interface>
Редактирование осуществляется командами редактора vi
Далее после редактирования необходимо выключить и запустить ВМ для применения текущих настроек:
#prlctl stop имя ВМ
#prlctl start имя ВМ
Для проверки можно ввести команду:
#virsh dumpxml имяВМ | grep имясети
После этого можно приступать к настройкам сети изнутри гостя ВМ или добавить сетевые порты в коммутатор для связи с другим кластером по VXLAN overlay:
#ovs-vsctl add-port ovsbr0 vxlan0 -- set Interface vxlan0 type=vxlan options:remote_ip=10.43.11.12
где IP адрес это адрес той ноды на которой произведены такие же настройки как показано выше. Прямая связь между этими адресами может быть, как через роутеры, так и через VPN, и из разных подсетей, главное, чтобы между ними был настроен маршрут. Но еще главнее, чтобы интерфейс физического порта на котором назначен это адрес, был настроен MTU больше чем 1500 для пропускания пакетов с большим размером, так как vxlan добавляет свои данные, заголовок в несколько байт, но я не стал заморачиваться считать все байты и просто назначил 2000.
Например:
#ip link set mtu 2000 dev ens3f0
сам мост зависящий от этого интерфейса тоже должен быть с mtu2000, но он может не сразу его наследовать и возможно понадобиться его перезапустить.
На стороне второго кластера выполнить на ноде с адресом 10.43.11.12 как описано выше те же настройки только в vxlan назначить адрес ноды первой настройки в моем случае
#ovs-vsctl add-port ovsbr0 vxlan0 -- set Interface vxlan0 type=vxlan options:remote_ip=10.43.11.10
Далее также настроить mtu.
Если у вас все правильно настроено то, пойдут пинги и возможно делать подключения по ssh, если предварительно например, изнутри ВМ задать адреса из одной подсети. Если выполнить анализ сети:
#tcpdump –i ens3f0 | grep 4789 ``` то можно увидеть пакеты с vxlan или c тегами vlan ```bash #tcpdump -ee -vvv -i ens3f0 | grep vlan
Далее можно настроить более удобный вариант настройки сети без мостов через функционал виртуального коммутатора portgroup.
Для этого необходимо создать xml сети со следующим:
<network> <name>ovsvl2</name> <forward mode='bridge'/> <bridge name='ovsbr0'/> <virtualport type='openvswitch'/> <portgroup name='vlan-120'> <vlan> <tag id='120'/> </vlan> </portgroup> </network>
Можно создать новую сеть или отредактировать предыдущую с этими параметрами, но в моем случае добавляю еще одну сеть.
Как описано выше, а в ВМ уже следующим образом:
<interface type='bridge'> <mac address='00:1c:42:c8:f1:cd'/>
<vlan> <tag id='120'/> </vlan> <virtualport type='openvswitch'> <parameters interfaceid='ef717aa4-23b3-4fbe-82bb-193033f933b1'/> </virtualport> <target dev='vme001c42c8f1cd'/> <model type='virtio'/> <boot order='3'/> <alias name='net1'/> <address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/> </interface>
Далее сохранить и перезапустить ВМ как описано выше, а на одном из виртуальных коммутаторов можно добавить транковый порт с определенными тегами от физического порта, то есть предварительно с подключенным на один из физических портов сервера с транковым тегированным трафиком от физического коммутатора.
В моем случае:
#ovs-vsctl set port ens3f4 trunks=120,130 #ovs-vsctl add-port ovsbr0 ens3f4
И можно добавить порт с тегом 120 для ВМ:
#ovs-vsctl add-port ovsbr0 vlan120 tag=120 -- set interface vlan120 type=internal
На стороне другого виртуального коммутатора на другой ноде другого кластера, где нет транка от физического коммутатора добавить точно также этот порт то есть:
#ovs-vsctl add-port ovsbr0 vlan120 tag=120 -- set interface vlan120 type=internal
Плюс добавить сеть как описано выше.
Пример вывода настроек OVS и ВМ
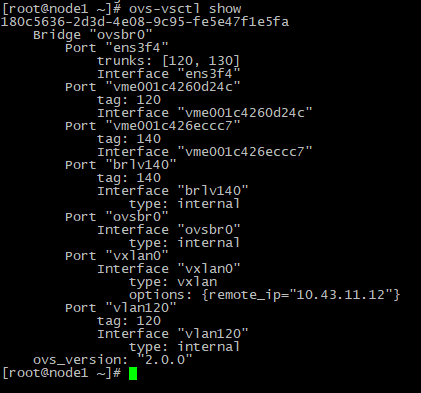
Вывод команды #ovs-vsctl show на первой ноде. Порты и интерфейсы с именем начинающимся с vme являются виртуальными интерфейсами ВМ, которые автоматически попадают в конфиг при запуске ВМ подключенному к OVS.
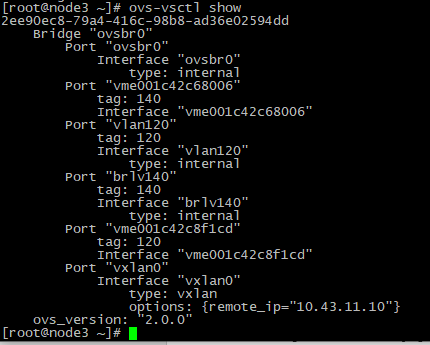
Вывод команды #ovs-vsctl show на третей ноде
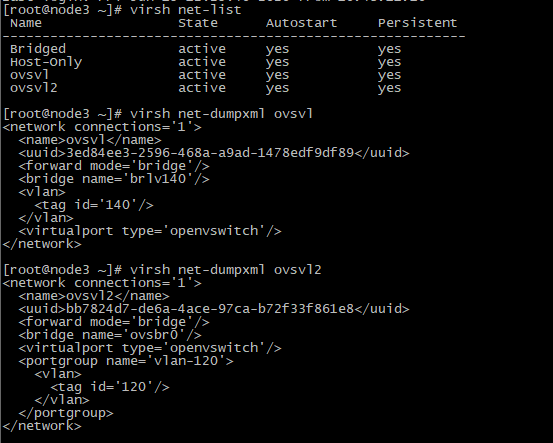
Вывод команды virsh net-list содержит 4 вида сети, где Bridged и Host-Only это стандартные классические варианты от Р-виртуализации по дефолту, а ovsvl и ovsvl2 это то, что мы добавили по инструкции выше. Ovsvl получается для варианта с тегированным мостом tag 140 поверх моста OVS, а ovsvl2 это вариант с группой портов portgroup состоящей из одного порта с tag 120. Portgroup очень удобен и в него можно добавлять больше одного порта используя только одну сеть вместо большого количества сетей в классическом варианте Р-виртуализации с мостами под которыми разные VLAN интерфейсы. Далее вывод команды #virsh net-dumpxml ovsvl и ovsvl2 показывающие содержимое настроек этих сетей.
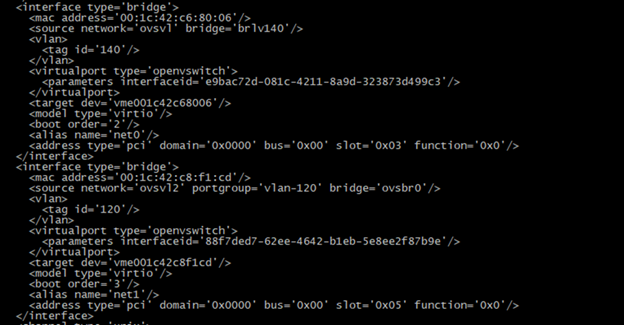
Здесь кусок конфига ВМ, где сетевые интерфейсы по команде:
#virsh dumpxml имяВМ
Тесты
При тестировании OVS была проверена совместимость с запущенным networkmanager(NM), выше описанные сценарии работают нормально, но при автозапуске службы NM может выдавать сообщения по интерфейсам виртуального коммутатора, которыми не может управлять, NM можно выключить, но на функциональность сети это не влияет.
Еще имеются дополнения для управления OVS через NM, но в этом случае функционал OVS ограничен. Поэтому возможна параллельная работа, либо с отключением NM при необходимости.
Также были успешно проверены живые миграции ВМ с сетями от OVS, если на каждой ноде имеется экземпляр сети вместе с OVS то, проблем с миграцией нет, так же как и в стандартной конфигурации кластера Р-виртуализации с дополнительными сетями для ВМ.
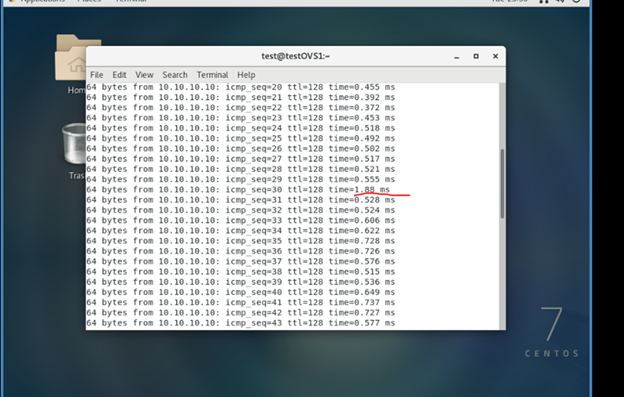
На рисунке выше был запущен ping изнутри ВМ в сторону ВМ из внешней сети и выполнена живая миграция ВМ с одной ноды с установленным OVS на другую ноду с установленным OVS, красным помечена задержка во время этой миграции ВМ. Параметры ВМ были следующие 4 vCPU, 8GB RAM, 64GB disk.
Точно такая же задержка происходит и в классике с мостами, то есть для ВМ ничего не поменялось, а сетевой стек теперь работает через OVS.
По мимо этого производились успешные подключения по ssh с разными ВМ расположенными на разных нодах между туннелем vxlan и с ВМ за физическим коммутатором. Для проверки работы выключали туннель или анализировали пакеты через tcpdump как описано выше. Если не назначить MTU как описано выше то, будут проходить только ping, а через ssh не получится подключится.
Описание сценариев
Ниже показан стандартный классический с мостами вариант настройки кластера из трех нод Р-виртуализация плюс Р-хранилища без OVS.
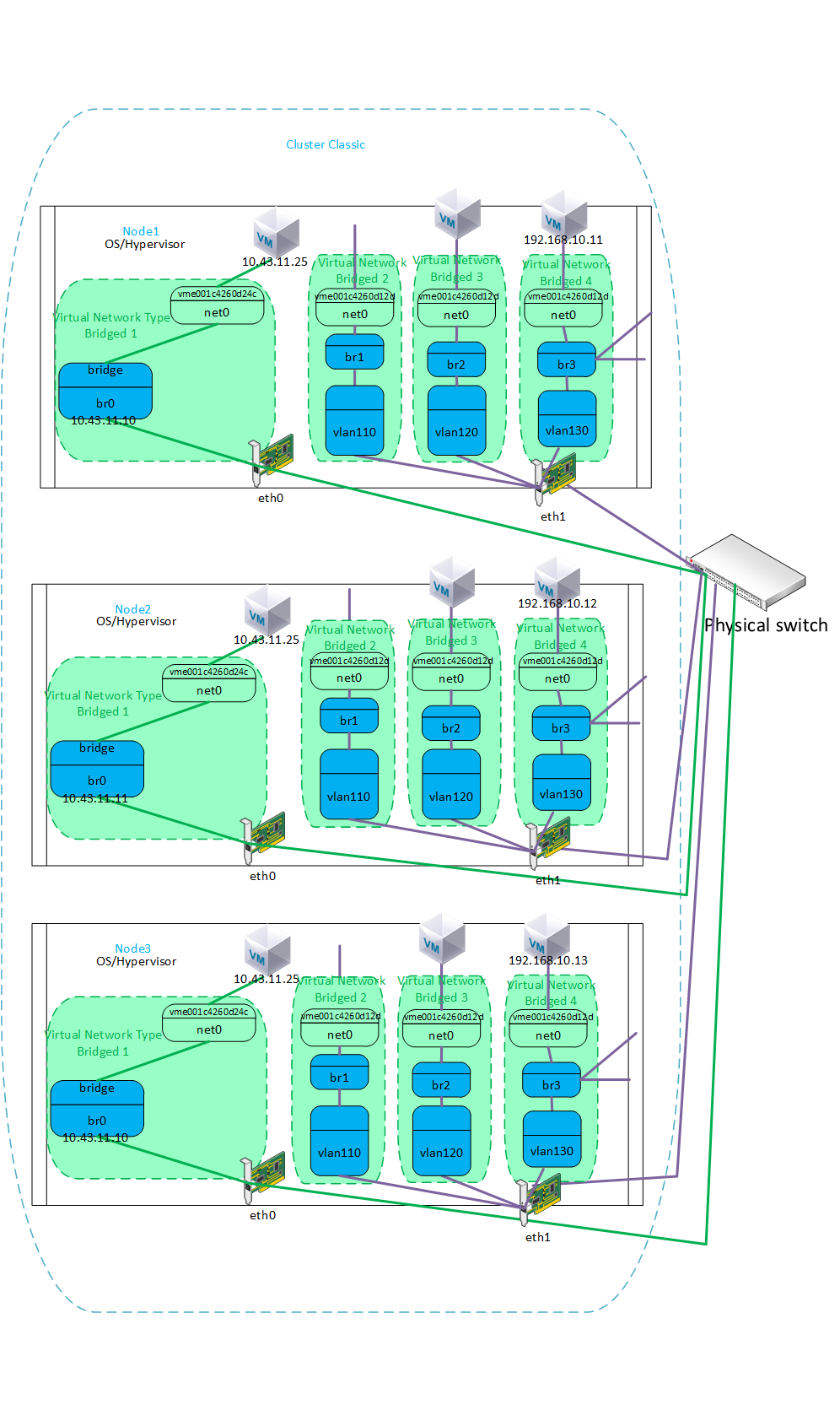
На схеме опущена и не показана сеть Р-хранилища, она обычно идет отдельным интерфейсом предназначенного только для блочного уровня и в этом тесте не участвует. Ее можно настраивать без мостов, и как вариант ее тоже можно задействовать через OVS. Например настроить на OVS агрегацию для Р-хранилища.
Далее схема с использованием вместе с мостами OVS.
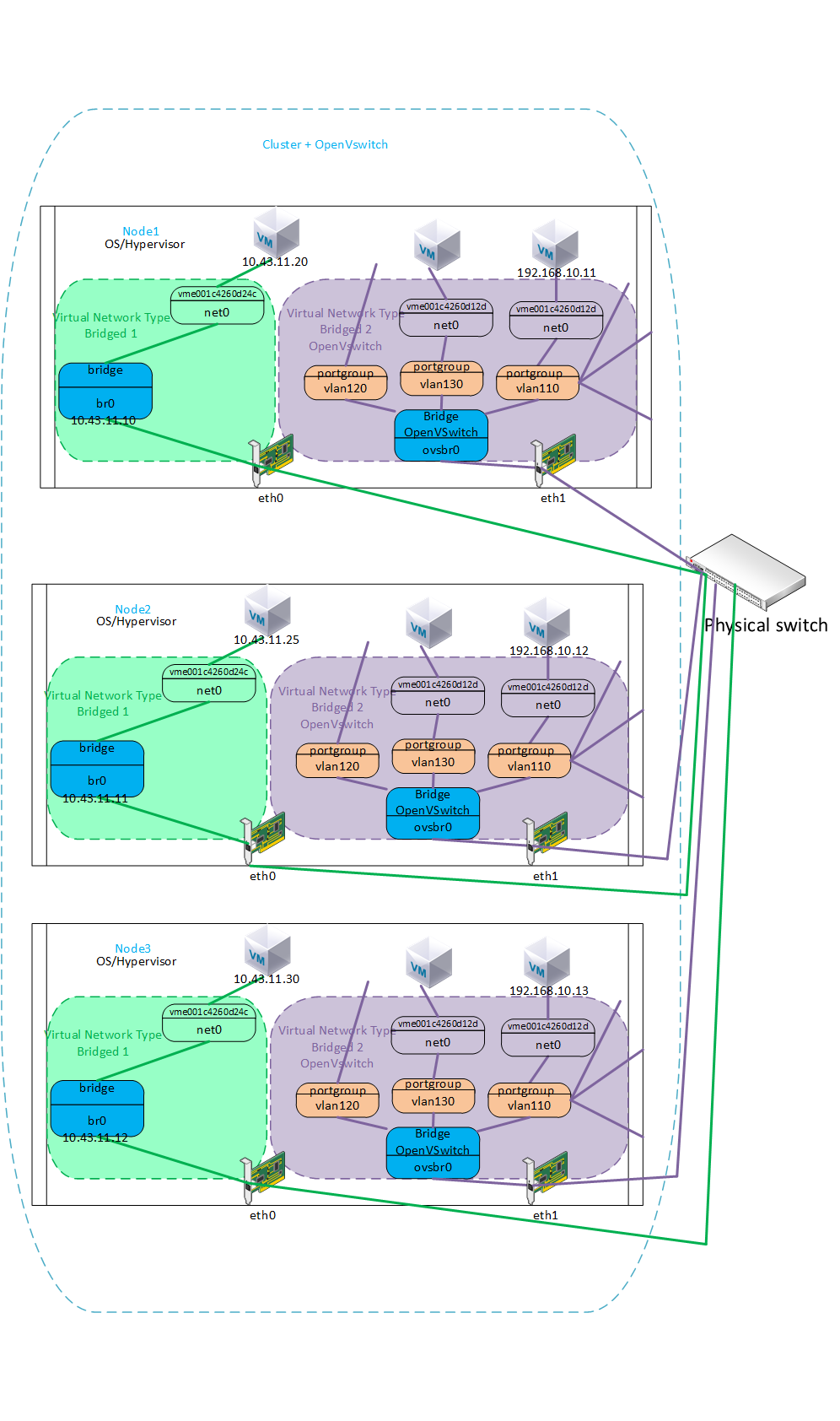
Тут уже может быть одна сеть с OVS и одна с мостом. С OVS можно добавлять порты с разными тегами в portgroup и выводить уже на разные ВМ.
Если вернемся к тестируемому сценарию то, его можно увидеть на следующей картинке:
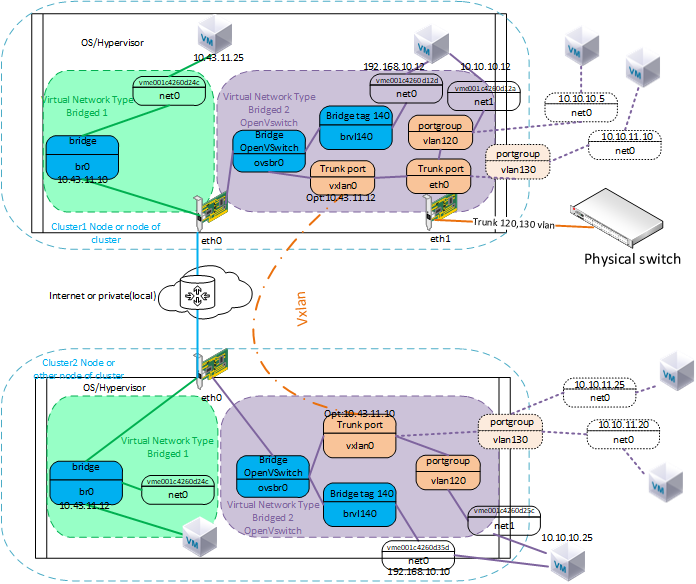
В моем случае было в рамках одного кластера, но это может быть и между разными кластерами за счет туннелей vxlan. Попытаемся представить себе, что это ноды двух разных кластеров.
Туннель поднят на специально выделенном порту одного из серверов каждого кластера. Через туннель выполняется проброс определенного vlan120 в котором определенное количество ВМ со всего кластера рассчитанное на ширину пропускного канала, где средствами OVS можно определить QoS для трафика каждой ВМ. Локальные ВМ этого узла видны через локальный OVS, а ВМ с других узлов видны через физический коммутатор каждого кластера.
Отказоустойчивость OVS обеспечивается за счет добавления в скрипт службы HA(shaman) команд по перебросу туннеля vxlan на другую ноду с OVS, которая будет выбрана по дефолтному алгоритму drs,round-robin за счет службы shaman от Р-Хранилища.
Отказоустойчивость и балансировку порта сервера можно обеспечить за счет агрегации bonding в режиме LACP(802.3ad) c хэшированием layer2+3 или layer3+4, которую также можно настроить средствами OVS.
Как работает классический br0 я описывать не буду, ovsbr0 работает со IP стеком ОС, который на этой картинке определен для br0, то есть экземпляр виртуального коммутатора в виде ovsbr0 работает в данном случае через br0. Другими словами статический IP адрес ноды назначен на классический br0 и весь трафик, который направлен в эту подсеть с виртуального коммутатора проходит через br0, так же как это работает для всех приложений этой ноды. С точки зрения настройки в этом случае никаких cli назначений на br0 со стороны виртуального коммутатора не производилось кроме настройки vxlan интерфейса с option, соответственно если у ноды есть второй классический br1 c другим IP адресом и подсетью висящий на другом физическом порту например eth2 или eth3 то, с виртуального коммутатора за счет стека ОС и его таблицы mac-ов можно направить пакеты в эти подсети назначив какой либо порт виртуального коммутатора в эту подсеть и подключить к ВМ, адрес подсети будет непосредственно назначаться внутри ВМ или в ее настройках.
Благодаря такому принципу виртуальный коммутатор работает как обычная программа на хосте через его сетевой стек не мешая классическим мостам, но конечно при условии что вы не сконфигурируете одинаковые настройки на обоих инструментах (на мостах и OVS).
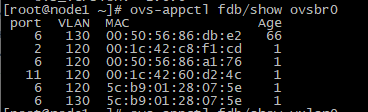
У виртуального коммутатора есть своя таблица маков
У каждого созданного мною виртуального коммутатора есть какой-то набор интерфейсов (разрешая влан на каком-то интерфейсе мы добавляем порт в определенный виртуальный коммутатор), а также таблица соответствия mac адресов и портов (ее мы смотрим командой ovs-appctl fdb/show ovsbr0). Ручное назначение мак адресов внутри коммутатора не производилось. Portgoup это группа портов в которой на данный момент есть порт vlan120 к которому подключена ВМ.
Теоретически мы можем представить, что когда в какой-то порт коммутатора прилетает фрейм с VLAN тегом, то решение о дальнейшей отправке фрейма принимается на основании таблицы mac адресов соответствующего виртуального коммутатора. Если получен фрейм с тегом 120, то соответственно приниматься решение о форвардинге данного фрейма будет на основании mac таблицы виртуального коммутатора с тегом 120.
Что касаемо VXLAN то, в этом случае static (Unicast). Самый простой вариант — это статичное указание удаленных интерфейсов по типу vxlan. Все сводится к тому, что в конфигурации VNI(vlan vxlan) надо статически задать адреса всех удаленных интерфейсов vxlan, которые терминируют клиентов в указанном VNI. В таком сценарии vxlan будет указывать в IP заголовке как адреса назначения — адреса указанных вручную vxlan. Естественно, если vxlan-ов будет больше двух, то точек назначения пакета при флуде будет уже как минимум две. Указать в IP заголовке нескольких получателей не получится, поэтому самым простым решением будет репликация VxLAN пакета на исходящем интерфейсе vxlan и отправка их юникастом на удаленные интерфейсы vxlan, указанные в конфигурации. Получив данный пакет, удаленный vxlan его декапсулирует, определяет какому VNI данный пакет относится и далее рассылает его во все порты в данном VNI. Помимо этого, так как мы все в курсе, что mac адреса изучаются коммутаторами на основании поля source mac, то после декапсуляции VxLAN пакета интерфейс vxlan ассоциирует mac адрес, указанный как исходящий в оригинальном ethernet заголовке с тоннелем до интерфейса vxlan, от которого данный пакет получен. Как и было сказано ранее — VxLAN тоннель коммутатор воспринимает как простой транковый порт.
Минусы данного подхода очевидны — это увеличенная нагрузка на сеть, так как BUM трафик реплицируется на исходящем интерфейсе vxlan и юникастом рассылается всем указанным в конфигурации нейборам, плюс к этому при добавлении или удалении интерфейса vxlan придется править конфиги на всех остальных интерфейсах vxlan-ах и руками удалить или добавить нейбора (нейборов) или в авторежиме средствами скриптов шамана в случае аварии узла. В век автоматизации конечно как-то странно использовать статическое указание нейборов. Но все равно данный подход имеет право на жизнь, например OVS умеет работать только со статически заданным нейбором, во всяком случае на данный момент.
Для работы данного режима необходимо только наличие связности между лупбеками всех интерфейсов vxlan.
Static (Unicast) VxLAN — проста как валенок и безотказна, как автомат Калашникова. Ломаться тут нечему.
здесь все более подробно описано по определению маков и flood&Learn в OVS.
Заключение
При выполнении настроек OVS понравилась простота, удобство, сразу чувствуется что работаешь с коммутатором, а не просто с мостами))) В общем есть смысл его использовать хотя бы параллельно с классическими мостами в РП.
Перед выше описанной интеграцией по мимо использованных в ней ссылок изучал еще следующие статьи:
- https://www.sidorenko.io/post/2018/11/openstack-networking-open-vswitch-and-vxlan-introduction/
- https://blog.remibergsma.com/2015/03/26/connecting-two-open-vswitches-to-create-a-l2-connection/
- http://mx54.ru/nastrojka-setevyx-interfejsov-v-kvm-dlya-virtualnyx-mashin/
- https://kamaok.org.ua/?p=2677
- https://kashyapc.fedorapeople.org/virt/add-network-card-in-guest.txt
- https://costiser.ro/2016/07/07/overlay-tunneling-with-openvswitch-gre-vxlan-geneve-greoipsec/#.XuZ960UzaM_

