Последние несколько лет я занимаюсь дата-инженерингом: строю пайплайны разного уровня сложности, добываю данные, нужные бизнесу, преобразую их и сохраняю, в общем, строю классические ETL.
В этом деле проблем можно ждать откуда угодно и на каждом шаге: источник данных прилег, данные пришли битые, источник без объявления войны поменял формат данных или доступ к ним, хранилище тупит, данных внезапно стало меньше или больше и много других приколюх.
Чтобы понять, как все это мониторить, давайте разберемся кто вообще работает с данными, которые мы с таким трудом намайнили:
Бизнес - это все те люди, которые не особо разбираются в инженерии, но принимают важные решения, основываясь на добытых нами данных: увеличить ли расходы на рекламу, как быстро увеличивать размер аудитории для раскатывания апдейта, как работают различные партрнеры и т.п.
Технари - это мы, инженеры, можем запустить руки в логи, доработать логику, следим, чтобы ничего не падало без острой необходимости.
Код - запускается следующий в цепочке пайплайн, происходят преобразования, рисуются графики и т.п.
Дата-пайплайны могут слегка отличаться от классического бэкенда - если упал какой-то из пайплайнов, это не значит, что все плохо и нужно бежать немедленно чинить, данные могут определенное время продолжать оставаться актуальными. Вы тут скажете, что бэкенд тоже может успешно падать частями, так-то оно так, но я в данном контексте рассматриваю бэкенд и дата-пайплайн как одну логическую сущность, а не набор дублирующих микросервисов и баз с репликациями.
Вот примеры:
Пайплайн отрабатывает каждые 10 минут, а люди смотрят в отчеты, в среднем, раз в час. Падение одной из джоб не критично, да и если источник данных прилег, тут все равно ничего не поделаешь.
Пайплайн стучится в источник с надеждой получить свежие данные, которые появляются в API источника с неопределенной задержкой (привет Apple), пайплан может успешно завершиться как скачав отчет, так и получив сообщение о том, что отчета еще нет. Тут, конечно, можно делать бесконечные ретраи внутри, либо просто ронять пайплайн, но тогда не особо очевидно будет, по какой причине он упал - что-то пошло не так, или данные в источнике еще не подтянулись.
Пайплайн работает слишком долго - это может быть как разовой проблемой из-за тормозов в сети или в источнике, так и постоянной проблемой: что-то сломалось в трансформации, или ретраев стало больше чем нужно, в любом случае требуется вмешательство человека.

И тут вы скажете, но в том же Airflow есть замечательная система мониторинга, которая показывает и время работы джобы, и количество упавших или требующих перезапуска задач, и т.п. И я соглашусь, отчасти...
Чего не хватает во встроенных мониторингах систем работы с данными:
Бизнес не может просто посмотреть в модный мониторинг типа того же Airflow или ELK и понять, можно или нельзя доверять данным, актуальность состояния данных непрозрачна.
Единичные сбои, которые самоустраняются при каждом запуске, отвлекают инженеров, потому что следующий успешный запуск просто восстановит пробелы в данных, если пайплайн имеет правильную архитектуру. Нужно избегать фальшивых алертов, кстати, частично это можно сделать той же графаной.
Нет возможности собрать реальную статистику и проанализировать, где самое слабое место. Просто считать инциденты не вариант, т.к. важнее не количество инцидентов, а время, в течение которого состояние данных было неактуальным. Знаю, что такие проблемы некоторые компании решают самописными парсерами логов или подсчетом пиков-просадок на графиках (напишите, как это реализовано у вас).
Все это превращается в такие вот проблемы:
Обычно мониторинг заточен на отслеживаение проблем в технической части, в то время как куда важнее обнаруживать проблемы в бизнес части.
Люди из бизнеса хотят более наглядного отображения состояния данных и системы, чем оно представлено в технических мониторингах.
Статистика, если и собирается, то собирается по техническим проблемам и нельзя понять, насколько эти технические проблемы повлияли на бизнес.
Концепция
Чтобы решить некоторые из проблем, я написал простую систему мониторинга, прикинув, что идеально было бы получать от процессов события, а затем анализировать их количество, отправленное значение, продолжительность и разные временные интервалы между началом и концом событий. Этот мониторинг, после некоторого тестирования локально, я решил выкатить в паблик, назвав его Sensorpad.

Почему вообще вебхуки?
Ну тут все просто: никто не любит ставить на сервер дополнительный софт, никто не хочет выставлять метрики наружу и настраивать фаерволы, а слать http-запросы могут все. Секьюрити и приватность данных важны всем, а с вебхуками можно скрыть или анонимизировать за кодовым именем даже суть того, как называется ваш процессинг.
После того, как мы начали отсылать из процессов события, нужно их проанализировать и получить ответы на всякие важные вопросы, например (все числа абстрактны):
запустилась ли наша задача 10 раз за последний день?
не превышает ли количество падений (определяем падение, если полученное значение > 0, например) 15% от всех запусков за сегодня?
нет ли процессов, которые длятся больше 20 минут?
не прошло ли больше часа с момента последнего успешного завершения?
стартовало ли событие по планировщику в нужное время?
тут у каждого свои параметры стабильности и после того, как мы проверим их все, останется только визуализировать их и отображать на дашборде, обновляя в режиме реального времени.
Реализация
Я начал с дашборда, дизайн - не моя профессия, так что просто взял за основу дашборд, показывающий состояние крон-джобов на сайте Nomadlist, у меня получилось как-то так:

Каждый монитор на этом дашборде - это комбинация метрик, которые должны быть понятны и бизнесу, и инженерам.
Для примера попробуем настроить мониторинг для чего-то, что понятно даже тем, кто не знаком с дата-инженерингом, например, мониторингом свободного места на диске. Допустим, нам надо показывать дашборд сразу и отделу поддержки, чтобы они знали, когда чистить старые логи, и отделу закупок, чтобы не надеялись на поддержку и сразу заказывали новые диски.

Для инженера тут все понятно:
скрипт отрабатывает быстро (еще бы, простая крон-джоба);
монитор вполне живой, 25 минут назад обновился;
места еще с запасом (цифра 53 в левом нижнем углу - это последнее принятое значение);
Для людей из бизнеса тут тоже все просто:
монитор зеленый;
статус прописан в первой же строчке;
никакой лишней информации;
Вместо размера диска, разумеется, может быть что угодно, начиная от импорта данных из гугл-аналитики, заканчивая мониторингом ревенью компании - суть не меняется.
И насколько просто такое настроить?
Создаем вебхук в самом сервисе, они там называются сенсорами, по аналогии со всякими штуками из физического мира.
Настраиваем крон-джобу на сервере, которая будет отсылать события со значением свободного места в процентах:
df -h |grep vda1 | awk '{ print $5 }'| sed 's/.$//' | xargs -I '{}' curl -G "https://sensorpad.link/<уникальный ID>?value={}" > /dev/null 2>&1Присоединяем к этому вебхуку монитор, называем его: количество свободного места (но можно еще и другие, например, то, что события уходят по графику означает, что сервер не упал)
Настраиваем правила, по которым монитор меняет свой статус.
Присоединяем каналы для отправки уведомлений.
Добавляем монитор на один или несколько дашбордов.
А можно поподробнее?
Для вебхуков я пока что сделал самую простую имплементацию:
базовый вебхук, который будет нужен для 80% проектов;
cron-вебхук, который ожидает события в заданное через cron-синтаксис время;
chain-вебхук, который умеет отслеживать события от процессов, соединенных в цепочки;

После создания попадаем на страницу сенсора, тут автоматически появляются полученные события (повозился в js) и кнопочкой можно отсылать тестовые события, для тех, у кого не установлен Curl или кому лень делать это из браузера:

Дальше создаем тот самый монитор - квадратик, меняющий статус и цвет.

Есть две стратегии для статуса по умолчанию: сказать, что монитор должен быть в статусе "все хорошо", а потом правилами менять его на "что-то пошло не так", или можно сразу сделать ему статус "все плохо", а правилами проверять, что все действительно хорошо - обе стратегии имеют право на жизнь.
Теперь, собственно то, из-за чего я и написал эту балалайку: правила и гибкая логика.
К каждому монитору можно прицепить определенное количество правил, дальше движок мониторинга проверяет все правила раз в пару секунд. Правила проверяются поочередно, как только одно из правил вернет значение True, статус монитора изменится и остальные правила проверяться не будут. Если никакое из правил не сработало, статус монитора примет значение по умолчанию - то самое, которое задавалось при создании монитора.

На скриншоте выше видно уже созданные правила, но я покажу как они создаются.
Например правило, которое можно сформулировать так: "установи статус Warning, если за последний день было больше 5 джоб, которые работали дольше 10 секунд".

А вот какие вообще можно выбирать проверки в каждом из пунктов:
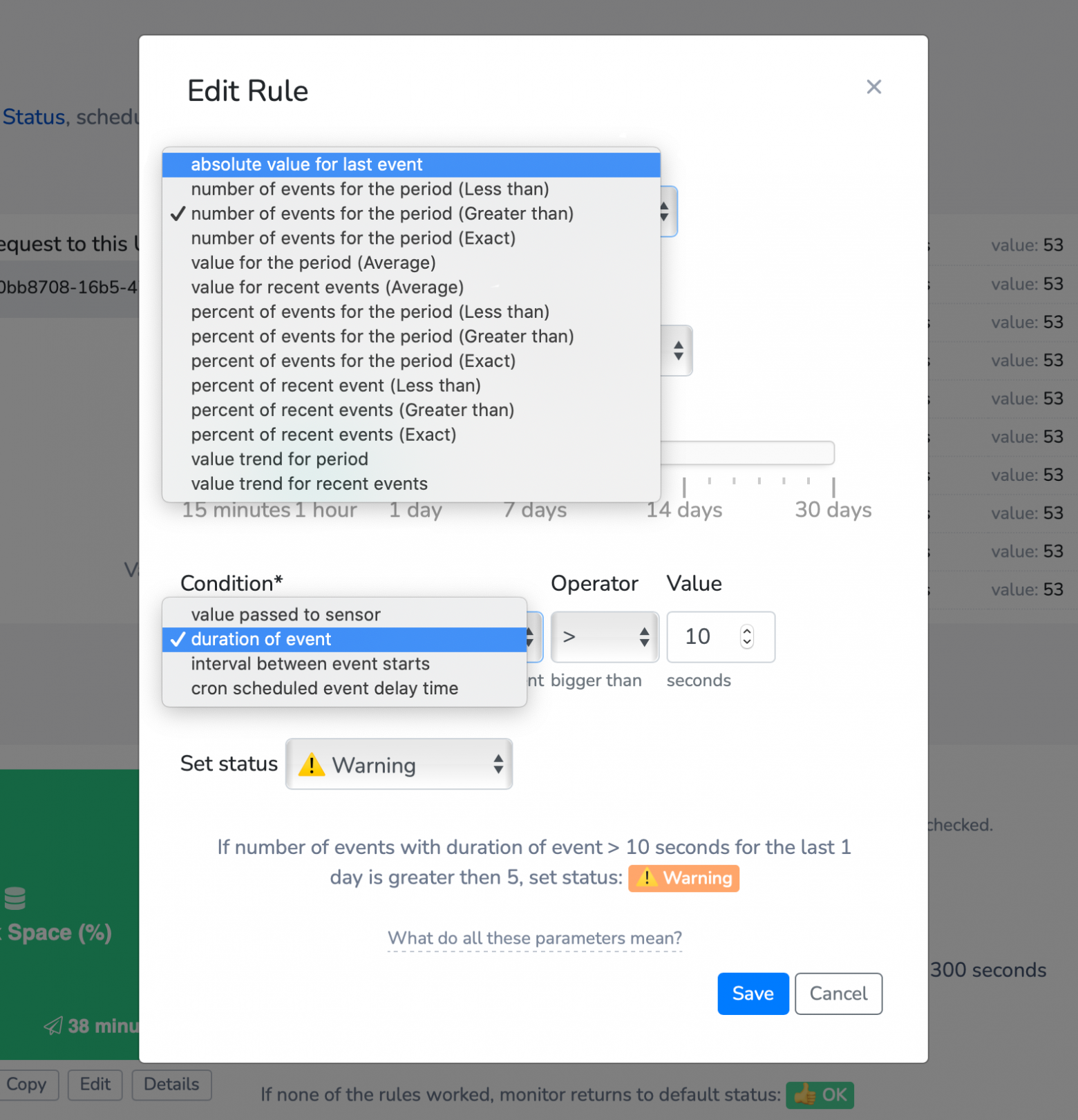
И какие реальные кейсы можно покрыть этими правилами?
У каждого свои кейсы. Дата-инженерия вообще весьма специфичное для каждой компании направление. Если у вас есть дата-пайплайны или cron jobs, сервис оповестит вас, если (все цифры, разумеется, конфигурируемы):
Cron job, Airflow DAG или любой другой процесс не запустился по расписанию;
20% задач одного и того же пайплайна за день не отработали как надо;
связанная задача в пайплайне не запустилась через 2 минуты после окончания родительской задачи;
интервал между запусками двух задач меньше 1 минуты (похоже, у нас две конкурентные джобы);
с момента последнего успешного завершения пайплайна прошло 2 часа (а данные должны считаться каждый час);
время работы пайплайна уже целых 20 минут (а должен был отработать за 5, что-то подвисло).
Это те идеи, которые могли бы использоваться в практически любой, полагаю, компании.
А теперь - статистика!
Красивые графики любят все. Крутость sensorpad в том, что он показывает в статистике реальные состояния систем, а не просто количество уведомлений (их, кстати, тоже показывает). А уже с этими данными можно разгуляться: и самому поковырять, чтобы понять во что вложить силы и что нужно оптимизировать, да и стейкхолдерам не грех показать идеально зеленый график.

Я подумываю допилить возможность шарить эти странички по секретной ссылке за пределы аккаунта, тогда такую страницу можно будет использовать не хуже любой status page.
Вот такой концепт. Чего не хватает?
Sensorpad - проект выходного дня, который делался в свободное от основной работы время, без тонны инвестиций да еще и в одно лицо, именно поэтому мне так важно мнение комьюнити: как вам? Что добавить, что улучшить, продолжать ли развивать?
Потыкайте его вживую, заодно зацените, какой я у мамы дизайнер лендингов: https://sensorpad.io

