❓Как проектировать системы, которые будут толерантными для различного вида отказов и ошибок?
Что такое отказоустойчивость и стабильность?
Под отказоустойчивостью будем понимать свойство системы, которое позволяет максимально сохранять работоспособность при отказе отдельных конкретных компонентов системы либо связанных систем и восстанавливать работоспособность системы при восстановлении отказавших компонентов или связанных систем. Давайте рассмотрим подробнее эти 2 момента:
Деградация работоспособности системы должна быть прямо пропорциональна "величине" отказа. То есть, если упал сервис, отвечающий за некую некритичную функциональность — вся система не должна при этом падать. Да, небольшой кусочек не работает, но это не влияет на стабильность остальной части функционала.
Стабильность системы предполагает самостоятельного восстановления работоспособности после сбоя как компонентов системы, так и всей системы в целом. К примеру, если пропадала сеть на некоторое время — то у стабильных систем после восстановления подключения все компоненты продолжат работать и данные вернутся в консистентное состояние без ручного вмешательства со стороны команды эксплуатации.
Наглядно разницу между отказоустойчивыми и неотказоустойчивыми системами представим следующим образом:
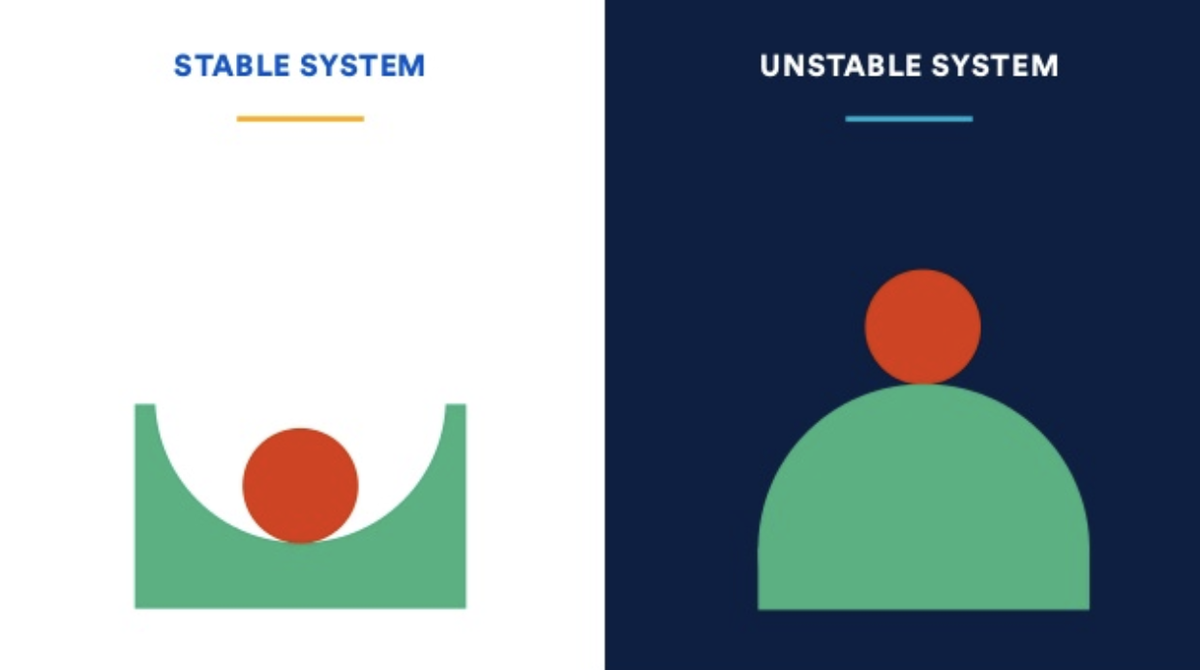
Если в стабильной системе из нормального состояния равновесия шарик в центре чуть-чуть подтолкнём в сторону — он, конечно же, ненадолго отклонится от равновесия (т.е. система перейдёт в некоторое неидеальное состояние), но после этого шарик быстро вернётся в нормальное состояние. В случае же плохо спроектированных и построенных систем — даже лёгкого воздействия на шарик достаточно, чтобы система начала деградировать с нарастающей скоростью. При этом сам по себе шарик не вернётся в нормальное состояние в таких системах.
❓Но как же определить является ли наша система отказоустойчивой и стабильной? И на сколько? Как в идеале замерить эти свойства, чтобы двигаться к цели согласно некой метрике, а не наощупь?
Единственный способ спроектировать систему, которая будет устойчива к сбоям — проводить стресс-тесты (resilience testing / chaos engineering), по результатам тестов делать выводы, менять архитектуру и подходы к написанию кода, снова запускать тест... и так до бесконечности :)
Количество пройденных тестов и будет метрикой отказоустойчивости отдельных компонентов и системы в целом. Только на основе метрики делаем вывод о повышении или понижении стабильности системы.
Создание таких тестов — уже непростая инженерная задача. Для начала необходимо описать и автоматизировать сценарии отказа (легла сеть, закончилось место на диске, внешний сервис отвечает ошибками, сеть тормозит или доставляет только 50% пакетов, выключилось электричество на конкретном физическом хосте или во всё дата-центре и т.д.) — а потом запускать их в произвольном порядке, да и ещё и в случайных комбинациях друг с другом ??. Тесты позволят нам и получить измеримую метрику (прошли 10 тестов из 50), и понять какие отказы наиболее критичны, т.к. сразу же приводят к краху всей системы.
Принципы построения отказоустойчивых систем
Отсутствие единой точки отказа (No SPoF (Single Point of Failure))
Принцип применим ко всем уровням эксплуатации — от точки деплоя (любой Nginx или микросервис в системе) до уровня дата центров. Рассмотрим этот принцип на примерах репликации и балансировки небольших компонентов системы:

Для его реализации сервисы должны быть готовы к запуску в нескольких экземплярах — как минимум не должны хранить состояния (быть stateless-сервисами). Давайте рассмотрим обратный пример, когда у нас сервис хранит состояние и неготов к горизонтальному масштабированию. Пусть в нашей схеме сессия пользоавтеля хранится на самом бэкендовском сервисе:

Пока Backend работал в единственном экземпляре — всё было хорошо, но после горизонтального масштабирования до двух экземпляров в случае простой балансировки запрос авторизованного в одном сервисе пользователя рано или поздно попадёт на Backend, где нет нужной сессии.
В данном случае для подготовки сервиса к горизонтальному масштабированию можем, к примеру, вынести сессии в отдельное хранилище, например Redis:

❓Но что же делать с компонентами, которые хранят состояния (т.н. stateful-сервисы, у нас это БД и Redis) или не могут быть запущены во множеством экземпляре (к примеру, если сеть поддерживает направление траффика только на один Balancer)?
Хранилища обычно реплицируются по схеме мастер-реплика (естественно, в нашем примере все сессии пользователей будут хранится на всех Redis'ах). В случае отказа мастера — реплика автоматически становится новым мастером и все потребители переключаются на неё. Такая же схема используется и для stateless-сервисов, которые не могут быть запущены в нескольких экземплярах: поднимаются несколько экземпляров stateless-сервисов, но траффик идёт только на один из них. В случае отказа главного экземпляра, происходит автоматическое переключение на запасной.
Ещё один пример stateless-сервиса, реплецированного но работающего в единственном экземпляре — это сервис последовательной синхронной записи (Writer):

Проектирование с учётом отказов (Design for Failure)
В любой системе происходят отказы и падения, поэтому важно уже на этапе проектирования архитектуры держать в уме, моделировать и закладывать обработку нештатных ситуаций. Рассмотрим основные базовые идеи концепции:
? Постепенная деградация (Graceful degradation) — это возможность частично деградировать функционала системы в случае отсутствия/неработоспособности её компонентов. Рассмотрим на схеме вариант построения системы с последовательной связанностью и полной деградацией при отказе:

Если же мы чуть иначе перераспределим зависимости, то получим лишь частичную потерю функциональности:

Другой вариант частичной деградации — потеря или отложенное предоставление некритичных данных. Например, мы можем показать позже срок доставки товара (или не показывать вовсе) в случае проблем с компонентом расчета доставки, при этом вся остальная информация и возможность купить будут доступны:

В худшем варианте, если некий BFF или API Gateway дожидается синхронного ответа от каждого компонента и только потом отдаёт результирующий html — страница отобразится пользователю только после отрабатывания самого медленного компонента (или суммы времени всех, если запросы строятся ещё и последовательно, а не параллельно). При падении одного из компонентов (например, не самого важного раздела с похожими товарами) в нетолерантном к отказам варианте проектирования пользователь бы в принципе ничего не увидел кроме страницы с ошибкой.
ℹ️ Помимо отложенной доставки или потери данных, в случае их критичности — можем деградировать в их актуальности взамен полного отсутствия при помощи кэширования. К примеру, если источник актуальных данных недоступен — берём предсохранённые данные из кэша: в зависимости от сценария, тут может быть как частичная деградация (актуальные данные лучше старых, но старые лучше их отсутствия) так и отсутствие деградации вовсе (пусть в 99% случаев закэшированные данные соответствуют актуальным).
? Умри быстро (Fail fast) — быстрое выявление проблемного сервиса/запроса и их отстрел (самостоятельный или внешний). Схожий принцип — "мёртвые программы не лгут". На первый взгляд кажется нелогичным, что сервису лучше "умереть" (и в идеале перезапуститься), чем даже на относительно недолго зависнуть — давайте разбираться на примере. Вернёмся к нашему stateless-сервису записи, который должен работать только в единственном экземпляре:

Если основной работающий экземпляр сервиса Writer зависнет, но не упадёт или выдаст ошибку — то при отсутствии таймаута на балансере не произойдёт автоматического переключения на запасной экземпляр сервиса и система свалится в отказ. Лучшим вариантом в большинстве случаев будет упасть или выдать ошибку, извещая тем самым балансер и потребителя о неуспехе.
? История из жизни. После очередного релиза резко утяжелился запрос в БД для далеко не самой основной функциональности. Когда один из пользователей таки добрался до данной функциональности — уходил тяжелый запрос в БД, с которым БД честно пыталась справится на протяжении долгих минут, потребляя много ресурсов железа. Для пользователя это выглядело так, что при заходе на страницу ничего не происходит. Что при этом мы обычно делаем? Правильно! Пробуем ещё раз ?и ещё, и ещё. Каждый раз при этом на БД падали ещё и ещё точно такие же тяжёлые запросы при том что исполнение предыдущих никто не отменял. Достаточно быстро серверная часть стала настолько загруженной параллельным выполнением одного и того же тяжелого запроса, что тормозить и неотвечать стали любые, даже лёгкие запросы. Собственно в этот момент и началась паника, и команде эксплуатации открылась картина, что тормозит вообще всё — пойди ещё разберись что являлось первопричиной проблемы..
? Мораль: реализация быстрой смерти (например, по таймауту) спасла бы систему от лавинообразной деградации. Попытка выполнить долгий тяжелый запрос должна обрубаться и по таймауту, и по отмене с вызывающей стороны (уход или обновление страницы до ожидания её загрузки). Для пользователя сообщение об ошибке так же более прозрачно, чем зависание в виде бесконечной загрузки.
Разделение ресурсов (resources segregation)
Рассмотирм два типа разделения:
Квотирование для каждого потребителя. Примером тут может быть ограничение количество запросов к API за единицу времени для каждого потребителя (по его API-ключу) — допустим сервис позволяет каждому из потребителей с типом ключа public совершать не больше 100 запросов к API в минуту, а с типом internal — до 1000. Квотирование позволяет не допустить отказа сервиса для всех потребителей из-за умышленного или неумышленного DDoS'а со стороны единственного потребителя.
Разделение по доступности физических ресурсов (CPU, RAM, ...). Суть в строгом лимитировании максимально возможного потребления ресурсом одним сервисом (контейнером). Оркестратор контейнеров (например, Kubernetes) не должен безгранично выдавать запрашиваемые ресурсы конкретному контейнеру, даже если на физическом хосте есть свободные ядра процессора/оперативная память и т.д. Проблема перегрузки в единственном контейнере никак не должна влиять на соседние контейнеры и весь хост в целом.
 в одном из отсеков (сервисов) мы должны ограничить проблему объёмом единственного отсека (максимальной выделенной памятью для сервиса).")
Умная балансировка (Weighted load balancing)
Согласно этому принципу нагрузка балансируется в зависимости от загруженности экземпляра сервиса и/или его времени ответа. Например, чем сильнее время ответа экземпляра сервиса превышает заданные показатели в SLO — тем меньше трафика посылает на него балансировщик. И наоборот — сервис справился со своей нагрузкой — пускаем на него больше трафика. Ранжирование должно быть динамическим и может учитывать разные факторы (время ответа, загрузка CPU, количество "тяжелых" запросов в обработке, сравнительные показатели между экземплярами под балансировкой и т.д.). Подробно принцип описан в гугловской книге по SRE.
Ассинхронное взаимодействие
Суть принципа в замене синхронных (читай менее отказоустойчивых) зависимостей (в первую очередь между системами) на асинхронное. Рассмотрим на всё том же примере отображения срока доставки на странице товара интернет-магазина.

Повысить отказоустойчивость и снизить уровень внешней связанности позволит переход на ассинхронную зависимость через очередь сообщений:

По возможности на асинхронный тип взаимодействия лучше перевести все интеграции между системами — в нашем примере это означает подписку на события изменений и кэширование в собственном контуре всех интересующих систему страницы товара данных (фотографии, отзывы, цены и т.д.). Кэшировать стóит не целиком канонические версии объектов или событий (дублируя при этом мастер-систему), а только интересующую нашу систему часть данных. При таком подходе (т.е. при отсутствии синхронных внешних связей) получаем замкнутый контур, влияющий на отказоустойчивость системы. В изолированном собственном замкнутом контуре системы проще работать над наращиванием отказоустойчивости и организационно (не зависим от соседних команд) и технически.
Шаблоны и практики
Автоматический выключатель (Circuit Breaker)
Этот паттерн обычно используют взамен классической стратегии простых повторов (Retry) запроса в случае неуспеха, ставшей антипаттерном. Простой повтор запроса имеет смысл далеко не во всех случаях: к примеру, если БД отвечает ошибкой о несовпадении типа поля — повторный аналогичный запрос её не исправит. Автоматические повторы могут пригодится, к примеру, в случае проблем с сетью — в идеале их переложить на уровень инфраструктуры и в любом случае ограничить по времени и количеству. Но вернёмся к Circuit Breaker'у:

Тем самым Circuit Breaker "из коробки" реализует идею Fail fast сразу же отвечая потребителям о проблеме (после детекции проблемы новые запросы сразу же будут падать с ошибкой даже без обращения к проблемному сервису). Не менее важно, что Circuit Breaker таким образом не допускает DDoS'а сервиса, которому итак плохо (в случае слепых повторов запросов от потребителей проблемный сервис так и не сможет подняться под напором нагрузки, либо будет делать это значительно дольше). Для возобновления работоспособности Circuit Breaker периодически пропускает часть трафика на проблемный сервис и в зависимости от результата либо оставляет связь "выключенной" для большинства запросов, либо её включает. Нет смысла пропускать 100 пришедших запросов на проблемный сервис — можно пропустить один в диагностических целях и в случае сохранения проблем ответить ошибкой уже всей сотне.
Толерантный читатель (Tolerant Reader)
В распределенных системах именно контракты интеграций играют связующую роль, из-за чего изменения в контрактах — в общем случае процесс нетривиальный. Часть проблем при эволюции контрактов снимается, если потребители максимально возможно толерантны к изменениям в контрактах. К примеру, потребитель контракта не должен падать, если в нём добавилось новое поле или исчезло необязательное поле. В таком случае читателю перейти на новую версию контракта можно будет постепенно при необходимости, а владельцу контракта — проще его развивать и модифицировать. Также снизится количество падений при несогласованных или ошибочных изменениях в контрактах или данных, т.е. потребители контрактов будут более стабильны.
Умный сервер / умный клиент
В силу особенностей конкретных архитектур и реализации интеграций в общем случае может не оказаться возможным встроить гибкую схему балансировки и Circuit Breaker'а. В этом случае к примеру на стороне сервера/сервиса можно реализовать самодиагностику (о перегруженности) и варианты мгновенного отказа (отказа новым запросам как в Circuit Breaker'е или даже полный рестарт самого себя). Балансировку же можно вынести на сторону клиента (Client Side Load Balancer), которую иногда целесообразно применять даже если возможна серверная балансировка.
Динамические параметры поведения системы
Система должна быть гибкой и подстраивающейся под текущую нагрузку.
В высоконагруженных частях системы лучше избегать жёстких значений в стратегиях повышения отказоустойчивости. К примеру, мы не фиксируем константой количество повторных запросов и/или частоту диагностических запросов Circuit Breaker'а, а ограничиваем 10ю процентами долю таких запросов в общем трафике. Таким образом, добиваемся схожего поведения системы в случае отказов как при высокой, так и при низкой нагрузке. Если сконфигурировать систему только под высокую нагрузку — можно, например, пропустить серьёзную проблему и не получить алертов, когда при низкой нагрузке всё работает, но 50% запросов приходится дублировать.
Нагрузочное и стресс тестирование
Если стресс-тестирование (Resilience testing), как и писал в начале статьи, даёт метрику отказоустойчивости и стабильности системы, то нагрузочное тестирование — показывает границы нашей отказоустойчивости. Т.е. система может быть стабильна, но не выдерживать высоких нагрузок, и наоборот — система держит высокие нагрузки, но не устойчива к отказам (например, к отказу оборудования). Хочется отдельно отметить, что нагрузочное тестирование — это не всегда только про высокий RPS и большое количество пользователей. Для многих систем не менее важно проводить нагрузочные тесты по объёму данных (к примеру: пользователей немного, но БД может вырасти до терабайтов; обычно файлы на входе не превышают пары мегабайт, но мы должны обрабатывать и гигабайтные).
Подводя итог, ещё раз повторюсь, что если мы пережили все "детские болезни" в нашем проекте, то дальше наращивать стабильность, на мой взгляд, можно только измеряя, визуализируя и отслеживая динамику метрик по нагрузке и отказоустойчивости. Без моделирования ситуаций отказов — не предугадаешь, как то или иное архитектурное, инфраструктурное или техническое решение повлияет на поведение сложной системы в момент кризиса.
Всем ❤️









